在人工智能领域,大型语言模型(LLM)正以前所未有的速度发展。其中,Qwen-72B作为阿里巴巴在2023年末开源的巨型语言模型,以其庞大的参数规模和卓越的性能,再次刷新了国内开源模型的记录。Qwen-72B基于Transformer架构,通过海量预训练数据进行训练,涵盖了网络文本、专业书籍和代码等广泛领域。同时,在Qwen-72B的基础上,阿里还构建了基于对齐机制的AI助手Qwen-72B-Chat,使其更适用于人机对话和自然语言处理任务。本文将深入探讨Qwen-72B-Chat模型的架构、训练方法,并结合实际案例,介绍如何使用QLoRA技术对其进行微调,最终在推理集群上进行推理测试。
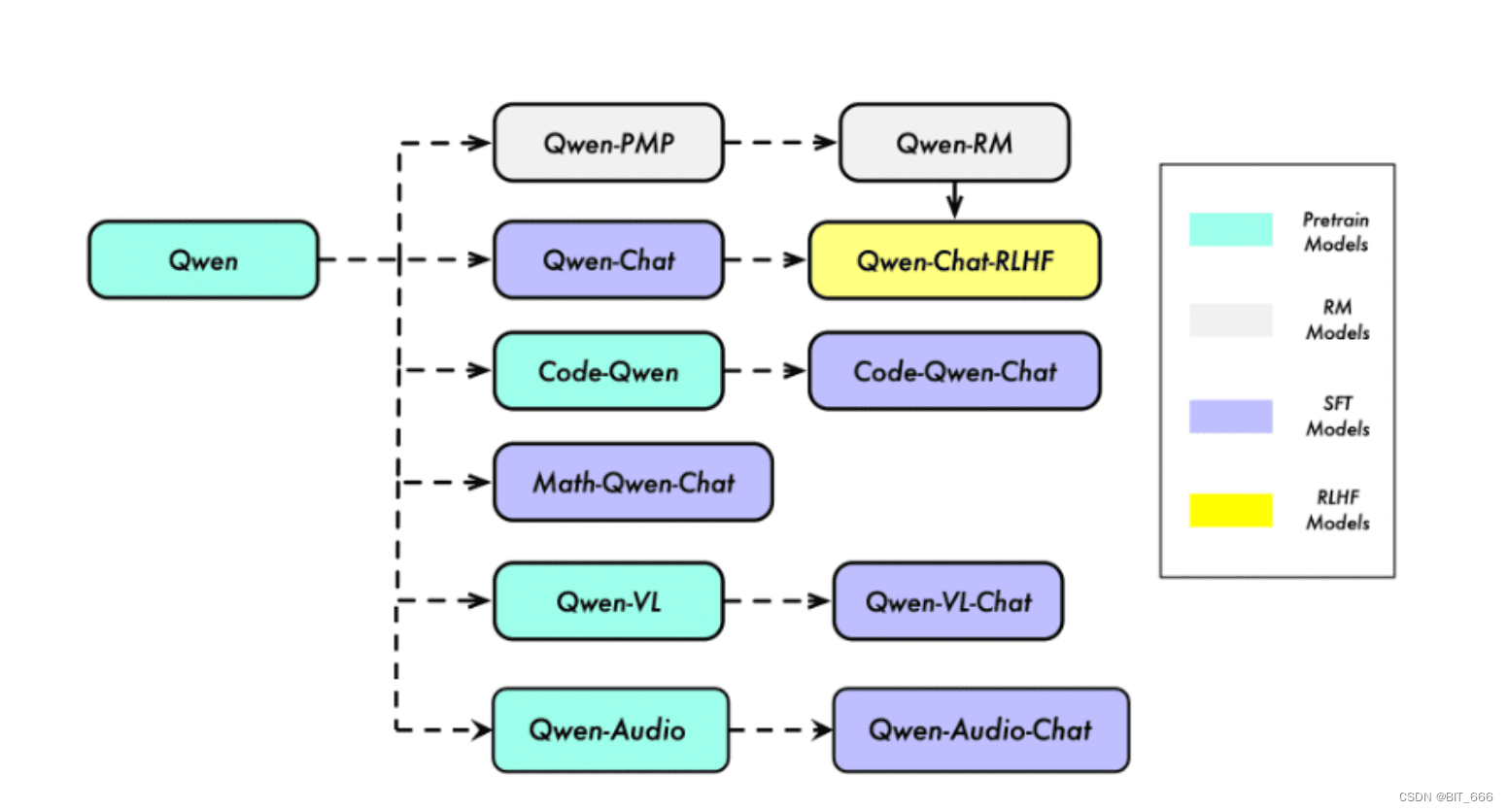
Qwen不仅仅是一个包含基础模型(Base)和聊天模型(Chat)的语言类大模型,更是一个致力于实现通用人工智能(AGI)的项目。它涵盖了大型语言模型(LLM)和大型多模态模型(LMM),并细分为多个智能模块和训练场景。根据训练场景的不同,Qwen包含了PT(Pre-Train,预训练)、SFT(Supervised Fine-Tuning,有监督微调)、RLHF(Reinforcement Learning from Human Feedback,强化学习人类反馈)和RM(Reward Model,奖励模型)等全链路模型。本文使用的基座模型Qwen-Chat,正是通过有监督微调和RLHF,使其更适合应用于常见的语言文本AI智能场景。此外,Qwen还包括用于编程的“Code-Qwen”、用于数学的“Math-Qwen”、用于音频的“Qwen-Audio”以及视觉语言的“Qwen-VL”,这些模型在各自领域的特点,使得文生文、文生图等应用场景得以轻松实现。
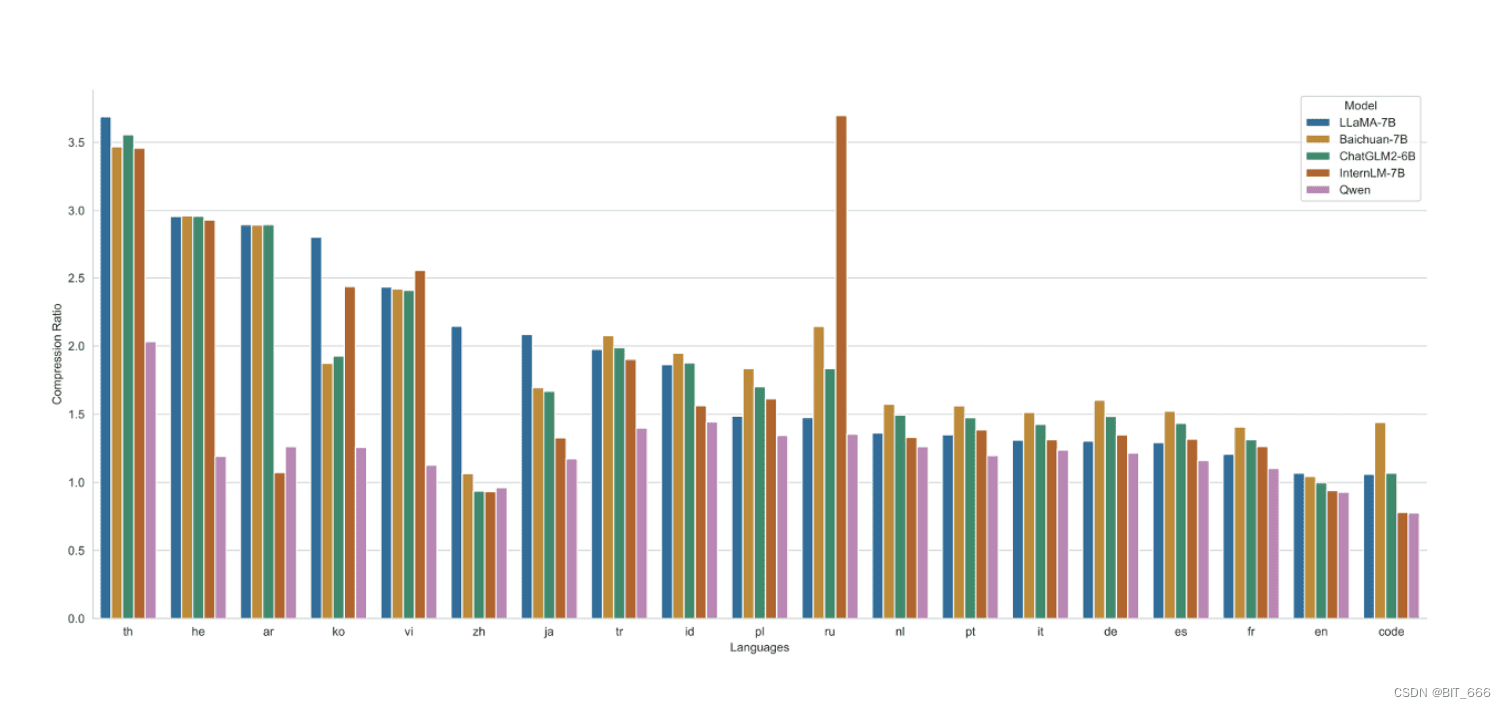
Qwen-72B通过3.0T Tokens的预训练语料进行充分训练,最大支持32k的上下文长度。Q-LoRA的最低显存要求为61.4 GB,但实际应用中,需要根据具体情况进行考量。在Tokenizer方面,一个好的Tokenizer应该能够在同等token数量下表征更多的文本类型,具有更高的压缩率和更高效的表达能力。Qwen本质上是一个多语言模型,它在英语和中文方面表现出色,同时也能处理其他语言,如西班牙语、法语和日语。为了扩展其多语种能力,Qwen采用了一种在编码不同语言信息方面具有高效率的分词器。与其他分词器相比,该分词器在一系列语言中展示了高压缩率。

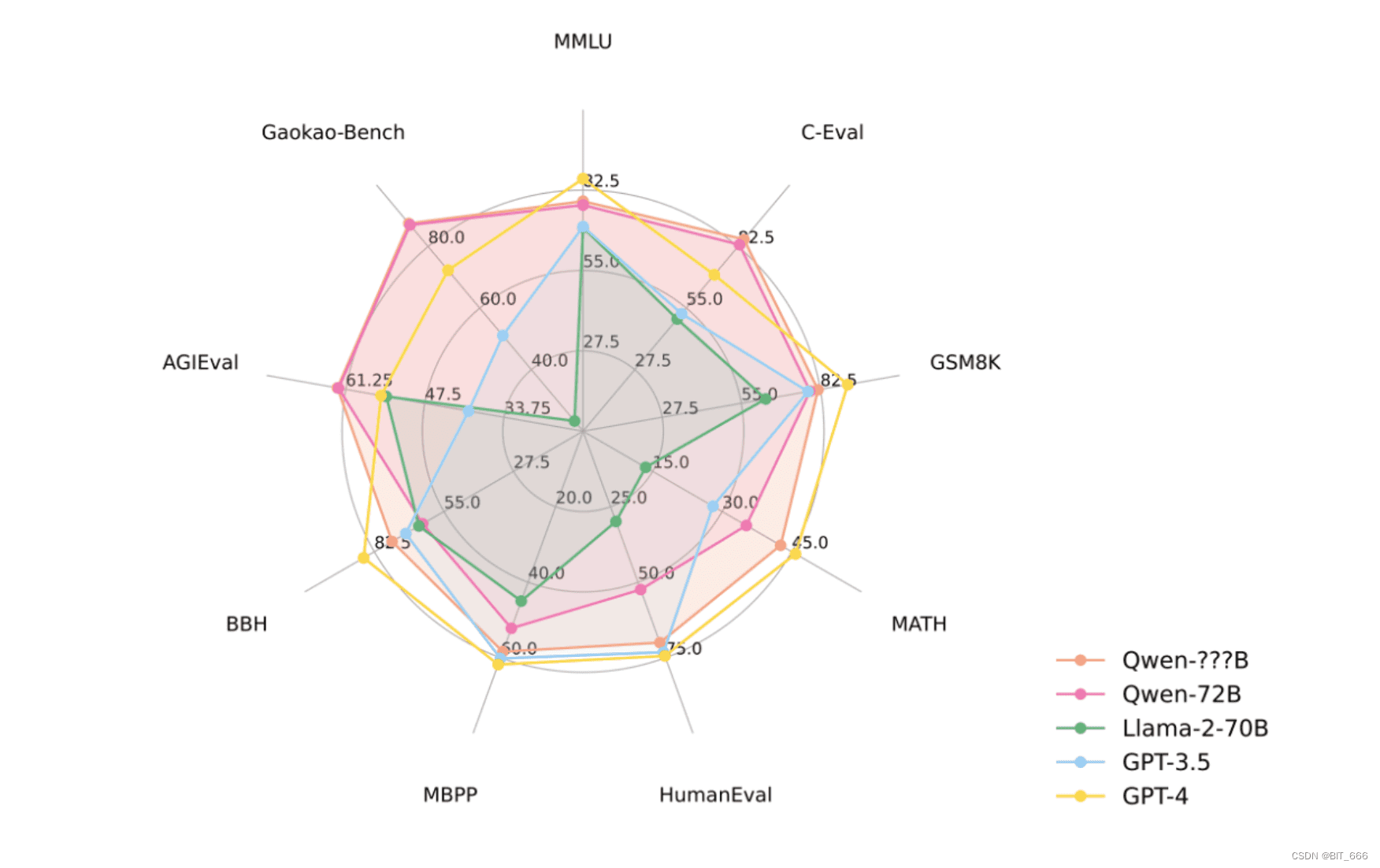
评估基准显示,开源模型Qwen-72B以及最大的私有模型在性能上与Llama 2、GPT-3.5和GPT-4具有竞争力。这里是对基础Base语言模型的评估,一个好的Base模型可以为后续SFT(有监督微调)和RLHF(强化学习人类反馈)奠定更好的基础。
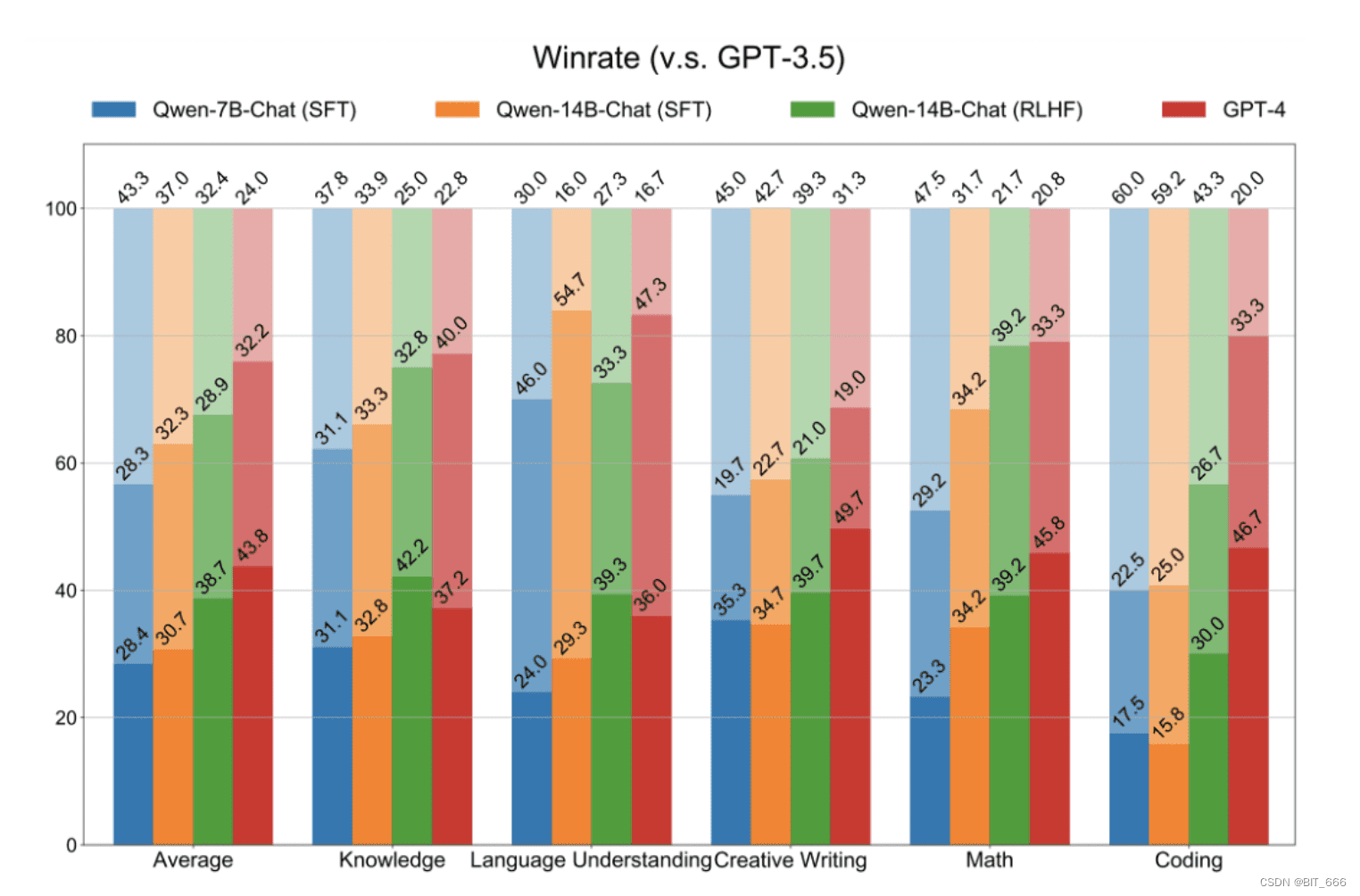
目前,行业内的共识是可以通过相对较少量的微调数据获得一个高质量的聊天模型。Qwen专注于提高SFT数据的多样性和复杂性,并通过人工检查和自动评估严格控制质量。基于一个良好的SFT模型,可以进一步探索RLHF的效果。特别是基于PPO(近端策略优化)的方法,但训练RLHF极具挑战。除了PPO训练的不稳定性之外,另一个关键是奖励模型的质量。因此,Qwen在构建可靠的奖励模型上进行了大量投入,通过在大规模偏好数据上进行奖励模型预训练,以及在精心标记的高质量偏好数据上进行微调。与SFT模型相比,经过RLHF的模型更具创造性,更好地遵循指令,因此其生成的回复更受人类评注者的青睐。当然,在垂类领域,也可以基于DPO轻量化的实现人类偏好专注,提高模型能力的偏向性。需要注意的是,RM-Model或者DPO中构建的偏好Pair严格意义上并不一定代表一个是好的,一个是不好的,而是对于不同的场景,更加偏向哪个选择。
接下来,我们结合HuggingFace上的modeling.py,深入了解Qwen模型的内部结构。Qwen-72B的模型配置包含多个关键参数,例如,hidden_size(隐层大小)为8192,max_position_embeddings(最大位置嵌入)为32768,head的数量(num_attention_heads)为64,Decoder的数量(num_hidden_layers)为80,词库大小(vocab_size)为152064,ROPE旋转位置编码里θ的空间(rope_theta)为1000000。这些参数的设置,使得Qwen-72B在上下文长度和词库等方面都实现了显著提升。
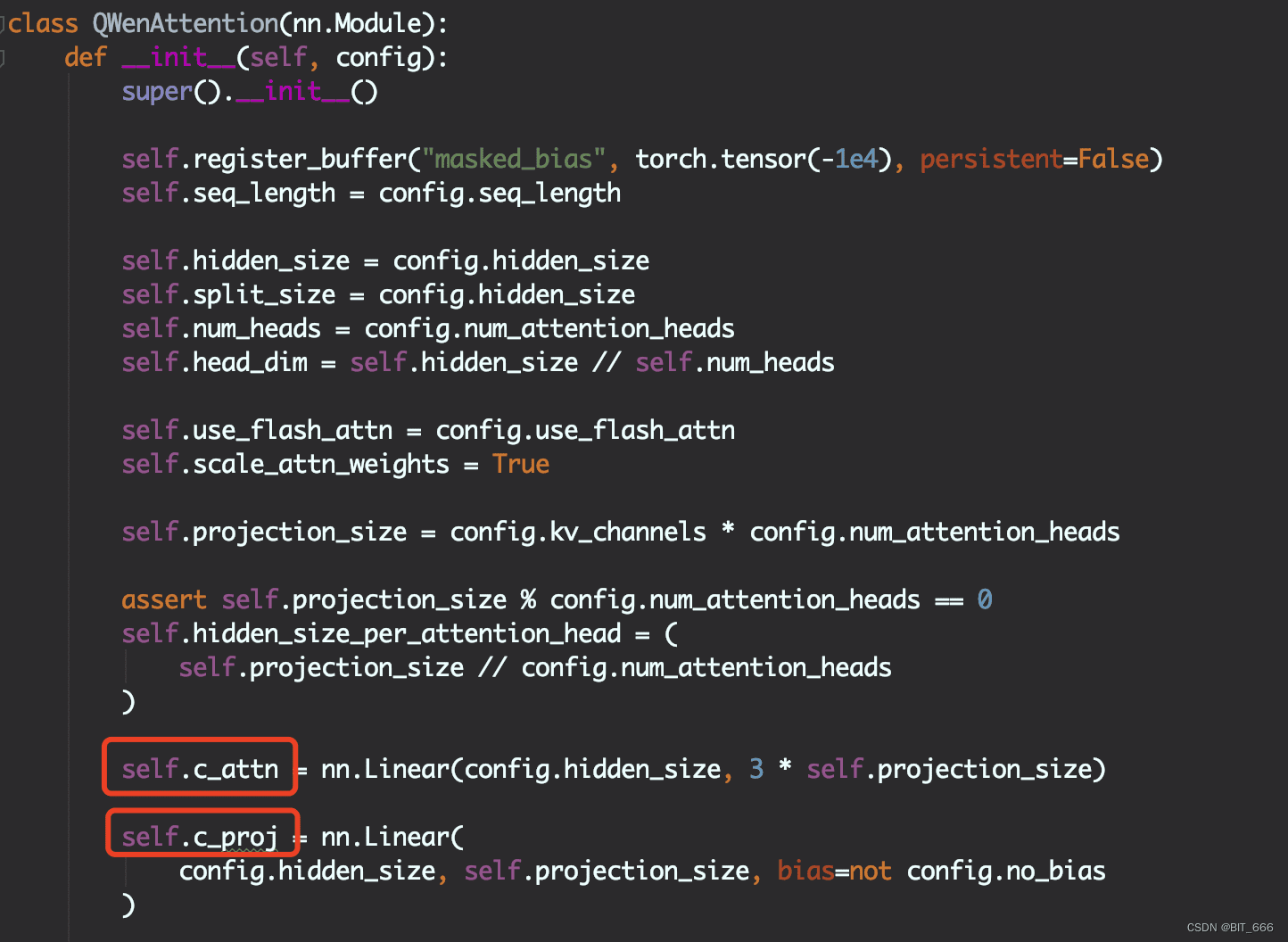
在LoRA微调中,增加adapter的两个Linear层分别为c_attn与c_proj,它们的size分别为hidden_size x 3倍的投影size,以及hidden_size x 投影size。其中,投影层projection_size由多头机制的num_heads与kv_channels决定。通过c_attn可以获取Q/K/V的对应Embedding,因为后续forward计算时会进行split操作。c_attn层负责计算Query、Key和Value向量,而c_proj层则负责将多个注意力头的输出连接在一起,并通过一个线性变换投影到一个较小的维度空间。这两个层在Transformer架构中至关重要,它们共同负责模型的核心操作——自注意力机制的实现和多头注意力信息的整合。
QwenAttention层的forward过程遵循了Multi-Head Attention的实现思路。经过c_attn后得到的Q/K/V分别split_heads分为多头,并对Q/K应用rotary_pos_emb ROPE旋转Embedding添加位置信息。Qwen的θ设置的比较大,其PE的外推性也会更好。
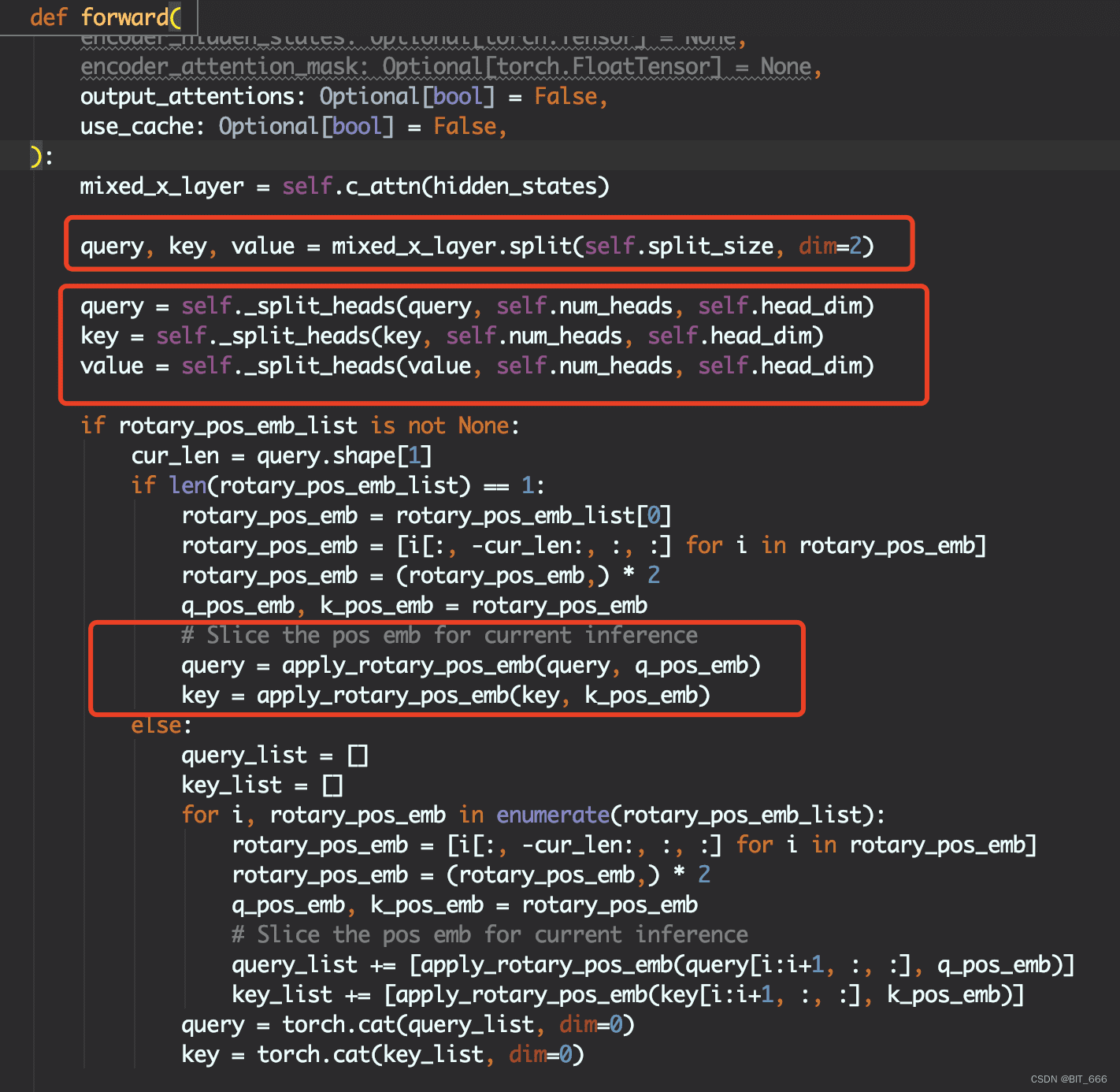
通过计算Scaled_dot_product_attention,合并多头输出,并通过c_proj转换得到output输出。这里的self.attn方法为完整的基于causal_mask计算Weights并得到最终Weighted-Output的方法。
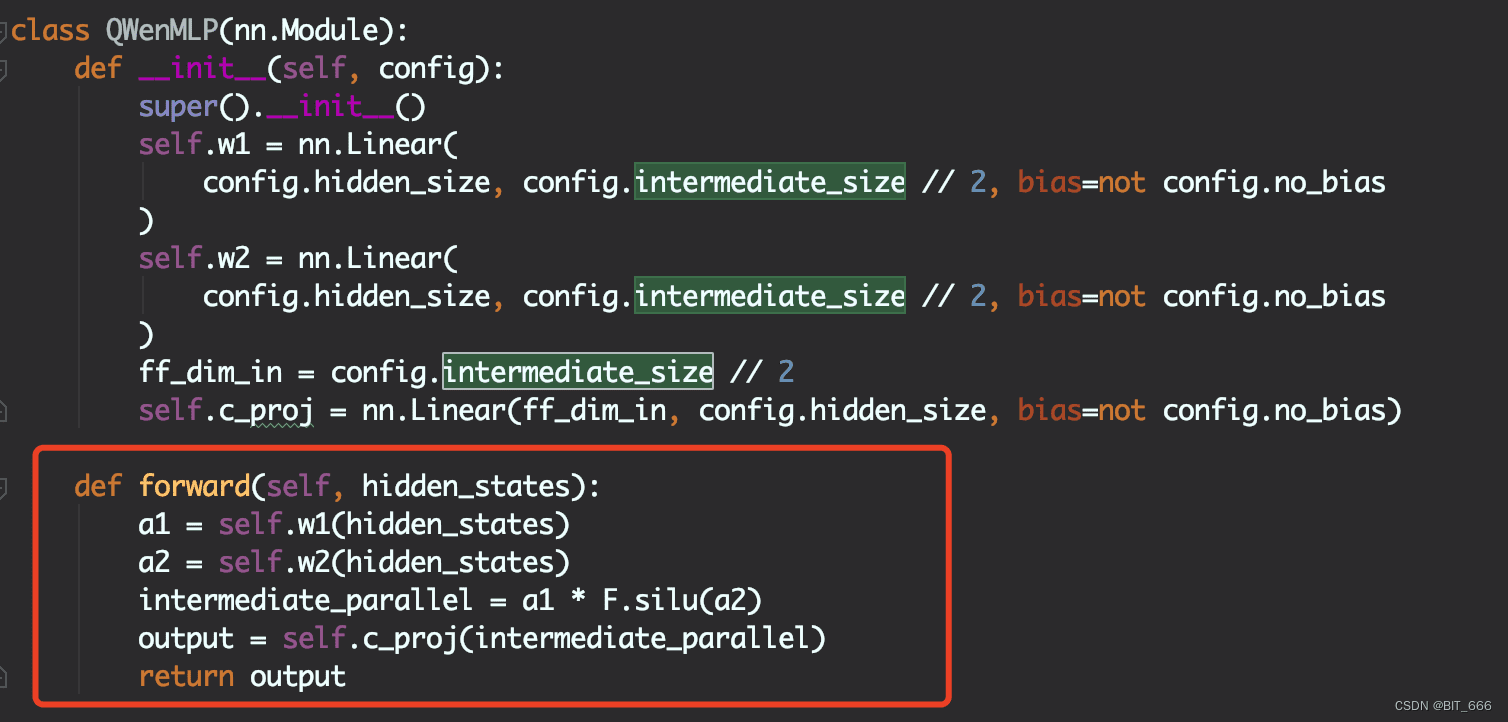
关于ROPE的由来与代码实现,其通过矩阵乘方式为Q/K引入位置信息,使得token能够在Attention计算中感知到相对位置信息。在LLM中,MLP层是构成模型的主要组成部分之一。在Transformer架构中,MLP层通常位于自注意力机制层后面,并且每个Transformer块中都有一个MLP层。Attention层负责抽取文本的浅层含义,而MLP层负责获取文本的语义即更深层的含义。中间层的大小(intermediate_size)决定了在进入MLP层的前馈神经网络之前,经过自注意力计算后的embedding表示会被投影到一个更高维度的空间。MLP的逻辑是w1、w2线性转换后进行哈达玛积,这里也是其基于传统Attention的一个改变即parallel_product,最后再通过c_proj转换为hidden_status的维度。更大的intermediate_size可能使模型能够捕捉更复杂的特征,但也会导致更多的计算开销和更大的模型尺寸。
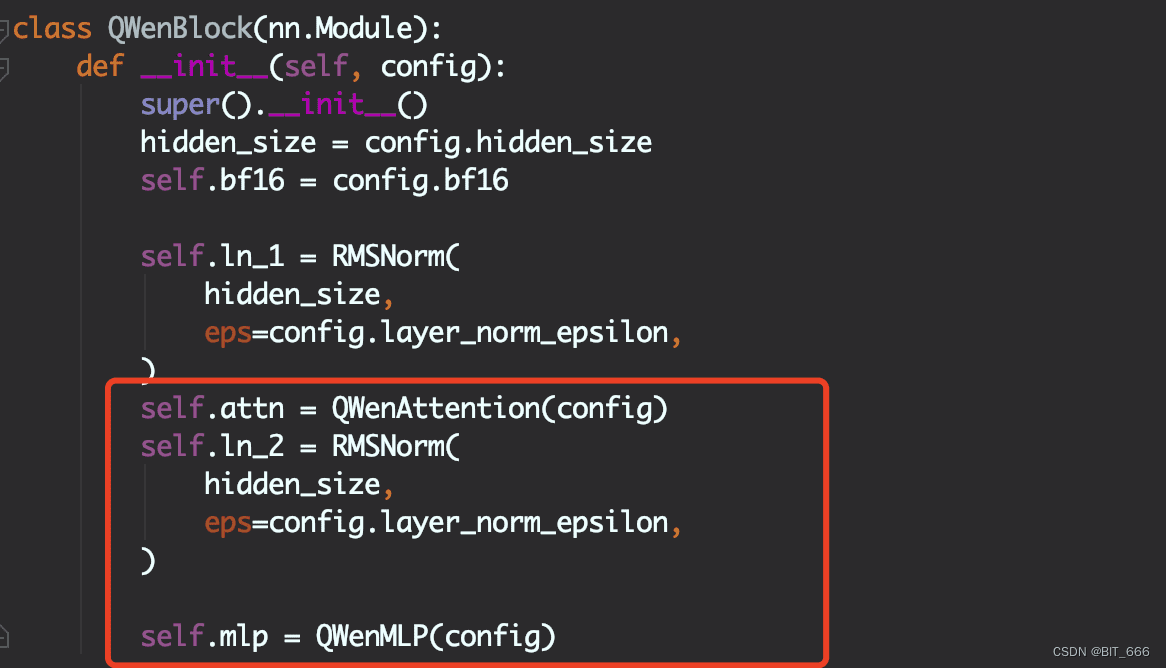
根据config的参数num_hidden_layers = 80,Qwen模型共计堆叠了80个Block。其中,每个Block是一个标准的Decoder-Only的结构,包含两个RMSNorm的归一化Layer、一个标准的Attention Layer以及最后的MLP深度部分。Block的前向逻辑计算也很清晰,除了Attention、RMSNormal外,还涉及到两个类似RNN的残差网络,以防止模型遗忘。
接下来,我们将介绍如何使用QLoRA技术对Qwen-72B-Chat模型进行指令微调和推理测试。由于模型尺寸庞大,我们采用QLoRA的训练方式,通过4-bit量化缩减模型占用的显存。此外,batch_size也不能设置太大,对于过长的文本容易在训练中引发OOM。lora_rank可以尝试16,学习率可以适当增加。使用上述配置,可训参数约占总参数量的0.087%。


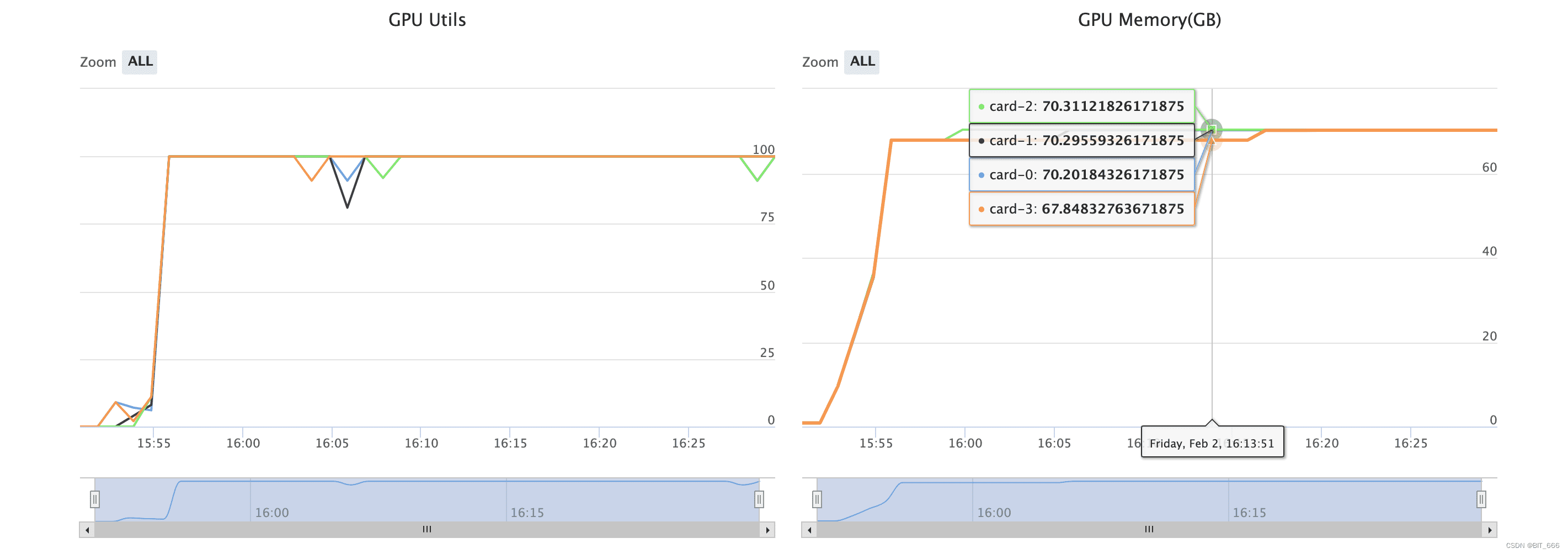
在模型训练过程中,我们使用了4 x A800的配置,训练期间显存几乎全部打满。
模型训练LOSS由4+经过3轮epoch下降至1.5左右,可以看到在每一个epoch结束后,loss会存在一个明显的向下阶跃。
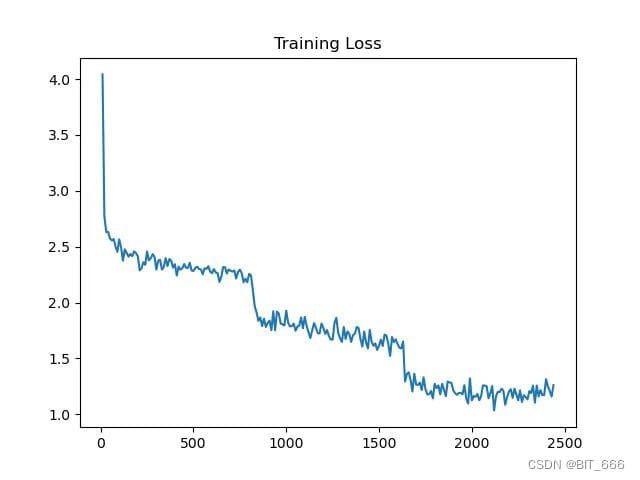
在推理测试方面,这里推理实测需要 A800 x 2,推理时显存几乎全部使用。实测 Qwen-72B-Chat 在微调 3 轮后已经在对应 SFT 语料上具备匹配 GPT-3.5 甚至更高尺寸模型的能力。
最后,我们分享了一个用于下载LLM模型的Python脚本。由于Qwen-72B-Chat下载速度缓慢且经常出错,所以这里使用了一个While True的循环,直到所有文件下载完毕才会退出循环。全部模型文件包含82个safetensors,总计约为135G。在脚本中导入HF镜像并执行上述脚本即可。
总而言之,国内的大模型竞争日趋激烈,未来将涌现出更多优秀的开源模型。在当前环境下,除了模型本身表达能力的提高外,拥有自己场景下独一无二的数据也至关重要。Data x LLM x GPU是未来大模型的发展方向,当然,最终还需要一个应用场景,从而实现AIGC的切实落地。