
在人工智能领域,谷歌的Gemini多模态大模型无疑是一颗耀眼的新星。它不仅具备强大的对话能力,更在多模态信息的处理上展现出卓越的性能。本文将深入剖析Gemini的报告,揭示其在图像、音频、视频和文本理解方面的独特优势,以及它如何通过Ultra、Pro和Nano等不同尺寸的模型,满足从复杂推理到设备内存受限等多样化的应用场景需求。
与OpenAI需要借助多个独立模型实现多模态能力不同,Gemini的一大特点是在预训练阶段就直接接受多模态输入。这种一体化的设计使其能够更高效地处理多模态数据,并在各项指标上取得优异的成绩。更重要的是,Gemini通过融合图文理解等能力与大模型的对话能力,为用户带来了更加惊艳的交互体验。
Gemini的技术解析
1. 动机与定位
谷歌推出Gemini的直接目标是打造一款能够与GPT-4相媲美的大模型。这意味着Gemini需要在多个方面都具备顶尖的实力,尤其是在多模态能力上,包括对文字、图像、视频和音频的全面识别与理解。
2. 方法与特点
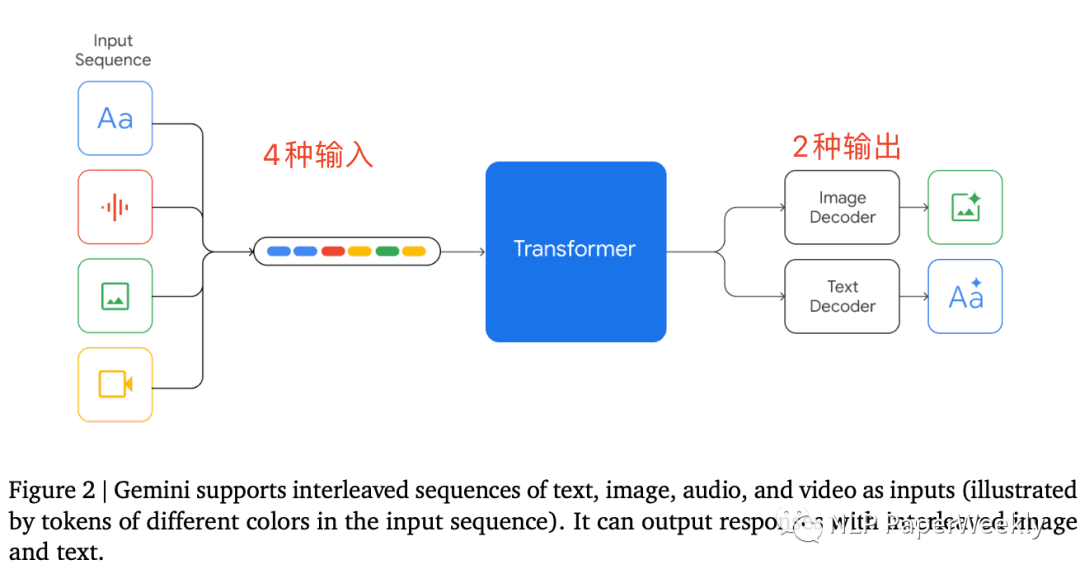
Gemini模型最引人注目的特点在于其对多种输入格式的支持和输出格式的灵活性。具体来说,Gemini能够同时处理文本、图像、视频和音频四种不同类型的输入,并支持文本和图像两种输出形式。这种设计使得Gemini可以直接处理音频文件,而无需像传统方法那样先将音频转换为文本。
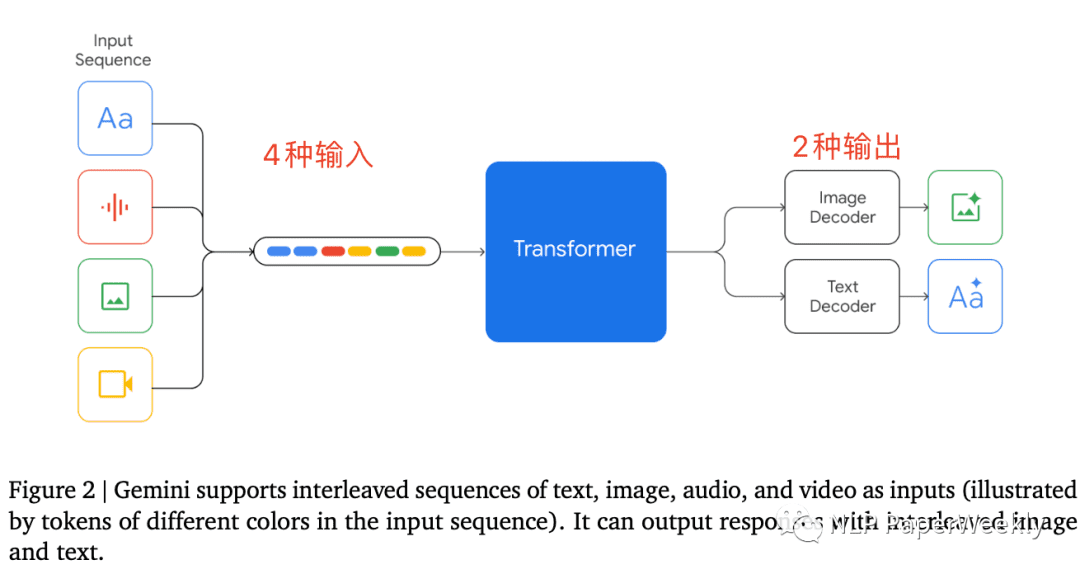
3. 训练方法推测
根据业内专家的分析,Gemini的训练方法可能包含以下几个关键要素:
- 多模态联合训练: Gemini很可能采用了多模态联合训练的方法,即从一开始就将文本、图片、音频和视频等多种模态的数据融合在一起进行训练。这与目前常见的多模态模型有所不同,后者通常会利用现成的语言大模型或预训练过的图片模型,然后在此基础上添加新的网络层进行训练。
- 解码结构优化: Gemini可能采用了Decoder-only的模型结构,并针对大规模训练的稳定性和推理效率进行了优化。这种结构类似于GPT,采用预测下一个token的方式进行训练,并支持高达32K的上下文。
- 指令理解: 与GPT类似,Gemini也采用了多模态Instruct数据进行SFT(监督微调)、RM(奖励模型)和RLHF(基于人类反馈的强化学习)三个阶段的训练。在训练打分模型时,Gemini可能采用了加权的多目标优化,同时考虑了Helpfulness、Factuality和Safety三个指标。
- 模型规模: 从硬件描述来看,Gemini使用了前所未有的TPU集群,这暗示着Gemini Ultra的模型规模非常庞大。如果采用MOE(Mixture of Experts)结构,其模型容量可能达到GPT-4的1.8T级别;如果采用Dense模型,其参数量可能超过200B。
- 训练细节: Gemini的训练可能分为多个阶段,并在最后阶段提高了领域数据的混合配比,特别是逻辑和数学类的训练数据,这有助于提升模型的逻辑能力。
- 代码能力: AlphaCode2是在Gemini Pro的基础上,使用编程竞赛的数据进行微调得到的。其在编程竞赛中的表现非常出色,超过了85%的人类选手,而之前的AlphaCode1只能超过50%的人类选手。
4. 模型版本
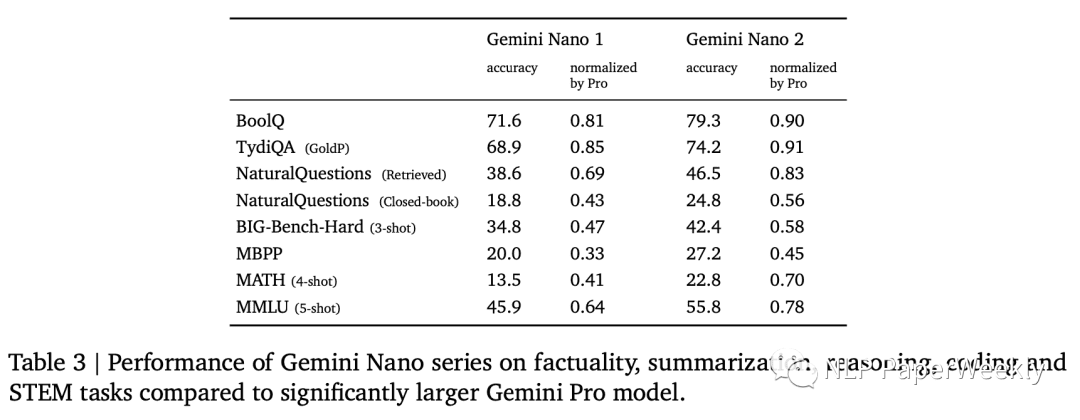
Gemini模型有多个版本,其中最小的版本只有1.8B参数。Gemini Nano包含两个版本:1.8B面向低端手机,3.25B面向高端手机。

Gemini的卓越性能
1. 文本理解
在文本理解方面,Gemini Ultra的性能已经超越了GPT-4。Gemini Pro的性能也优于GPT-3.5。在MMNLU(大规模多任务自然语言理解)测试中,Gemini首次超越了人类专家水平。
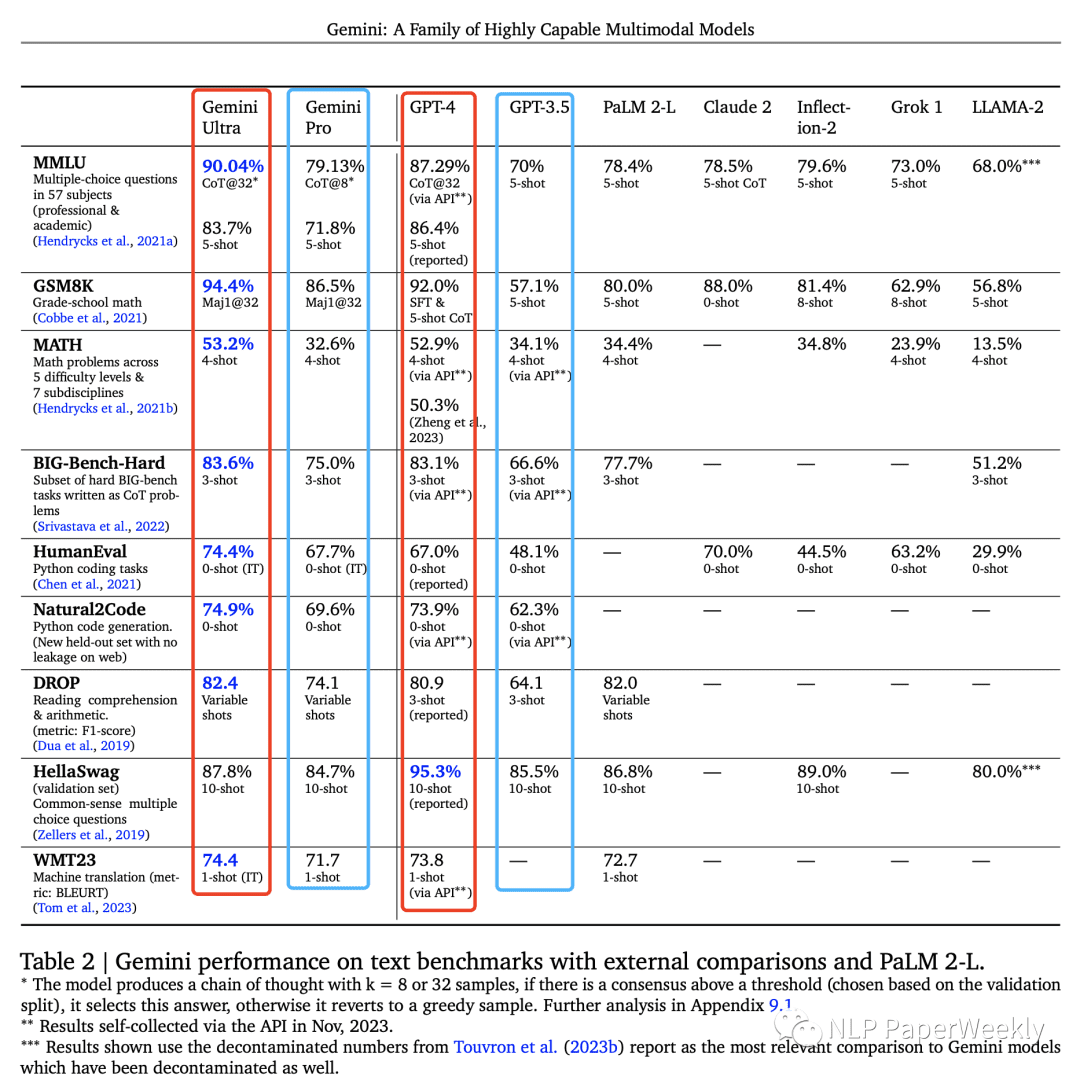
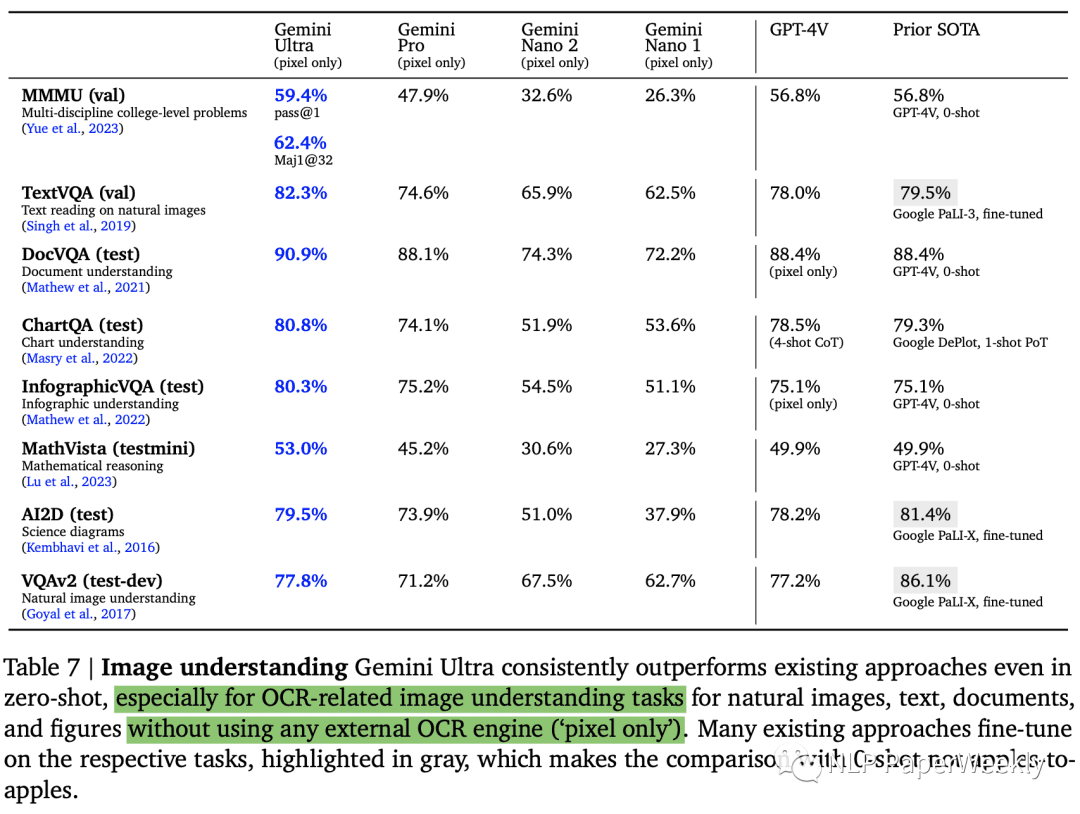
2. 图像理解
在图像理解方面,Gemini的Zero-shot(零样本)效果已经超过了很多经过微调的模型。
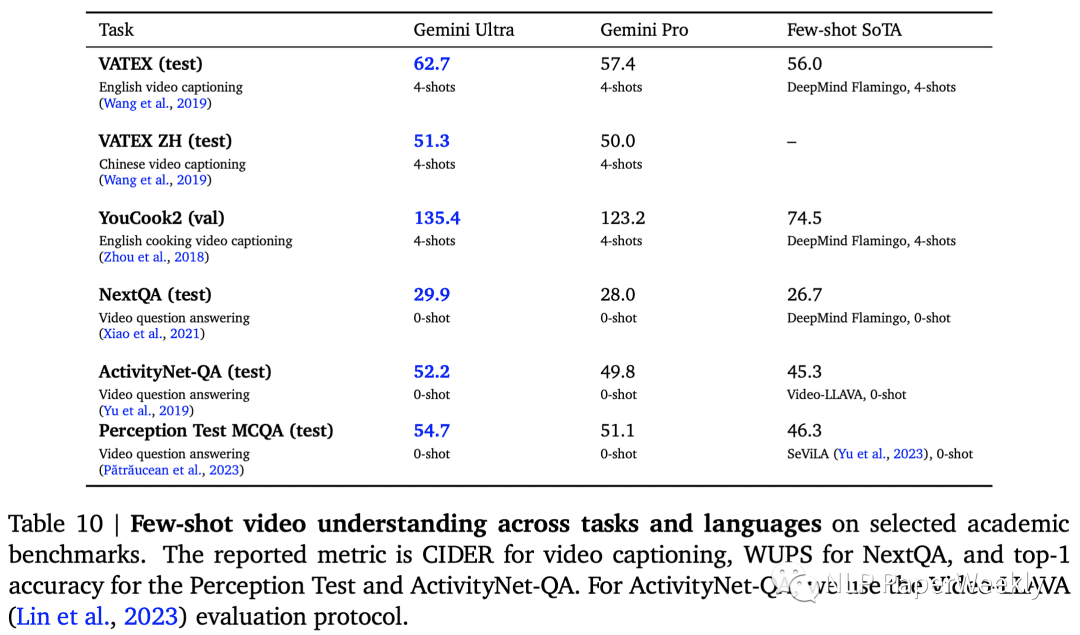
3. 视频理解
在视频理解方面,Gemini也超越了之前的Few-shot(少样本)SoTA(State-of-the-Art)模型,尤其是在英语视频字幕数据集(VATEXT、YouCook2)上提升较大。
4. 不同版本Gemini模型的性能
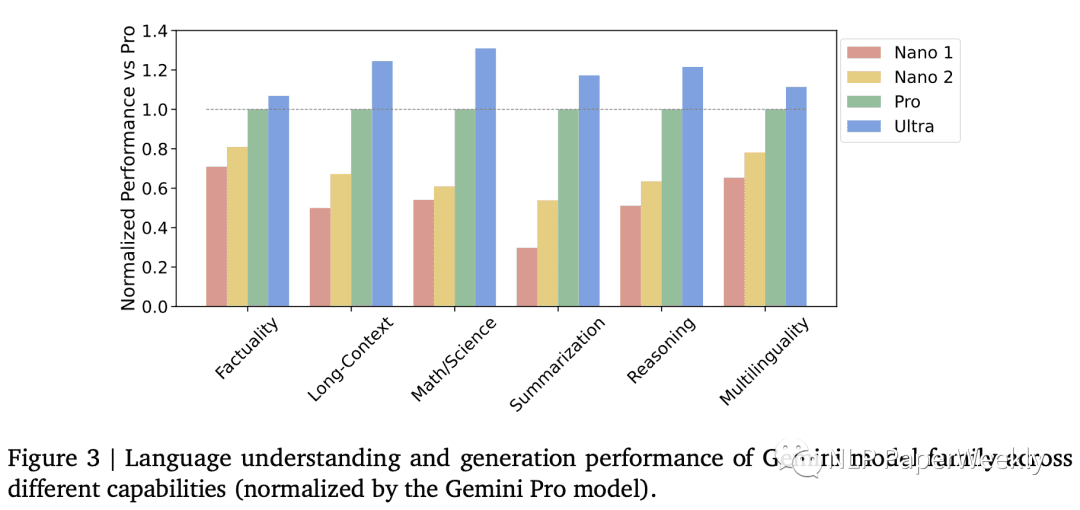
为了更好地了解不同版本Gemini模型的性能,我们可以从以下几个方面进行评估:
- 事实性: 涵盖开放/闭卷检索和问题回答任务。
- 长文本: 涵盖长篇摘要、检索和问题回答任务。
- 数学/科学: 包括数学问题解决、定理证明和科学考试等任务。
- 推理: 需要算术、科学和常识推理的任务。
- 多语言: 用于多语言翻译、摘要和推理的任务。
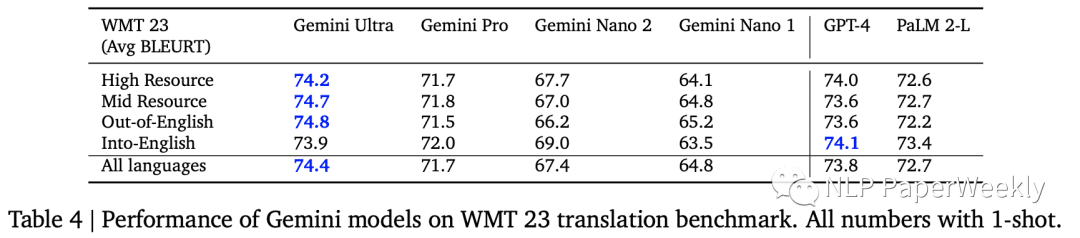
5. 多语种翻译
在多语种翻译方面,Gemini的性能也超过了GPT-4。在WMT23指标中,Gemini在四个指标中的三个上都超过了GPT-4的表现。
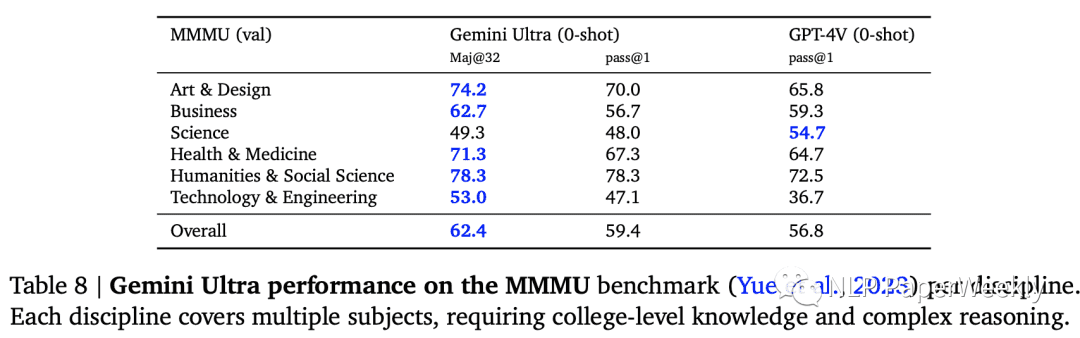
6. 图像理解数据集
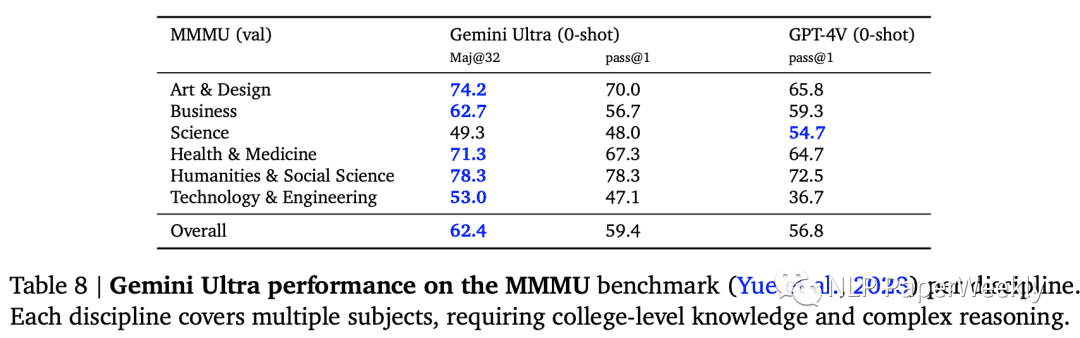
在MMMU数据集上,Gemini Ultra将最先进的结果提高了5个百分点以上,并在6个学科中的5个学科中超越了之前的最佳成绩,充分展示了其强大的多模态推理能力。
Gemini的多模态能力展示
1. 几何推理
Gemini可以识别手写答案,并对物理问题进行解答。例如,它可以识别手写的几何图形,并计算平行四边形的高。

2. 视觉多模态推理
Gemini可以根据图片确定地点。例如,它可以识别地标建筑,并判断图片拍摄的地点。

3. 多语言常识推理
Gemini可以识别中文关系图,并进行多语言常识推理。例如,它可以识别人物关系,并推断出他们之间的亲属关系。
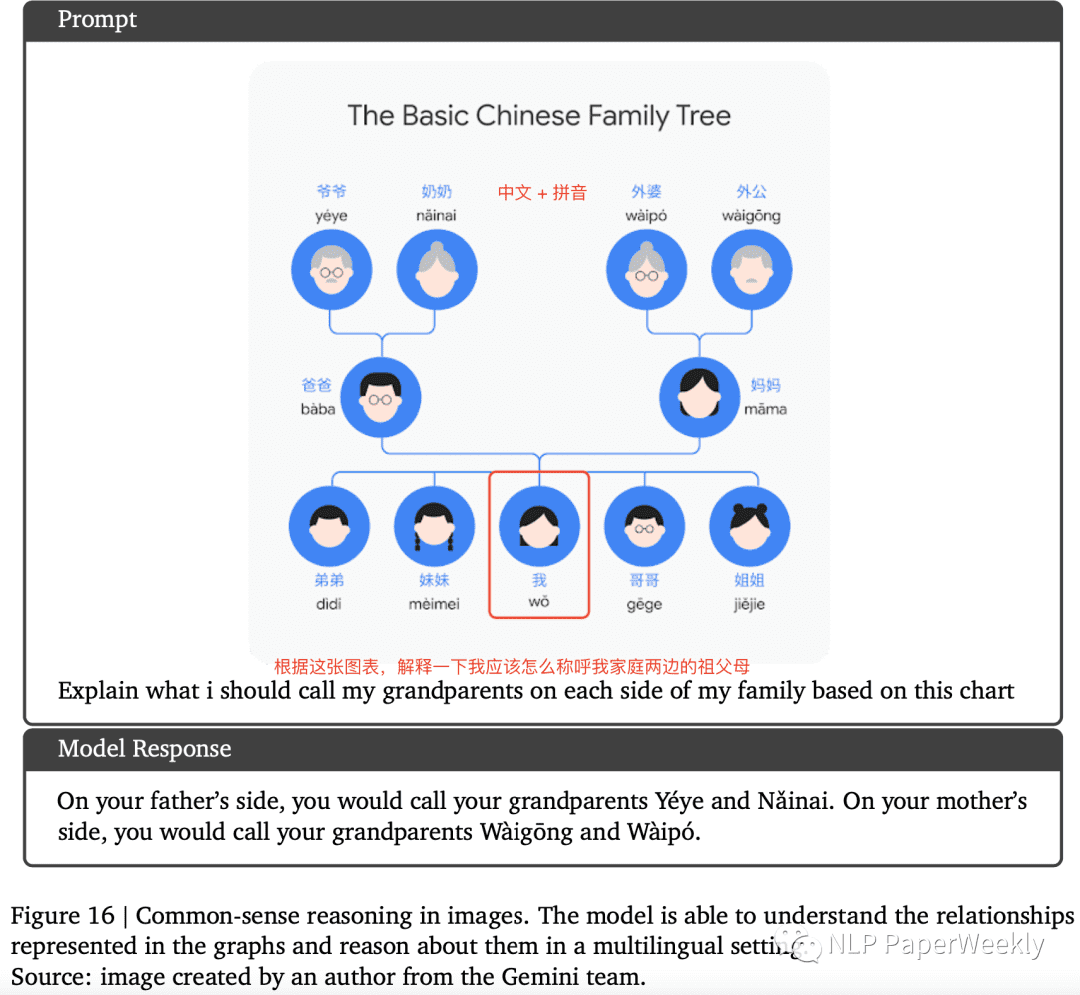
4. 视频理解
Gemini可以分析视频中的人物如何提升足球技术,并提供相关的建议。

Gemini的意义与展望
Gemini的推出无疑是人工智能领域的一项重大突破。它不仅在多模态能力上实现了新的高度,也为未来的大模型发展指明了方向。然而,我们也需要清醒地认识到,Gemini仍面临着一些挑战,例如模型的稳定性和鲁棒性,以及如何更好地将多模态能力应用于实际场景。
1. 多模态能力的统一是趋势
Gemini直接支持多模态的能力是其一大特点。谷歌从预训练阶段就统一了多模态大模型的训练,该策略也可能是后续大模型的发展趋势。这种统一的设计可以带来更高的效率和更好的性能,但也需要付出更高的成本。
2. 性能对比
Gemini的多模态能力比GPT-4V更强,但在科学推理能力方面可能稍逊于GPT-4。
3. 实际应用
图文理解和视频理解等多模态能力与最新的大模型强强组合,确实能带来惊艳的效果。然而,其稳定性以及是否真实能落地还有待进一步观察。例如,结合图像信息求平行四边形的高,在教育领域相对于纯文本可能会更有价值,但是OCR等技术还面临鲁棒性偏差的问题,Google的模型短时间内应该还是没办法解决这些问题。

总的来说,Gemini的出现为人工智能领域带来了新的机遇和挑战。我们期待着它在未来的发展中能够不断突破,为人类带来更多的惊喜。







