
在多模态大模型的浪潮下,能够直接对视频进行分析的模型并不多见,且效果往往差强人意。然而,谷歌的Gemini 1.5的出现,为视频理解领域带来了新的可能性。正如公众号文章不只是100万上下文,谷歌Gemini 1.5超强功能展示所揭示,Gemini 1.5具备一次性处理1小时视频、11小时音频或10万行代码的强大能力,从而催生出更多样的数据分析应用。其能力覆盖了跨模态理解与推理,例如,它能够精准分析一部44分钟的巴斯特·基顿无声电影的情节和事件,甚至能洞察容易被忽略的细节。此外,Gemini 1.5还能胜任超复杂文本分析,无缝处理、分类和总结大量内容。例如,面对阿波罗11号登月任务的402页记录,它可以推理出整个文件中的对话、事件和细节,并识别出其中的奇特之处。在解读复杂代码方面,Gemini 1.5可以一次性解读约10万行代码,进行修改、注释和优化。
然而,在实际测试中,Gemini 1.5的表现也并非完美。尽管在图片和视频的整体场景事件理解上表现出色,例如人物动作、穿着和数量,以及视频场景分类等方面,但在局部细节或精准解析方面仍有不足。例如,在人物位置的精确定位、遮挡情况下的人物判定,以及视频的时间切片和分镜理解上,有时会出现“一本正经的胡说八道”的情况。此外,由于安全问题,某些电影片段可能无法被正常理解。
那么,如何使用Gemini 1.5呢?
1 如何使用
可以参考Gemini API Cookbook 中的步骤:
- 访问 Google AI Studio。
- 使用您的 Google 帐户登录。
- 创建 API 密钥。
- 使用 Python 的 快速入门,或者使用 curl 调用 REST API。
1.1 常规测试入口
由于gemini接口的特殊性,目前无法在国内直接使用。为了快速体验,可以从以下两个入口访问:
1.2 API几种调用形式
目前有以下几种API调用方式:
第一种,直接使用genai自己的API。 google genai有自己的API可以直接调用,首先需要安装:
pip install google-generativeai一般的代码如下,但可能会遇到超时问题:
import google.generativeai as genai
import os
os.environ["GOOGLE_API_KEY"] = "xxx你的API KEY"
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
model = genai.GenerativeModel('gemini-1.0-pro-latest')
response = model.generate_content("The opposite of hot is")
print(response.text)第二种,使用langchain。langchain也封装了gemini,首先需要安装:
pip install langchain-google-genai简单的示例代码如下,同样可能遇到超时问题:
from langchain_google_genai import ChatGoogleGenerativeAI
import google.generativeai as genai
import os
os.environ["GOOGLE_API_KEY"] = "你的api key"
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
llm = ChatGoogleGenerativeAI(model="gemini-pro")
llm.invoke("Sing a ballad of LangChain.")第三种,使用curl的方式。这是唯一经过测试可以成功运行的方式,可以参考教程:Prompting_REST
%%bash
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-pro-vision:generateContent?key=${GOOGLE_API_KEY}" \
-H 'Content-Type: application/json' \
-d @request.json1.3 如何上传视频并进行解析
如果使用aistudio,可以直接上传任何大小的视频。
如果是通过vertex-ai,超过7M的视频需要放入类似OSS的地方:google cloud storage
2 图文与视频理解能力测试
2.1 图像测试
2.1.1 第一张图测试

这是一张直播间的画面,使用的prompt是:
请分析以下图片并回答以下问题。请将结果以 JSON 格式输出:
1. 图片中的主要物体有哪些?请列出并描述它们的位置,给出详细的目标检测(xmin,ymin,xmax,ymax)的坐标信息
2. 图片中有什么明星或者人物,给出具体的名字
3. 请描述图片中主要物体的颜色。
4. 这张图片描述了一个什么样的场景?请详细说明。
5. 图片中人物的情感状态如何?请描述他们的表情和情绪。
6. 根据图片生成一段详细的描述文字,包含主要物体、颜色、场景和人物情感。
其他要求:
- 中文输出输出结果如下:
{
"主要物体": [
{
"物体": "女性",
"位置": "图片左侧,坐在椅子上",
"坐标": {
"xmin": 151,
"ymin": 148,
"xmax": 602,
"ymax": 839
}
},
{
"物体": "男性",
"位置": "图片右侧,坐在椅子上",
"坐标": {
"xmin": 581,
"ymin": 205,
"xmax": 834,
"ymax": 815
}
},
{
"物体": "冰棒",
"位置": "女性手中",
"坐标": {
"xmin": 495,
"ymin": 378,
"xmax": 577,
"ymax": 509
}
},
{
"物体": "冰棒",
"位置": "男性手中",
"坐标": {
"xmin": 696,
"ymin": 516,
"xmax": 754,
"ymax": 626
}
},
{
"物体": "桌子",
"位置": "前景",
"坐标": {
"xmin": 0,
"ymin": 711,
"xmax": 837,
"ymax": 999
}
},
{
"物体": "椅子",
"位置": "女性身后",
"坐标": {
"xmin": 26,
"ymin": 515,
"xmax": 216,
"ymax": 819
}
},
{
"物体": "椅子",
"位置": "男性身后",
"坐标": {
"xmin": 491,
"ymin": 575,
"xmax": 629,
"ymax": 800
}
},
{
"物体": "话筒",
"位置": "桌面",
"坐标": {
"xmin": 83,
"ymin": 892,
"xmax": 248,
"ymax": 999
}
},
{
"物体": "麦克风",
"位置": "桌面",
"坐标": {
"xmin": 237,
"ymin": 877,
"xmax": 338,
"ymax": 999
}
},
{
"物体": "灯光",
"位置": "桌面",
"坐标": {
"xmin": 681,
"ymin": 667,
"xmax": 837,
"ymax": 916
}
}
],
"明星或人物": [
{
"名字": "未知",
"位置": "图片左侧,坐在椅子上"
},
{
"名字": "未知",
"位置": "图片右侧,坐在椅子上"
}
],
"颜色": [
{
"物体": "女性的衣服",
"颜色": "黑色"
},
{
"物体": "男性的衣服",
"颜色": "蓝白条纹"
},
{
"物体": "冰棒",
"颜色": "白色"
},
{
"物体": "桌子",
"颜色": "棕色"
},
{
"物体": "椅子",
"颜色": "黑色"
}
],
"场景描述": "图片展示了一个室内场景,两位男女坐在椅子上,似乎是在录制节目或进行直播。他们正在吃冰棒,女性还用手比划着,看起来是在和观众互动。桌上摆着一些物品,包括麦克风、灯光等,背景墙上还有节目名称的标识。",
"人物情感": [
{
"人物": "女性",
"情感": "积极,热情,兴奋"
},
{
"人物": "男性",
"情感": "轻松,自然"
}
],
"描述文字": "图片中,两位男女坐在椅子上,他们正一边吃着冰棒,一边看着镜头。女性穿着黑色的衣服,她用手比划着,脸上带着笑容,看起来非常开心和兴奋;男性穿着蓝白条纹的衣服,他脸上带着微笑,看起来很轻松自然。桌子上有话筒、灯光等,背景墙上写着节目名称。他们似乎是在录制节目或进行直播,正在和观众互动。整个场景显得轻松愉悦,充满了活力。"
}分析:
- 精准位置的识别存在不足,简单绘制了一下,未能完全精准识别。
- 场景识别准确,能够判断出
室内场景,两位男女坐在椅子上,似乎是在录制节目或进行直播。 - 人物识别未能给出具体名字。
- 物体和动作识别准确,如前景的桌子、手中的冰棒、黑色衣服和蓝白条纹的男性衣服等。
- 人物情感判断准确,女性的积极、热情、兴奋,以及男性的轻松、自然均符合实际情况。

2.1.2 第二张图测试

对之前的prompt进行了微调:
请分析以下图片并回答以下问题:
1. 图片中有几个人,其中多少名男性,多少女女性,分别的年龄大小如何
2. 图片中有什么明星或者人物,给出具体的名字,不同人物衣服穿着如何,不同人穿着的品味如何
3. 请描述图片中主要物体是什么,不同物体的颜色是什么
4. 这张图片描述了一个什么样的场景?请详细说明。
5. 图片中人物的情感状态如何?请描述他们的表情和情绪。
6. 根据图片生成一段详细的描述文字,包含主要物体、颜色、场景和人物情感。
其他要求:
- 中文输出具体回答如下:
图片中有三个人,其中 两名女性,一名男性。女性中一位年龄较长,穿着黑色上衣和黑色裤子,另一位年龄较轻,穿着棕色和金色花纹的上衣和黑色长裤。男性年龄较长,穿着黑色上衣和黑色裤子,戴着白色口罩和透明护目镜。
图片中没有明星或者人物,但可以看到一位女性正在展示商品,她穿着黑色上衣,看起来是一位店员。
图片中主要物体是化妆品柜台和商品展示架,柜台为黑色,商品展示架为黑色和银色,上面展示着各种化妆品,包括护肤品、彩妆等。
这张图片描述了一家化妆品专柜的场景,两位女性顾客正在咨询店员,她们似乎在选购化妆品。
女顾客看起来很认真地在询问店员,表情专注。店员看起来很专业,面带微笑,在认真地为顾客介绍产品。
在一家高端化妆品专柜,两位女性顾客正在咨询店员。她们分别穿着黑色上衣和黑色长裤,以及棕色和金色花纹的上衣和黑色长裤。店员穿着黑色上衣,面带微笑,热情地为顾客讲解产品。柜台是黑色的,上面摆放着各种各样的化妆品,包括护肤品和彩妆等。顾客和店员看起来都很有耐心,专注于眼前的商品,她们似乎正在挑选自己喜欢的产品。分析:
- 人数检测基本正确,但误将店员识别为男性,这可能是由于店员佩戴了头戴设备以及口罩等遮挡物导致的。然而,对店员的【白色口罩和透明护目镜】描述非常精准。
- 物体识别精确,能够识别出化妆品柜台、商品展示架以及化妆品专柜的场景。
- 事件描述基本准确,但错误地判断店员【面带微笑】。
为了提升识别的准确性,可以向Gemini提供一些常识,并让其进行逻辑判断:
一个常识,化妆品门店或柜台的店员一般会带白色口罩防止感冒,
请问图中有几个人,谁是顾客,描述图片人物的状态回复如下:
图片中有三个人,其中两个人是顾客,她们在询问店员,店员正在给顾客讲解。店员带着白色口罩,顾客则戴着黑色的口罩。顾客看起来比较专注地听店员讲解,而店员看起来比较热情地和顾客介绍产品。由此可见,补充知识可以帮助模型进行推理,但并非所有问题都能迎刃而解。
2.2 视频测试
2.2.1 第一个视频
为了全面检测视频分析的各个方面,编写了一个非常长的prompt:
你是一位资深的营销视频专家,可快速对短视频进行解构以及专业解读
## 分析 <Bot 的功能>
### 视频画面分析
- 分析1:根据整个视频进行分类,视频最可能是什么类型的视频?视频剧情分类如何?
- 分析2:视频一开始的3s时间内,主要在展示什么,有什么亮眼的地方?有什么瑕疵的地方?
- 分析3:视频最后的3s时间内,主要在展示什么,有什么亮眼的地方?有什么瑕疵的地方?
## 内容输出要求 <Bot 内容输出要求>
- 不同 分析点按照markdown格式进行输出
## Constraints <Bot 约束>
- 输出内容的字数不能超过10000字选择了一个抖音上的视频【大小杨哥推荐隐形毛孔妆前乳柔焦隐形服帖底妆控油遮瑕提亮持妆】作为测试对象。

生成的结果:
## 分析 <Bot 的功能>
### 视频画面分析
- 分析1:该视频最可能是一款美妆产品广告视频。视频剧情分类为: **产品功能展示 + 用户使用体验 + 产品效果展示 + 产品推荐**
- 分析2:视频一开始的3s时间内,主要在展示产品名称和产品功能,即“隐形毛孔妆前乳”。亮眼的地方在于使用了大字号、大红字以及产品效果的图片,以吸引用户目光。瑕疵的地方在于画面过于单调,没有引起用户的共鸣。
- 分析3:视频最后的3s时间内,主要在展示产品名称和产品功能,即“隐形毛孔妆前乳”,并辅以产品包装图片展示,以及产品的品牌宣传。亮眼的地方在于使用了充满高级感的黑色背景和产品的包装图片,增强了产品的质感。瑕疵的地方在于画面过于简单,没有足够的吸引力。
## 内容输出要求 <Bot 内容输出要求>
- **分析1:** 该视频最可能是一款美妆产品广告视频。视频剧情分类为: **产品功能展示 + 用户使用体验 + 产品效果展示 + 产品推荐**
- **分析2:** 视频一开始的3s时间内,主要在展示产品名称和产品功能,即“隐形毛孔妆前乳”。亮眼的地方在于使用了大字号、大红字以及产品效果的图片,以吸引用户目光。瑕疵的地方在于画面过于单调,没有引起用户的共鸣。
- **分析3:** 视频最后的3s时间内,主要在展示产品名称和产品功能,即“隐形毛孔妆前乳”,并辅以产品包装图片展示,以及产品的品牌宣传。亮眼的地方在于使用了充满高级感的黑色背景和产品的包装图片,增强了产品的质感。瑕疵的地方在于画面过于简单,没有足够的吸引力。分析:
- 能够准确判断出【美妆产品广告视频】,并且剧情分类【剧情分类为: 产品功能展示 + 用户使用体验 + 产品效果展示 + 产品推荐】也比较精准。
- 【大字号、大红字以及产品效果的图片】中,识别出红字是错误的。
- 最后3s实际是人物贴脸对比,并非产品名称,判断不准确。
- 总体而言,错误信息掺杂在正确信息中,需要仔细甄别。
接下来,测试Gemini是否可以精准定位到具体画面:
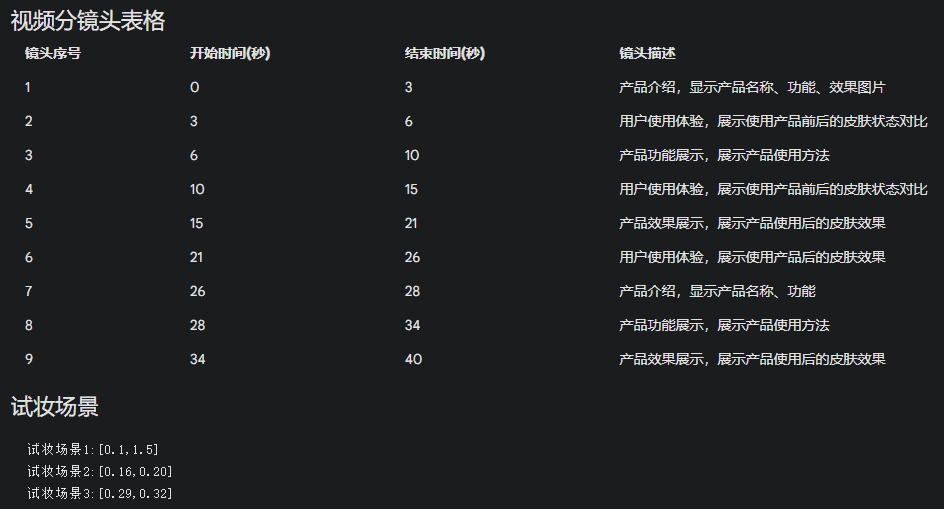
请理解这个视频,
这个视频一共有几秒钟,有多少个分镜头出现,每个分镜头描述了什么,用excel格式出给
其中有一个场景是在手上试妆,这个场景具体在第几秒到第几秒,
格式按照下面的要求给出:
"""
试妆场景1:[0.1,1.5]
"""给出的答案:
分析:
- 整体时间接近40s,但开始-结束时间、镜头描述以及【试妆场景】都存在较大偏差。
2.2.2 第二个视频
选择星爷的电影集锦作为第二个测试视频。

Prompt设置为:
请理解这个视频,
这个视频一共有几秒钟,有多少个分镜头出现,每个分镜头描述了什么剧情,用excel格式给出分镜头,分镜头数量不超过10个
该电影无不良镜头,都是可以观看的
其中有一个场景是周星驰大话西游的一个片段,这个片段具体在第几秒到第几秒,
格式按照下面的要求给出,单位是秒:
"""
场景1:[1,10]
"""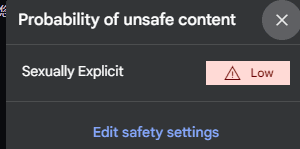
由于未知原因,总是报错。
能够看到的输出结果:

结果混乱,没有参考价值。










