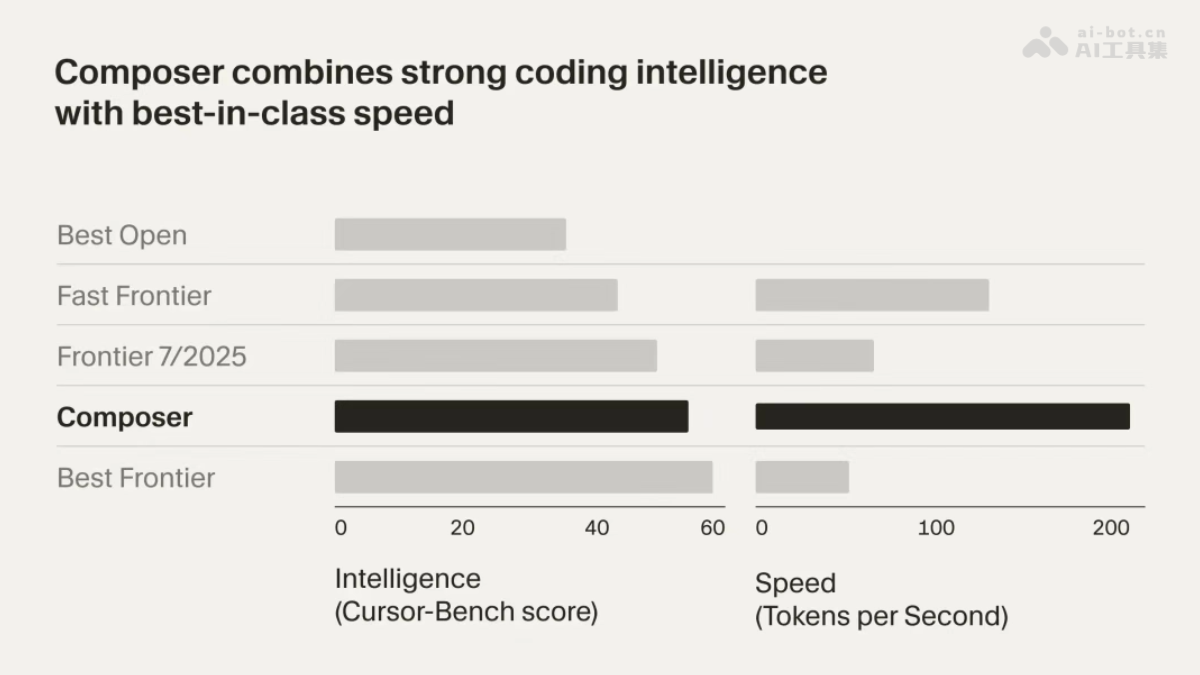
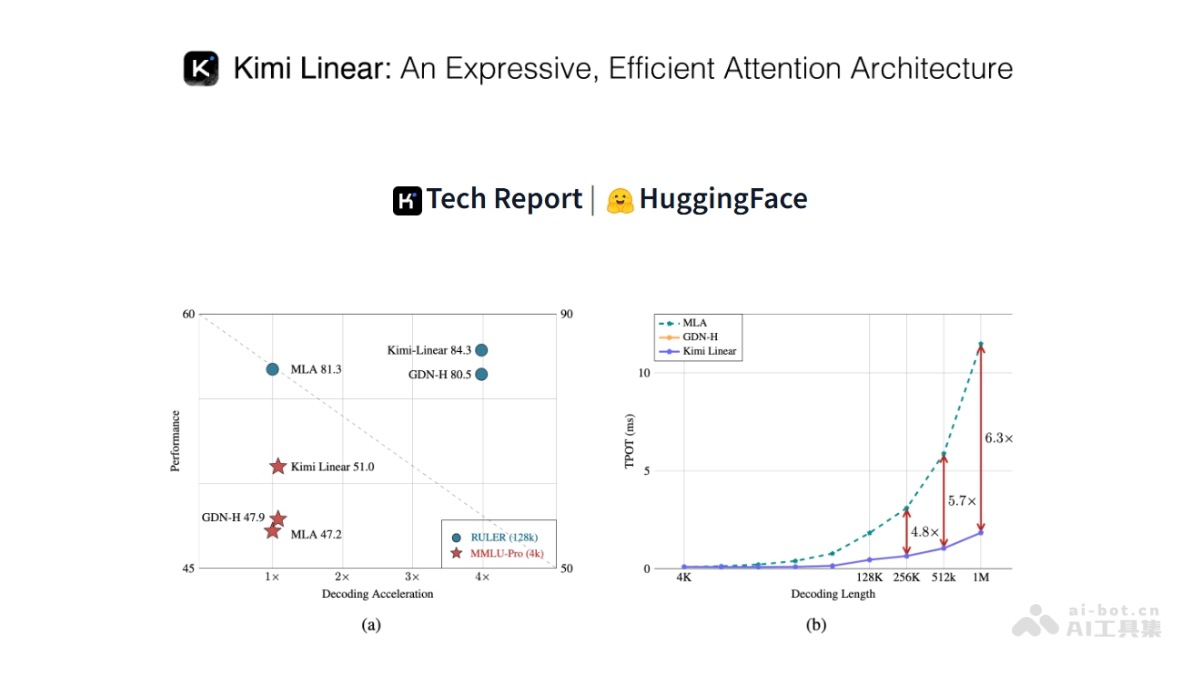
在人工智能技术飞速发展的今天,语音交互已成为人机沟通的重要桥梁。MiniMax最新推出的Speech 2.6语音生成模型,以其卓越的性能和创新的功能,为语音合成领域带来了革命性的突破。本文将全面解析这一创新技术,探讨其如何重塑语音交互体验,并为各行各业带来前所未有的应用可能。
Speech 2.6:重新定义语音生成标准
Speech 2.6是MiniMax专为新一代语音智能体设计的全新语音生成模型,它不仅在技术层面实现了多项突破,更在实际应用场景中展现了卓越的性能。该模型凭借超低延时(低于250毫秒)、专业格式处理能力和Fluent LoRA技术,为用户提供了前所未有的语音交互体验。

与传统语音合成技术相比,Speech 2.6在多个维度实现了显著提升。首先,其端到端延迟低于250毫秒,确保了实时对话场景中的流畅体验;其次,它支持多种语言的网址、邮箱、电话号码等非标准文本格式的直接转换,无需繁琐的预处理步骤;最重要的是,通过Fluent LoRA技术,模型能够进一步提升音韵自然度和音色复刻的流利性,即使在原始素材带有口音或不流利的情况下,也能生成高质量语音。
核心技术解析:Speech 2.6的创新之处
超低延时技术
Speech 2.6最引人注目的特点之一是其超低延时特性。端到端延迟低于250毫秒,这意味着从文本输入到音频输出的整个过程几乎在瞬间完成,为实时对话场景提供了技术保障。这一特性对于需要即时反馈的应用场景尤为重要,如在线客服、实时翻译、语音助手等。
在传统语音合成系统中,文本分析、声学建模和音频生成等多个环节往往需要较长时间处理,导致明显的延迟。Speech 2.6通过优化算法架构和计算流程,显著缩短了处理时间,使得语音交互更加自然流畅,用户体验大幅提升。
专业格式无障碍处理
日常生活中,我们经常需要处理包含网址、邮箱、电话号码、日期及金额等非标准文本的语音内容。传统语音合成系统往往需要对这类文本进行繁琐的预处理,将其转换为标准语音格式,这不仅增加了技术复杂度,还可能导致转换过程中的信息丢失或发音不准确。
Speech 2.6通过内置的专业格式识别和处理模块,能够直接理解和转换多种语言的非标准文本格式,无需用户进行额外预处理。例如,系统能够自动识别并正确发音网址中的特殊字符,准确转换不同地区的日期格式,以及处理各种货币单位的表达方式。这一功能极大地扩展了语音合成系统的应用范围,使其能够更自然地融入日常交流场景。
Fluent LoRA技术:提升自然度的关键
Fluent LoRA(Low-Rank Adaptation)技术是Speech 2.6实现高质量语音生成的核心创新点。该技术通过低秩矩阵分解的方式,对预训练模型进行高效微调,能够在保留原始模型通用能力的同时,针对性地提升特定场景下的语音表现。
在音韵自然度方面,Fluent LoRA技术能够更好地处理语音中的韵律变化,包括语调、重音、停顿等要素,使生成的语音更加接近人类自然的表达方式。在音色复刻方面,该技术能够精确捕捉原始音色的特征,包括口音、语速、情感色彩等个性化元素,实现高度个性化的语音生成。
尤为值得一提的是,Fluent LoRA技术即使在原始素材质量不高的情况下(如带有口音或不流利的录音),也能通过算法优化生成高质量的语音输出。这一特性大大降低了高质量语音生成的门槛,使得更多用户能够享受到先进的语音合成技术。
多语言支持:打破语言障碍
Speech 2.6支持40+语种,涵盖了全球主要语言和方言,这一特性使其成为真正意义上的多语言语音生成解决方案。无论是英语、中文、西班牙语等主流语言,还是某些地区性语言或方言,Speech 2.6都能提供高质量的语音输出。
多语言支持不仅体现在语音生成的质量上,还包括对特定语言文化特色的准确把握。例如,在中文语音生成中,系统能够正确处理声调变化、方言差异和文化背景相关的表达方式;在英语语音生成中,能够准确区分英式英语和美式英语的发音特点,以及不同口音的细微差别。
这种全面的多语言支持能力,使得Speech 2.6能够广泛应用于国际化的业务场景,如跨国客服、多语言教育内容制作、全球化语音助手等,为打破语言沟通障碍提供了强有力的技术支持。
实际应用场景:Speech 2.6的多元价值
客户服务领域
在客户服务领域,Speech 2.6能够为呼叫中心或在线客服系统提供自然流畅的语音交互体验。传统的IVR(交互式语音应答)系统往往给人以机械、刻板的印象,而Speech 2.6生成的语音则更加接近真人对话,能够显著提升客户体验。
具体应用场景包括:
- 自动语音应答:能够自然地理解和回应客户的查询,提供准确的信息
- 语音导航:引导客户完成复杂的操作流程,减少等待时间
- 情感识别:根据客户的语音语调调整回应方式,提供更加个性化的服务
有声读物与内容创作
Speech 2.6为电子书、在线文章或教育材料生成高质量的语音朗读,彻底改变了内容创作和消费的方式。传统有声读物制作需要专业的配音设备和人员,成本高昂且周期较长,而Speech 2.6则能够以极低的成本快速生成专业水准的语音内容。
在有声读物应用中,Speech 2.6的优势体现在:
- 多种音色选择:可根据内容特点选择适合的音色,如沉稳的叙述音、活泼的儿童音等
- 情感表达:能够根据文本内容调整语音的情感色彩,增强内容的感染力
- 多语言支持:轻松实现多语言版本的有声读物,扩大受众范围
语音助手与智能硬件
在智能家居设备、手机或车载系统中,Speech 2.6可以作为语音助手的核心技术,提供自然流畅的语音交互服务。与传统的语音助手相比,基于Speech 2.6的系统能够更好地理解用户的意图,提供更加准确的回应。
具体应用包括:
- 智能家居控制:通过语音指令控制家电设备,实现智能家居的便捷操作
- 车载语音系统:在驾驶过程中提供安全、便捷的语音交互,减少手动操作
- 个人助理:帮助用户安排日程、设置提醒、查询信息等
广播和播客制作
Speech 2.6为广播节目、新闻播报或播客内容生成专业水平的语音,降低了内容制作的门槛。传统广播和播客制作需要专业的播音设备和人员,而Speech 2.6则能够使更多创作者参与到内容制作中来。
在广播和播客制作中,Speech 2.6的应用价值体现在:
- 快速内容制作:大幅缩短内容制作周期,提高生产效率
- 个性化音色:可根据节目特点定制独特的音色,增强品牌识别度
- 多语言版本:轻松实现节目的多语言版本,扩大受众范围
语言学习与教育
在语言学习应用中,Speech 2.6能够提供准确的发音示范和语言练习,帮助学习者提高语言能力。传统语言学习往往缺乏真实的语音环境,而Speech 2.6则能够创造接近真实对话的学习体验。
在语言学习领域的应用包括:
- 发音示范:提供标准、自然的发音示范,帮助学习者掌握正确的发音
- 对话练习:模拟真实对话场景,提供互动式的语言练习环境
- 多语言支持:支持多种语言的学习需求,满足不同学习者的需要
如何使用Speech 2.6:实用指南
注册与登录
使用Speech 2.6的第一步是访问MiniMax Audio官网,注册账号并登录。MiniMax Audio是MiniMax官方提供的语音合成服务平台,用户可以通过该平台访问Speech 2.6模型的各种功能。
注册过程简单快捷,只需要提供基本的个人信息即可完成。对于有更高需求的用户,MiniMax还提供了企业级服务,包括更高的API调用限额、定制化模型训练等增值服务。
选择语音合成功能
登录后,在左侧导航栏中点击"语音合成"选项,进入语音合成页面。在这里,用户可以找到Speech 2.6模型及其相关功能。
MiniMax Audio平台提供了直观的用户界面,用户可以轻松浏览和选择不同的语音合成功能。平台还提供了详细的帮助文档和教程,帮助新用户快速上手。
输入文本与选择参数
在文本输入框中输入想要转换为语音的文字内容。Speech 2.6支持长文本输入,用户可以直接粘贴或输入大量文本,系统会自动进行分段处理。
在输入框下方,用户可以选择喜欢的音色(如"沉稳高管")和语音合成模型(如"speech-2.6-hd")。MiniMax Audio提供了丰富的音色选择,包括不同性别、年龄、语速和情感的音色,满足不同应用场景的需求。
选择应用场景与生成音频
根据需要,选择语音合成的应用场景,如"新闻播报"、"说书"、"影视配音"等。不同的应用场景会对语音的语调、语速、情感等特性提出不同的要求,Speech 2.6能够针对不同场景进行优化。
完成参数设置后,点击"生成音频"按钮,平台将根据输入的文本和选择的参数生成语音。得益于Speech 2.6的超低延时特性,音频生成过程非常迅速,用户几乎可以立即听到结果。
播放与下载音频
生成的语音可以在线播放,用户可以直接在平台上收听效果。如果对效果满意,用户还可以将音频下载到本地保存,方便后续使用。
MiniMax Audio支持多种音频格式下载,包括MP3、WAV等常见格式,用户可以根据实际需要选择最适合的格式。对于有更高音质要求的用户,平台还提供了无损音频格式的下载选项。
技术优势与市场前景
技术优势分析
Speech 2.6在技术层面具有多方面的优势,使其在竞争激烈的语音合成市场中脱颖而出:
卓越的实时性能:超低延时特性使其特别适合实时对话场景,这是许多传统语音合成系统难以企及的。
强大的文本处理能力:对非标准文本格式的直接支持,大大扩展了应用场景,降低了使用门槛。
高度自然的语音输出:通过Fluent LoRA技术,生成的语音在自然度和个性化方面达到了行业领先水平。
全面的多语言支持:40+语种的支持使其能够满足全球化的应用需求。
灵活的部署方式:既可以通过云平台使用,也支持本地化部署,满足不同用户的需求。
市场前景与应用潜力
随着人工智能技术的普及和语音交互需求的增长,语音合成市场正迎来前所未有的发展机遇。根据市场研究数据,全球语音合成市场规模预计在未来几年内将以超过20%的年复合增长率持续扩大,到2025年可能达到数百亿美元规模。
在这一背景下,Speech 2.6凭借其技术优势和多功能特性,具有广阔的市场前景和应用潜力:
企业服务领域:智能客服、语音导航等企业级应用需求旺盛,Speech 2.6能够为企业提供高效、自然的语音交互解决方案。
内容创作行业:有声读物、播客、视频配音等内容创作领域对高质量语音的需求持续增长,Speech 2.6能够大幅降低内容制作成本。
教育行业:语言学习、在线教育等领域对标准语音的需求巨大,Speech 2.6能够提供个性化的语音学习体验。
智能硬件领域:随着智能家居、智能汽车等设备的普及,对自然语音交互的需求不断增加,Speech 2.6能够为这些设备提供强大的语音支持。
无障碍服务领域:为视障人士提供语音辅助服务,Speech 2.6能够帮助他们更好地获取信息、进行交流。
未来发展方向与挑战
尽管Speech 2.6已经在多个方面实现了技术突破,但语音合成领域仍有广阔的发展空间。未来,MiniMax可能会在以下几个方向继续探索和改进:
情感语音合成
目前的语音合成技术虽然在自然度方面取得了显著进步,但在情感表达方面仍有提升空间。未来的语音合成系统可能需要更好地理解和表达复杂的情感状态,使语音交互更加富有感染力和个性化。
多模态交互
语音交互往往需要与其他模态(如视觉、手势等)结合,才能实现更自然、更高效的人机沟通。未来的语音合成系统可能会更多地融入多模态交互元素,提供更加全面的交互体验。
个性化定制
每个用户都有自己独特的语音特点和偏好,未来的语音合成系统可能会提供更加精细的个性化定制选项,包括音色、语调、语速等方面的深度定制,满足不同用户的个性化需求。
实时优化与适应
在实际应用场景中,语音合成系统可能需要根据环境、用户状态等因素进行实时调整和优化。未来的系统可能会具备更强的自适应能力,能够在不同场景下自动调整参数,提供最佳的语音输出。
隐私与安全
随着语音合成技术的广泛应用,隐私和安全问题也日益凸显。未来的系统需要更好地保护用户数据,防止语音被滥用或恶意使用,确保技术的健康发展。
结语:语音交互的未来已来
MiniMax Speech 2.6的推出,标志着语音合成技术进入了一个新的发展阶段。通过超低延时、专业格式处理和Fluent LoRA技术等创新,Speech 2.6不仅提升了语音合成的质量和效率,更拓展了语音交互的应用边界。
在人工智能技术不断进步的今天,语音交互已成为人机沟通的重要方式。从智能客服到语音助手,从有声读物到语言学习,Speech 2.6正在为各行各业带来革命性的变化,创造前所未有的价值。
未来,随着技术的不断发展和应用场景的持续拓展,语音合成将更加智能化、个性化和自然化,成为连接人类与数字世界的重要桥梁。MiniMax Speech 2.6作为这一领域的先行者,将继续引领技术创新,推动语音交互体验的不断升级,为构建更加智能、便捷的未来社会贡献力量。