
在人工智能领域日新月异的今天,各种创新技术和产品层出不穷。本文将深入探讨近期AI领域的热点事件,分析其背后的技术逻辑和潜在影响,为开发者和研究者提供有价值的参考。
一、阿里巴巴通义万相开源VACE:视频编辑的创新引擎
阿里巴巴开源了通义万相Wan2.1-VACE,这被誉为首个开源的视频编辑统一模型。该模型支持多种分辨率和任务,旨在提供一站式的视频创作体验,通过多模态输入机制实现高效且灵活的视频编辑。通义万相的这一举措,无疑为视频创作领域注入了新的活力。

VACE模型的核心优势在于其强大的多功能性。它不仅支持文本到视频的生成,还允许通过图像参考进行生成,同时支持本地编辑和视频扩展。这种全面的功能组合,极大地提升了视频创作的效率和灵活性。
此外,VACE还具备强大的可控重写能力。基于人体姿态和运动流控制,它能够支持主体和背景的参考,从而实现高度定制化的视频编辑效果。这种精细的控制能力,使得用户可以轻松地实现各种创意想法。
为了实现统一的多模态输入,VACE引入了视频条件单元(VCU)的概念。VCU允许自由的任务组合和灵活的编辑,从而极大地简化了视频编辑流程。通过VCU,用户可以更加直观地控制视频的各个方面,从而创作出更具个性化的作品。
二、OpenAI升级ChatGPT:GPT-4.1的卓越代码能力
OpenAI近期推出了GPT-4.1及其轻量级版本GPT-4.1mini。新版本在代码能力和指令执行体验方面均有显著提升,同时优化了用户体验和多模态支持,进一步巩固了OpenAI在AI领域的领先地位。
GPT-4.1最引人注目的特点之一是其强大的代码能力。它能够更高效地处理复杂的编程需求,并且运行速度更快,使其成为开发者和指令处理场景的理想选择。无论是编写复杂的算法,还是调试现有的代码,GPT-4.1都能提供强大的支持。
GPT-4.1mini则是一款轻量级且高效的版本。它在资源受限的设备上也能流畅运行,为免费和付费用户提供了广泛的访问渠道。这使得更多的用户能够体验到GPT-4.1的强大功能,而无需担心设备性能的限制。
ChatGPT还增加了一些新功能,如长按复制、表格复制和流式传输,从而显著提升了用户体验。这些看似简单的功能,却极大地提高了用户在日常使用中的效率和便利性。
三、Stability AI发布超轻量级文本到语音模型:移动端的创新应用
Stability AI发布了一款名为“对抗性后训练加速快速文本到音频生成”的超轻量级文本到音频生成模型。该模型仅有341M参数,但却能在H100 GPU上以75毫秒的速度生成12秒的音频,在移动CPU上完成相同的任务也只需7秒。这种卓越的性能和强大的多样性,为移动创意应用带来了新的可能性。

ARC后训练方法是该模型的一大亮点。它不依赖于蒸馏技术,而是通过对抗性训练来提高模型生成速度和质量。这种创新的方法,使得模型在保持高质量输出的同时,还能实现极高的运行效率。
该模型的轻量级设计,使其能够支持本地移动操作,从而极大地提升了移动创意应用体验。用户可以在手机上直接进行文本到语音的转换,而无需依赖于云端服务器,从而保护了用户的隐私和数据安全。
此外,该模型还支持音频到音频的功能,从而实现风格迁移,激发更多的创意。用户可以通过该功能,将一种音频的风格应用到另一种音频上,从而创作出独具特色的作品。
四、Poe报告:科 लिंग大模型占据30%的视频生成量,领先Runway
Poe近期发布的《2025年春季AI模型使用趋势报告》显示,中国快手旗下的科灵多个视频生成模型在文本到视频领域表现出色,占据了30%的市场份额。其中,科灵2.0在4月份发布后的三周内,使用量占比达到了21%。自去年6月推出以来,科灵AI的全球用户已超过2200万,月活跃用户增长了25倍,生成了大量的视频和图像。
科灵大模型之所以能够取得如此优异的成绩,与其在技术上的不断创新密不可分。科灵团队致力于打造更高效、更智能的视频生成模型,以满足用户日益增长的需求。
科灵2.0模型的成功,也充分说明了市场对于高质量视频生成工具的迫切需求。随着短视频平台的兴起,越来越多的用户希望能够轻松地创作出高质量的视频内容。科灵大模型的出现,无疑为这些用户提供了强大的支持。
五、微软WizardLM团队加入腾讯,或整合入混元大模型研发体系
微软的人工智能研究团队WizardLM近期加入了腾讯AI Lab的“混元”团队,这标志着腾讯在大型模型领域的进一步发力。WizardLM团队不仅带来了多项技术突破,还通过开源模型展示了其强大的研发实力。

Hunyuan-TurboS0416模型首次使用了“混元”的命名,象征着该团队与腾讯的深度融合。这一举措,也表明了腾讯对于人工智能领域的坚定决心。
据悉,腾讯计划大幅增加在AI领域的投资,旨在在全球AI竞争中占据更 dominant 的位置。通过引进优秀的人才和技术,腾讯有望在人工智能领域取得更大的突破。
六、腾讯宣布将于5月16日发布混元图像2.0
腾讯混元大模型团队宣布,混元图像2.0将于5月16日发布。这将是腾讯在AI视觉领域的一次重要突破,其核心理念是“更智能、更开放、更中国化”。

混元图像2.0的发布,将为创作者和企业进入AI驱动的视觉生产时代提供强大的助力。通过更智能的算法和更开放的平台,用户可以更加轻松地创作出高质量的图像内容。
继去年混元大模型的升级之后,腾讯再次展示了其在人工智能领域的持续创新能力。混元图像2.0的发布,也预示着腾讯将在AI视觉领域迎来新的发展机遇。
七、上海发起人工智能标识生态联盟,小红书和MiniMax作为首批成员加入
上海近期发起了人工智能标识生态联盟,旨在推动人工智能领域标识技术的发展,提高生成内容的透明度和安全性,并通过政策解读和企业合作,为构建可信赖的AI环境奠定基础。

该联盟由上海市委网信办指导,汇聚了众多知名企业,旨在提升AI生成内容的透明度和安全性。通过统一的标识体系,用户可以更加清晰地了解内容的来源和生成方式,从而更好地判断其真实性。
国家互联网应急中心和中国电子技术标准化研究院对相关政策进行了解读,强调了国际规则与中国特色的结合。这表明中国在人工智能治理方面,正在积极探索符合自身国情的发展道路。
小红书、MiniMax等公司参与了标识工作实践,探索各种内容识别解决方案,并积累治理经验。这些实践经验,将为联盟的进一步发展提供宝贵的参考。
八、Lightricks发布LTX-Video-13B Refined模型!10秒生成高质量AI视频,速度与质量双重飞跃
以色列科技公司Lightricks发布了一款开源AI视频生成模型LTX-Video-13B Refined模型。该模型基于130亿参数,结合了多尺度渲染技术和高效量化优化,将视频生成速度提升至10秒以内,同时保持了高质量的输出。

LTX-Video-13B Refined模型采用了多尺度渲染技术,从而实现了在短时间内生成高清晰度视频的目标。相比于传统的视频生成方法,该模型的速度提升了5倍以上。
作为一款开源模型,LTX-Video-13B Refined模型支持低内存设备运行,从而降低了AI视频制作的成本。这使得更多的用户能够体验到AI视频生成的乐趣,而无需购买昂贵的硬件设备。
该模型的生成速度提高了30倍,堪比专业电影作品,有望重塑内容创作生态。通过LTX-Video-13B Refined模型,用户可以更加轻松地创作出高质量的视频内容,从而在社交媒体上获得更多的关注。
九、谷歌AlphaEvolve发布!Gemini自进化AI解决数学难题,优化芯片和数据中心,训练速度飙升32.5%
谷歌DeepMind近期发布了AlphaEvolve,这是一款结合了Gemini大型语言模型和进化算法的AI编码代理。AlphaEvolve在数据中心调度、芯片设计、AI训练和数学研究等多个领域展示了强大的自优化能力。

AlphaEvolve通过结合Gemini和进化算法,成功解决了芯片优化和数学难题等复杂问题。这表明人工智能在解决复杂问题方面,具有巨大的潜力。
AlphaEvolve优化了数据中心调度,从而回收了0.7%的全球计算能力,节省了运营成本。这对于大型科技公司来说,具有重要的经济意义。
此外,AlphaEvolve还提高了AI训练效率。Gemini模型的训练速度提高了32.5%,这充分展示了其强大的自优化能力。通过不断地学习和进化,AlphaEvolve有望在未来取得更大的突破。
十、腾讯元宝浏览器插件Chrome Beta版上线
腾讯元宝浏览器插件的Chrome Beta版本近期上线,提供了浮动球、持久侧边栏和选词工具栏等功能,旨在提高网页浏览和信息处理效率。
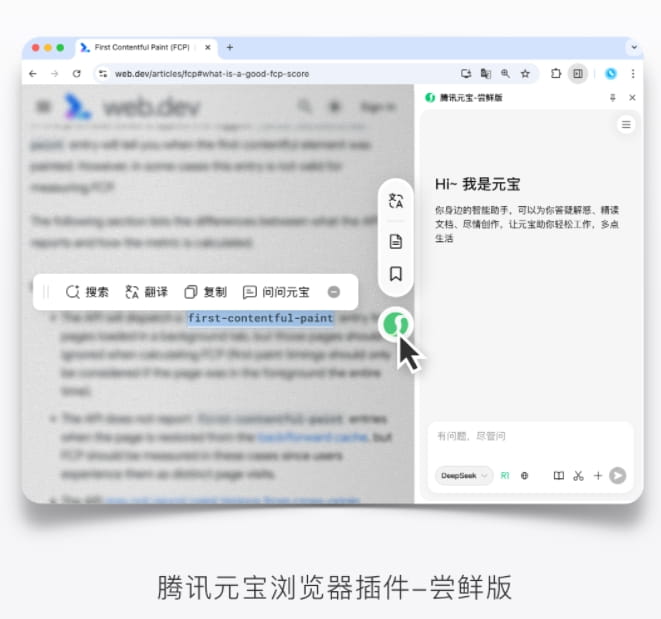
浮动球功能支持一键翻译和总结网页内容,从而轻松克服语言障碍,节省阅读时间。这对于需要阅读外文资料的用户来说,非常实用。
持久侧边栏可以高效地回答问题,支持截图提问,从而极大地提高了信息获取效率。用户可以通过侧边栏,快速地获取所需的信息,而无需在不同的网页之间切换。
选词工具栏允许在选择文本后立即进行搜索或翻译,从而使信息处理更加顺畅。这对于需要进行深入研究的用户来说,非常方便。
总的来说,近期人工智能领域涌现出了大量的创新技术和产品。这些技术和产品,不仅提高了效率,降低了成本,还为用户带来了更好的体验。随着人工智能技术的不断发展,我们有理由相信,未来的人工智能领域将会更加精彩。










