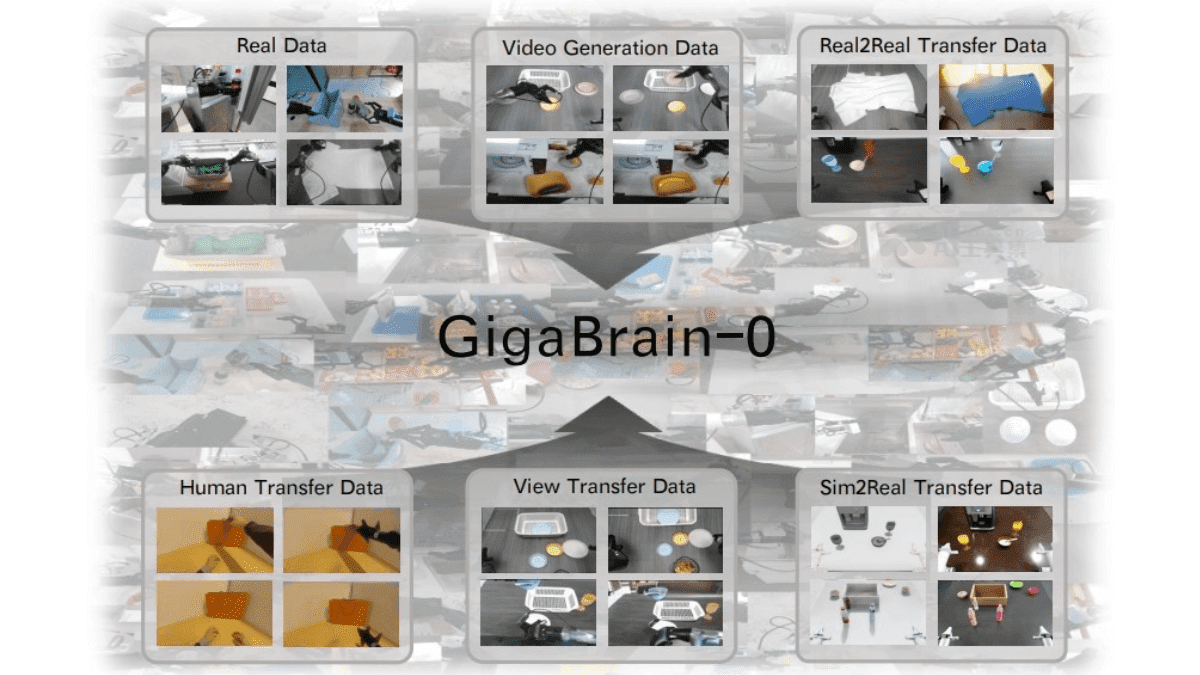
在人工智能技术飞速发展的今天,语音交互已成为人机沟通的重要桥梁。MiniMax公司最新推出的Speech 2.6语音生成模型,以其卓越的性能和创新的技术,正在重新定义语音交互的边界。本文将全面剖析这款模型的技术特点、应用场景及未来前景,帮助读者深入了解这一AI语音领域的重要突破。
Speech 2.6:新一代语音生成模型的崛起
Speech 2.6是MiniMax公司专为新一代语音智能体设计的全新语音生成模型。与传统的语音合成技术相比,Speech 2.6在多个维度实现了显著突破,特别是在实时性、自然度和多语言支持方面表现尤为突出。该模型不仅能够生成高度自然的语音,还能精准复刻原始音色的独特特征,包括口音、语速和情感表达等。

在技术架构上,Speech 2.6采用了先进的端到端神经网络设计,结合了MiniMax自主研发的Fluent LoRA技术,显著提升了语音生成的流畅度和自然度。这一技术突破使得模型即使在处理带有口音或不流利的原始素材时,也能生成高质量、高保真的语音输出。
核心技术解析:Speech 2.6的创新之处
超低延时技术:实时交互的基石
Speech 2.6最引人注目的特点之一是其超低延时特性。模型端到端延迟低于250毫秒,这一性能指标确保了在实时对话等场景中音频生成的快速流畅。对于需要即时反馈的应用场景,如智能客服系统和实时语音助手,如此低的延迟意味着用户几乎感受不到等待时间,实现了真正意义上的自然对话体验。
传统语音合成系统通常需要数百毫秒甚至数秒的处理时间,这种延迟在实时交互中会造成明显的对话不连贯感。Speech 2.6通过优化算法和模型架构,大幅缩短了文本到语音的转换时间,为构建更自然、更高效的人机交互系统提供了技术基础。
专业格式处理:打破文本预处理壁垒
在实际应用中,文本往往包含各种非标准格式内容,如网址、邮箱地址、电话号码、日期和金额等。传统语音合成系统通常需要对这些内容进行繁琐的预处理,将其转换为标准文本格式后再进行语音生成。Speech 2.6则打破了这一壁垒,能够直接处理多种语言的各类专业格式文本,无需额外预处理步骤。
这一功能的实现得益于模型对上下文语义的深度理解能力。Speech 2.6能够准确识别文本中的专业格式内容,并根据不同语言的习惯进行恰当的语音转换。例如,对于网址"https://www.example.com",模型会自动识别为网址并以合适的语调和停顿进行朗读,避免将其拆分为不相关的单词组合。
Fluent LoRA技术:音韵自然度的新高度
Fluent LoRA(Low-Rank Adaptation)是MiniMax为Speech 2.6开发的一项创新技术,专门用于提升语音生成的自然度和流畅度。这一技术通过低秩矩阵分解的方式,对预训练模型进行高效微调,使模型能够更好地捕捉语音中的韵律特征和表达细节。
Fluent LoRA技术的最大优势在于其能够保留原始音色的独特特征。无论是带有特定口音的语音,还是包含个人言语习惯(如口头禅、特定语速变化)的素材,Speech 2.6都能精准复刻这些特征,生成高度个性化的语音输出。这一特性对于需要保持品牌声音一致性或实现特定角色声音的应用场景尤为重要。
此外,Fluent LoRA技术还显著提升了模型处理不流利原始素材的能力。传统语音合成系统在处理带有停顿、重复或修正的原始语音时,往往难以生成自然的输出。Speech 2.6则能够智能识别并处理这些不完美之处,生成流畅自然的语音,大大扩展了可用训练素材的范围。
多语言支持:全球化的语音交互体验
Speech 2.6支持40+语种,覆盖了全球主要语言和方言,为构建多语言语音交互系统提供了强大支持。这一特性使得开发者能够轻松开发面向全球用户的产品,无需为不同语言分别训练模型。
在多语言支持方面,Speech 2.6不仅涵盖了英语、中文、西班牙语、法语等主流语言,还包括一些小众语言和方言。这种广泛的语言支持得益于模型的多语言联合训练策略,通过同时学习多种语言的语音特征,模型能够更好地捕捉不同语言之间的共性和差异。
对于需要特定语言变体的应用场景,如地区性口音或专业术语,Speech 2.6也提供了灵活的定制选项。开发者可以根据特定需求对模型进行微调,以适应特定的语言环境或行业术语,确保语音输出的准确性和自然度。
Speech 2.6的典型应用场景
智能客服系统
在客户服务领域,Speech 2.6可以为呼叫中心和在线客服系统提供自然流畅的语音交互体验。传统的IVR(交互式语音应答)系统往往机械生硬,用户体验不佳。Speech 2.6则能够生成富有表现力的语音,模拟真人客服的语调和情感,大幅提升客户满意度。
此外,Speech 2.6的超低延时特性确保了对话的实时性和连贯性,客户几乎感受不到系统响应的延迟。这种流畅的交互体验对于解决复杂问题和维持客户情绪尤为重要。
有声读物与内容创作
对于有声读物、电子书和在线文章等内容创作者来说,Speech 2.6提供了一种高效、高质量的语音生成解决方案。传统上,有声读物的制作需要专业配音演员投入大量时间和成本,而Speech 2.6则能够以较低的成本生成接近专业水准的语音输出。
Speech 2.6的音色复刻功能使得特定作者或角色的声音可以被数字化保存和重现,这对于系列有声读物或需要保持声音一致性的内容尤为重要。同时,模型支持多种朗读风格,如新闻播报、说书、影视配音等,满足不同类型内容的创作需求。
语音助手与智能硬件
在智能家居设备、智能手机和车载系统中,语音助手已成为标配。Speech 2.6可以为这些设备提供自然、友好的语音交互体验,使用户能够以更接近人类对话的方式与设备沟通。
与传统的语音助手相比,基于Speech 2.6的语音助手具有更自然的语调和情感表达,能够更好地理解用户意图并提供恰当的回应。此外,模型的多语言支持使得同一设备可以服务不同语言背景的用户,无需频繁切换语言设置。
广播与播客制作
对于广播电台、新闻机构和播客创作者来说,Speech 2.6提供了一种专业级的语音生成解决方案。传统上,新闻播报和节目主持需要专业播音员,而Speech 2.6则能够生成接近专业水准的广播级语音,大大降低了内容制作成本。
Speech 2.6支持多种播音风格,从严肃的新闻播报到轻松的娱乐节目,都能提供恰当的语音表达。此外,模型能够准确处理专业术语和姓名发音,确保广播内容的准确性和专业性。
语言学习与教育
在语言学习应用中,Speech 2.6可以提供准确的发音示范和语言练习功能。对于语言学习者来说,听到标准、自然的语音发音对于掌握正确发音至关重要。Speech 2.6能够生成各种语言的标准发音,为学习者提供可靠的参考。
此外,Speech 2.6的音色复刻功能使得特定语言教师的独特教学方法可以通过语音保存和重现,为远程教育提供更加个性化的学习体验。模型还可以根据学习者的水平和需求调整语速和复杂度,提供定制化的学习内容。
使用指南:如何快速上手Speech 2.6
注册与登录
要使用Speech 2.6模型,首先需要访问MiniMax Audio官网(https://ai-bot.cn/minimax-audio/)并注册账号。注册过程简单快捷,只需提供基本的个人信息和验证邮箱即可完成。注册成功后,使用账号密码登录平台。
选择语音合成功能
登录后,在平台的左侧导航栏中找到并点击"语音合成"选项,进入语音合成页面。在这里,您可以访问Speech 2.6模型及其相关功能。
输入文本内容
在文本输入框中输入您想要转换为语音的文字内容。Speech 2.6支持各种文本格式,包括专业格式内容如网址、邮箱、电话号码等,无需额外预处理。
选择音色和模型
在输入框下方,您可以从预设的音色库中选择适合的音色,如"沉稳高管"、"亲切客服"等。同时,选择语音合成模型,推荐使用"speech-2.6-hd"以获得最佳音质。
设置应用场景
根据您的具体需求,选择语音合成的应用场景,如"新闻播报"、"说书"、"影视配音"等。这一步骤将帮助模型调整语音的语调、语速和情感表达,以更好地适应特定场景。
生成与使用音频
完成上述设置后,点击"生成音频"按钮,平台将根据您的输入和选择生成语音。生成的语音可以在线试听,满意后可下载到本地保存或直接集成到您的应用中。
技术优势与市场前景
技术优势分析
与传统语音合成技术相比,Speech 2.6在多个方面具有显著优势:
实时性:超低延时(<250ms)确保实时交互的流畅性,这是传统技术难以企及的。
自然度:通过Fluent LoRA技术,生成的语音在韵律和情感表达上更加自然,接近人类语音。
灵活性:支持多种音色和风格,能够满足不同应用场景的个性化需求。
易用性:无需繁琐的文本预处理,直接处理各类专业格式内容,降低使用门槛。
多语言支持:覆盖40+语种,为全球化应用提供便利。
市场前景与行业影响
随着人工智能技术的普及,语音交互已成为人机交互的重要方式。据市场研究预测,全球语音合成市场规模将在未来五年内保持高速增长,年复合增长率超过20%。在这一背景下,Speech 2.6凭借其技术优势,有望在多个领域产生深远影响。
在客户服务领域,Speech 2.6可以帮助企业降低运营成本,同时提升客户体验。据行业数据显示,采用先进语音合成技术的客服系统可以将客户满意度提升30%以上,同时将平均处理时间缩短40%。
在教育领域,Speech 2.6可以为语言学习和在线教育提供更加个性化的学习体验。特别是在远程教育普及的背景下,高质量的语音生成技术可以弥补面对面交流的不足。
在内容创作领域,Speech 2.6可以大幅降低有声内容的生产成本,使更多创作者能够以较低成本生产高质量的有声内容。预计这将推动有声读物、播客等内容形式的进一步繁荣。
未来发展方向
尽管Speech 2.6已经在多个方面实现了突破,但语音合成技术仍有巨大的发展空间。未来,MiniMax可能会在以下方向继续探索:
情感表达:进一步丰富语音的情感表达能力,使AI语音能够传达更复杂的情感和态度。
个性化定制:提供更加灵活的个性化定制选项,使用户能够轻松创建独特的语音形象。
多模态交互:结合视觉、语音等多种交互方式,打造更加自然的人机交互体验。
边缘计算优化:优化模型以适应边缘计算环境,使语音合成能够在本地设备上高效运行。
跨语言迁移:提升模型在不同语言之间的迁移能力,减少对新语言数据的依赖。
结语
MiniMax推出的Speech 2.6语音生成模型凭借其超低延时、专业格式处理、Fluent LoRA技术和多语言支持等特性,正在重新定义语音交互的标准。无论是智能客服、有声读物、语音助手还是教育应用,Speech 2.6都能提供高效、自然的语音交互体验。
随着技术的不断进步,我们有理由相信,未来的语音合成将更加智能、更加自然,成为人机交互不可或缺的一部分。对于开发者和企业来说,把握Speech 2.6这样的先进技术,将为产品创新和用户体验提升带来巨大价值。在AI语音技术飞速发展的今天,Speech 2.6无疑是一个值得关注和探索的重要方向。