
在快速发展的人工智能领域,2025年无疑是充满机遇与变革的一年。从Kimi与小红书的合作到英伟达在音频处理上的突破,再到各大公司纷纷推出新的AI模型,技术创新层出不穷。本文将深入探讨这些最新动态,剖析其背后的技术逻辑与行业影响,带您一览AI领域的最新趋势。
Kuaishou的电商AI图像工具Poify
快手最新推出的AI图像工具Poify,无疑是电商领域的一大福音。这款工具专注于电商市场的图像处理,旨在提高商家在商品展示方面的效率和成本效益。Poify的核心功能包括文生图和图生图,特别适用于电商需求,例如AI模特试穿和背景替换等功能。这些功能不仅能帮助商家降低成本,还能显著提升商品的视觉吸引力。
Poify的推出,标志着快手正在积极抓住电商与AI融合的机遇。通过提供高效的AI图像解决方案,Poify能够满足电商领域多样化的商家需求。商家可以轻松生成高质量的商品展示图片,显著降低传统拍摄成本。这种创新不仅提升了商家的运营效率,也推动了整个电商行业的发展。
ByteDance的开源代码模型Seed-Coder
字节跳动发布的开源代码模型Seed-Coder,以其80亿参数和卓越的代码生成与推理能力,迅速引起了业界的广泛关注。Seed-Coder在多个基准测试中表现出色,展现出强大的编程潜力。其创新的数据处理方法和高效的训练策略,不仅提高了代码生成的质量,也为未来AI驱动的数据处理提供了新的思路。
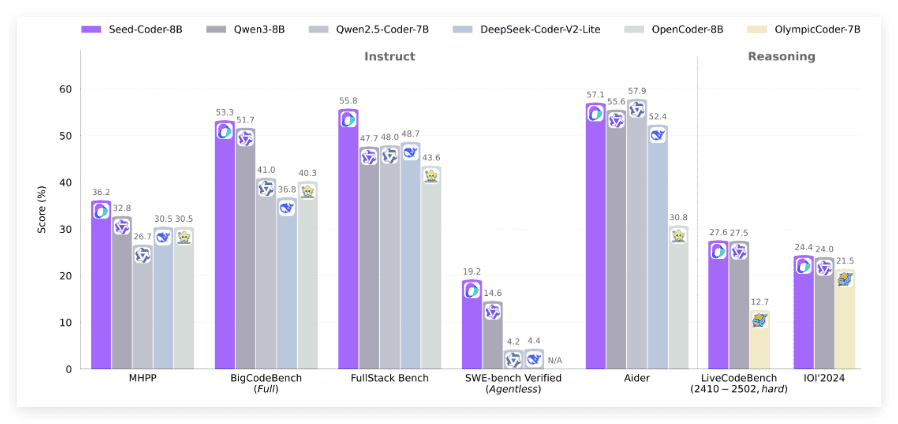
Seed-Coder支持32K上下文,专注于代码生成和软件工程任务。通过使用小型语言模型自动策划和过滤代码数据,显著减少了手动干预,提高了数据筛选的效率。在多个基准测试中,Seed-Coder展示了出色的代码修复和生成能力,成为领先的轻量级编程模型。这一开源举措,无疑将推动整个编程领域的技术进步。
DeepSeek App入选年度十大IP
2025年世界知识产权经济发展大会暨全球IP授权博览会在广州圆满落幕。本次博览会吸引了众多专家和业内人士的关注,并评选出了年度十大IP。经过专家评审和在线投票,最终确定了十部杰出作品。其中,“哪吒之魔海风云”凭借其出色的故事情节和精良的制作,成功入选。

DeepSeek App和音乐剧“敦煌召唤”等作品,也展现了中国文化创意产业的多元化发展。这些IP的成功入选,不仅是对其创意和制作水平的认可,也反映了中国文化创意产业的蓬勃发展态势。知识产权的保护与推广,对于激发创新活力、推动经济发展具有重要意义。
Anthropic的Claude AI API引入网络搜索功能
Anthropic最新发布的Claude AI API引入了网络搜索功能,实现了对网络信息的实时访问。这一创新显著提高了Claude在回答问题时的准确性,同时也给传统的搜索引擎带来了不小的压力。开发者可以利用这一功能构建更精确的智能代理,应用于金融、法律、开发者工具和生产力等领域。

Claude AI API的网络搜索功能,为智能代理的开发提供了更强大的支持。通过实时访问网络信息,智能代理可以提供更准确、更全面的答案,从而提升用户体验。这一功能的推出,无疑将推动AI技术在各行各业的广泛应用。
Apple的FastVLM模型
苹果公司正式推出了FastVLM,这是一款针对高分辨率图像处理进行优化的视觉语言模型。FastVLM具有极快的编码速度和卓越的性能,特别适合在移动设备上运行。其核心在于创新的FastViTHD编码器,通过动态分辨率调整和分层令牌压缩技术,显著提高了效率。
FastVLM通过FastViTHD编码器实现了85倍的编码速度提升,优化了高分辨率图像处理。在多模态任务中,FastVLM表现出色,尤其在SeedBench和TextVQA基准测试中表现突出。FastVLM的开源特性,将吸引更多开发者参与,推动苹果在视觉语言模型领域的技术创新和生态建设。
Tencent的PrimitiveAnything框架
腾讯与清华大学联合开发的PrimitiveAnything框架,旨在重新定义3D形状的抽象和生成。通过将复杂的形状分解为原始组件,该框架不仅提高了几何精度,还提高了学习效率。其自回归生成方法和大规模HumanPrim数据集,验证了该框架在重建精度和与人类抽象模式一致性方面的卓越性能,展现出强大的泛化能力,特别适用于高效的交互式3D应用。

PrimitiveAnything框架通过解码器转换器生成可变长度的原始组件序列,提高了3D形状生成的几何精度和学习效率。研究团队构建了大规模的HumanPrim数据集,以验证该框架在重建精度和与人类抽象模式一致性方面的卓越性能。该框架支持从文本或图像输入生成3D内容,允许用户轻松编辑结果,从而实现高质量的建模和存储节省。
智能文档处理基准IDP Leaderboard
智能文档处理领域迎来了一个重要的里程碑,首个视觉语言模型的统一基准测试IDP Leaderboard正式发布。该基准基于对9229份文档和16个数据集的评估,全面分析了主流模型在多个核心任务中的性能。尽管Gemini2.5Flash在整体实力上表现出色,但在OCR和分类任务中的表现却出人意料地低于预期,揭示了多模态推理能力与基本文本识别功能之间的权衡。

IDP Leaderboard评估了主流模型在六个核心任务中的性能,这些任务基于16个数据集和9229份文档。Gemini2.5Flash在整体实力上领先,但在OCR和分类任务中的表现却不如其前身,这突显了模型迭代中的平衡问题。长文档处理和表格提取仍然是视觉语言模型的短板;在这些任务中,最佳模型尚未突破70%的mark。
Google的Gemini 2.5 Pro实现6小时视频理解
谷歌的Gemini 2.5 Pro模型在视频理解方面取得了重大突破,支持长达6小时的视频分析和高达200万个token的上下文窗口。通过API解析YouTube链接,该模型在VideoMME基准测试中表现出色,准确率接近行业顶级水平。其应用范围涵盖教育、创意产业和商业分析,展示了AI视觉能力的新时代。

Gemini 2.5 Pro支持长达6小时的视频分析,上下文窗口为200万个token,实现了首个基于API的YouTube链接解析。在VideoMME基准测试中,该模型的准确率达到了84.7%,仅比行业顶级水平低0.5%。该模型可应用于教育、创意产业和商业分析,自动生成报告和交互式学习应用程序,从而提升用户体验。
用户提问方式影响AI模型准确性
最近的研究表明,当用户要求简短的答案时,许多语言模型更有可能生成不正确或误导性的信息。这项研究揭示了简洁请求对模型准确性的负面影响,特别是当用户使用自信的措辞时,这会显著降低模型的纠错能力。这种现象在不同的模型中差异显著,较小的模型受到的影响更大。

简短的请求会导致语言模型准确性的下降,幻想抵抗力可能会降低高达20%。用户的语气和措辞会影响模型的纠错能力;奉承效应可能会使模型不太愿意挑战错误信息。不同的模型在真实条件下表现不同,较小的模型更容易受到简短和自信措辞的影响。
全球首款AI智能浏览器Fellou发布
Fellou的发布标志着浏览器领域的一个重大变革,它成为全球首款具有AI驱动自动化功能的浏览器。它不仅可以执行传统的搜索和浏览,还可以思考、计划和执行复杂的任务,从而极大地提高了用户的工作效率。通过深度研究模式和工作流自动化,Fellou为研究人员、营销人员和开发人员提供了强大的支持,尤其是在跨平台协作和数据处理方面展现出巨大的潜力。

深度研究模式通过在后台并行搜索多个平台,自动生成完整的报告,其效率可与实习生团队相媲美。深度工作流模式允许用户通过自然语言指令自动化复杂的任务,从而提高效率并支持跨平台操作。在隐私保护方面,Fellou承诺不跟踪用户行为;所有数据处理都在本地进行,从而确保用户数据的安全。
NVIDIA AI推出Audio-SDS
英伟达的Audio-SDS技术将分数蒸馏采样(SDS)扩展到音频领域,显著提高了音效生成和声源分离能力。该技术支持多任务音频处理,使用户可以通过文本提示生成定制的音效,从而降低开发成本和时间。Audio-SDS的开源发布为创意产业和智能设备提供了新的可能性,标志着AI音频处理领域的一个重要里程碑。

Audio-SDS利用扩展到音频领域的SDS技术,支持适用于音效生成和声源分离的多任务处理。用户可以通过文本条件自定义声音设计,满足创意和工业需求,从而提升用户体验。开源策略促进了AI技术的普及,为开发者和中小型企业提供了低成本的音频处理解决方案。
Kimi加入小红书
Kimi与小红书的合作标志着AI大型模型在内容平台上的新尝试。尽管目前的入口尚未与其他小红书功能深度整合,但这种合作表明了Kimi在流量焦虑下的转型策略。未来,Kimi可能会通过将内容与社区相结合来增强用户粘性,尽管目前的功能仍然谨慎。双方的进一步合作仍有待观察。
Kimi与小红书合作,推出了Kimi智能助手账户,用户可以通过一键生成笔记。Kimi的流量预算在2025年第一季度减少到1.5亿元,这表明它正在从数量驱动的增长转向关注内容和社区战略。Kimi还与财新传媒合作,引入金融数据,探索可信回复的方向,进一步触达内容社区。
总结
2025年的人工智能领域,可谓是百花齐放,各领风骚。无论是电商图像处理、代码生成、知识产权保护,还是视频理解、音频处理和智能浏览器,AI技术正在以前所未有的速度渗透到我们生活的方方面面。面对如此快速的变革,我们既要积极拥抱创新,也要理性看待技术发展中的挑战,才能更好地把握AI带来的机遇。










