在人工智能技术飞速发展的今天,Anthropic公司正式发布了其最新的编程模型——Claude Sonnet 4.5。这一模型不仅代表着当前AI编程技术的最高水平,更在多个关键领域实现了质的飞跃,为开发者提供了前所未有的强大工具。
突破性的性能表现
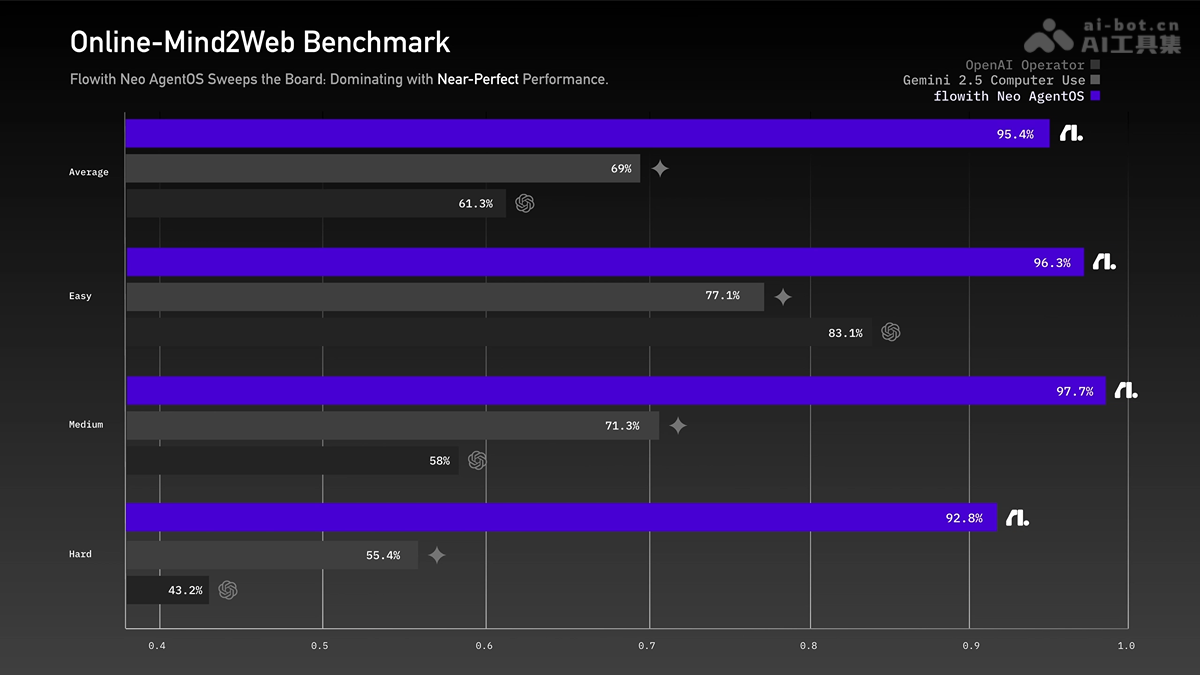
Claude Sonnet 4.5在多项权威评估中展现出卓越的性能。在SWE-bench Verified这一衡量真实世界软件编程能力的评估中,Sonnet 4.5达到了77.2%的准确率,成为目前最先进的编程模型。这一成绩表明,该模型在实际编程任务中能够提供高质量、可靠的代码解决方案。
更令人印象深刻的是,Claude Sonnet 4.5在OSWorld基准测试中表现突出,该测试评估AI模型在真实计算机任务上的表现能力。Sonnet 4.5目前以61.4%的准确率领先,而仅仅四个月前,Sonnet 4的领先成绩为42.2%。这一19.2个百分点的提升幅度,充分展示了模型在计算机使用能力上的显著进步。

长时间任务处理能力
Claude Sonnet 4.5最引人注目的特点之一是其超长时间的任务处理能力。在实际应用中,该模型能够保持专注超过30小时,完成复杂的多步骤任务。这一能力对于需要长时间持续工作的编程项目、系统维护或复杂问题解决场景具有革命性意义。
长时间任务处理能力的提升,使得Claude Sonnet 4.5能够处理更加复杂的编程挑战,如大型系统重构、跨模块代码优化等需要持续专注和连贯思考的任务。这不仅提高了开发效率,也为解决以前难以通过AI完成的复杂编程问题提供了可能。
多领域专业能力
Claude Sonnet 4.5在多个专业领域展现出强大的专业知识和推理能力。根据来自金融、法律、医学和STEM领域的专家评估,该模型在特定领域知识理解和推理方面相比之前的模型(包括Opus 4.1)有了显著提升。
在金融领域,Claude Sonnet 4.5能够提供投资级别的见解,减少人工审查的需求;在法律领域,它能够处理复杂的诉讼任务,如分析完整的简报周期和进行研究,为法官提供优秀的意见初稿;在医学和STEM领域,模型的专业知识深度和准确性也达到了前所未有的水平。
全面的产品升级
随着Claude Sonnet 4.5的发布,Anthropic还对其产品线进行了全面升级:
Claude Code:新增了检查点功能,可以保存进度并允许用户立即回退到之前的状态;刷新了终端界面;发布了原生的VS Code扩展;新增了上下文编辑功能和内存工具。
Claude应用:将代码执行和文件创建(电子表格、幻灯片和文档)功能直接集成到对话中。
Claude for Chrome:向上月加入等待列表的Max用户开放了Chrome扩展。
这些升级使得Claude Sonnet 4.5能够更好地发挥其强大的编程和计算机使用能力,为用户提供更加流畅、高效的体验。
Claude Agent SDK:赋能开发者
Anthropic还发布了Claude Agent SDK,这是他们用于构建Claude Code的基础设施,现在向所有开发者开放。这一SDK包含了Anthropic在过去六个月中解决的关键问题:
- 如何在长时间运行的任务中管理内存
- 如何平衡自主性与用户控制的权限系统
- 如何协调朝向共同目标的子代理
Claude Agent SDK不仅适用于编程任务,还能处理各种广泛的任务类型。开发者可以利用这一工具构建自己的AI代理,解决特定领域的复杂问题。
安全对齐的进步
Claude Sonnet 4.5不仅是迄今为止能力最强的模型,也是对齐度最高的前沿模型。通过改进的能力和广泛的安全训练,Anthropic在模型行为上取得了显著进步,减少了谄媚、欺骗、权力寻求和鼓励妄想思维等令人担忧的行为。
对于模型的代理和计算机使用能力,团队也在防御提示注入攻击方面取得了重大进展,这是这些能力用户面临的最严重风险之一。Claude Sonnet 4.5是在AI安全级别3(ASL-3)保护下发布的,包括旨在检测潜在危险输入和输出的分类器过滤器。
客户反馈与实际应用
来自各行业客户的反馈进一步印证了Claude Sonnet 4.5的卓越性能:
Cursor的CEO:"我们看到Claude Sonnet 4.5展现了最先进的编程性能,在长期任务上有显著改进。这强化了为什么许多使用Cursor的开发者选择Claude来解决他们最复杂的问题。"
GitHub首席产品官:"Claude Sonnet 4.5增强了GitHub Copilot的核心优势。我们的初步评估显示,在多步推理和代码理解方面有显著改进——使Copilot的代理体验能够更好地处理复杂、跨代码库的任务。"
GenAI开发生产力技术主管:"Claude Sonnet 4.5在软件开发任务上表现出色,学习我们的代码库模式以提供精确的实现。它从调试到架构都能处理,具有深刻的上下文理解,彻底改变了我们的开发速度。"
Hai安全首席产品官:"Claude Sonnet 4.5将我们的Hai安全代理的平均漏洞接收时间减少了44%,同时提高了25%的准确性,帮助我们以信心降低企业的风险。"
CoCounsel副总裁:"Claude Sonnet 4.5在最复杂的诉讼任务上处于最先进水平。例如,分析完整的简报周期并进行研究,为法官撰写优秀的意见初稿,或者审查整个诉讼记录以创建详细的即决判决分析。"
总裁:"Claude Sonnet 4.5的编辑功能非常出色——我们在Sonnet 4上的内部代码编辑基准测试错误率从9%降至0%。以更低成本实现更高的工具成功率是代理编程的重大飞跃。Claude Sonnet 4.5完美地平衡了创造力和控制力。"
这些来自不同行业和规模企业的反馈,充分证明了Claude Sonnet 4.5在解决实际业务问题上的强大能力。
'Imagine with Claude'研究预览
alongside Claude Sonnet 4.5,Anthropic还发布了一个名为"Imagine with Claude"的临时研究预览。在这个实验中,Claude能够即时生成软件,没有预定的功能,没有预写的代码。用户看到的是Claude实时创建内容,响应并适应交互过程中的请求。
"Imagine with Claude"展示了Claude Sonnet 4.5的潜力——展示了当将强大的模型与正确的基础设施相结合时可以实现什么。这一功能将在未来五天内向Max订阅者开放,鼓励用户在claude.ai/imagine上尝试体验。
技术细节与评估方法
Claude Sonnet 4.5的发布伴随着详细的技术文档和评估结果。在SWE-bench Verified评估中,所有Claude结果都是使用包含bash和通过字符串替换进行文件编辑两个工具的简单支架报告的。报告的77.2%是10次试验的平均值,没有测试时计算,并在完整的500个问题的SWE-bench Verified数据集上使用200K思考预算。
在"高计算"数字中,团队采用了额外的复杂性和并行测试时计算:
- 采样多个并行尝试
- 丢弃在存储库中破坏可见回归测试的补丁,类似于Agentless采用的拒绝采样方法
- 然后使用内部评分模型从剩余尝试中选择最佳候选
- 这使得Sonnet 4.5的得分达到82.0%
未来展望
Claude Sonnet 4.5的发布标志着AI编程领域进入了一个新的阶段。随着模型的不断进步和相关基础设施的完善,我们可以预见:
更强大的AI代理:Claude Agent SDK的发布将催生更多专门化的AI代理,能够解决特定领域的复杂问题。
人机协作的新模式:长时间任务处理能力的提升将改变开发者与AI协作的方式,使AI能够承担更多复杂、连续的工作。
跨领域应用的扩展:Claude Sonnet 4.5在多个专业领域的出色表现,将进一步推动AI技术在专业领域的应用。
安全与对齐的持续改进:随着AI能力的提升,安全和对齐问题将变得更加重要,Anthropic在这方面的投入将为整个行业树立标杆。
结论
Claude Sonnet 4.5不仅是一个技术突破,更是AI编程领域的一个重要里程碑。它在代码生成、计算机使用、长时间任务处理等多个方面的卓越表现,结合全面的产品升级和强大的开发工具,为开发者提供了前所未有的强大支持。随着Claude Agent SDK的发布和"Imagine with Claude"研究预览的推出,Anthropic正在为AI技术的未来发展奠定坚实基础。
对于开发者而言,Claude Sonnet 4.5是一个值得立即采用的工具,它不仅提供了显著的性能提升,还保持了相同的价格水平。无论是通过Anthropic的应用、API还是Claude Code,开发者都可以轻松升级到这一更强大的模型。
随着AI技术的不断进步,我们有理由相信,Claude Sonnet 4.5及其后续版本将继续推动AI编程领域的发展,为解决更复杂的问题提供可能,同时也将激发更多创新应用和解决方案的出现。