
在人工智能语音技术领域,Fish Audio 发布的开源文本转语音 (TTS) 模型 OpenAudio S1-Mini 标志着一个重要的进步。作为备受赞誉的 S1 模型的精简版本,S1-Mini 因其轻量级设计、高表现力和多语言支持而引发了行业讨论。该模型的发布为开发者社区带来了新的可能性,并有望加速 AI 语音技术在各个领域的应用。
OpenAudio S1-Mini 是一个从 4B 参数 S1 模型中提炼出来的轻量级版本,仅包含 0.5B 参数,显著降低了在边缘设备或本地化应用等资源受限环境中部署的计算要求。尽管减少了参数数量,S1-Mini 仍然保留了 S1 的核心优势,该模型在超过 200 万小时的大量音频数据集上进行训练,支持 14 种语言(包括中文、英语、日语、法语等),并且能够生成 50 多种情感和语气的语音表达。无论是愤怒、快乐、惊讶、笑声、哭泣声还是其他特殊效果,S1-Mini 都可以产生接近人类声音的自然发音,展现出强大的表现力。
S1-Mini 的开源发布是 OpenAudio 在实现 AI 语音技术民主化道路上迈出的重要一步。该模型可在 Hugging Face 平台上获得,允许开发者免费下载并在非商业场景中使用。与需要高额订阅费用的闭源 TTS 模型相比,S1-Mini 的开源性质大大降低了开发门槛,为小型团队和独立开发者提供了访问高质量文本转语音合成功能的机会。此外,OpenAudio 还提供了一个在线体验平台,供用户直观地感受模型的效果。这种开放战略不仅促进了技术迭代,还增强了社区信任,为语音 AI 的广泛应用奠定了基础。
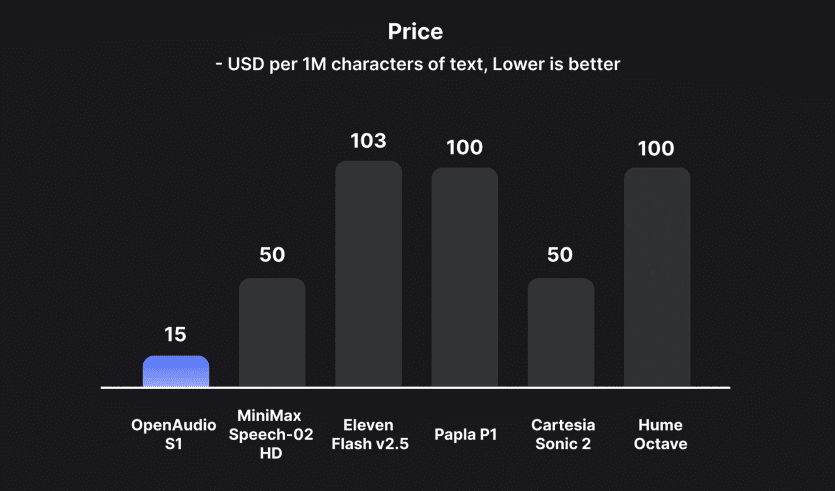
根据第三方基准测试(例如 Hugging Face 的 TTS Arena),OpenAudio S1 在性能上已经超越了 ElevenLabs 和 OpenAI 等竞争对手的某些模型,而 S1-Mini 作为其精简版本,在自然性和情感表达方面仍然表现出色。得益于 RLHF(Reinforcement Learning with Human Feedback,即基于人类反馈的强化学习)优化技术,S1-Mini 在生成连贯且情感丰富的语音方面表现出显著的效果,尤其是在多语言场景和复杂对话中脱颖而出。尽管目前不能用于商业目的,但其开源性质为学术研究和个人项目提供了重要价值。
S1-Mini 的轻量级设计使其适用于各种场景,包括教育领域的语言学习工具、娱乐行业的有声读物和播客生成,以及互动应用中的语音合成。它对特殊音效(如笑声和喊叫声)的支持为内容创作者提供了更多的创作空间。此外,其多语言支持使其在全球市场中具有竞争优势,尤其是在非英语语言的语音生成领域显示出潜力。AIbase 认为,S1-Mini 的发布将进一步促进开源 TTS 技术在全球范围内的普及和创新。
展望未来,OpenAudio S1-Mini 的发布不仅为开发者提供了高效的工具,也为 Fish Audio 的开源生态系统注入了新的活力。未来,Fish Audio 计划不断优化 S1-Mini 的性能,并可能发布支持更多语言和实时应用的版本。AIbase 预测,随着开源社区的参与,S1-Mini 将加速语音技术的迭代,挑战现有商业模型的垄断地位,并为行业带来更多可能性。
OpenAudio S1-Mini 的技术特点分析
OpenAudio S1-Mini 模型的成功,不仅仅在于其参数量的精简,更在于其在技术上的多重创新,使其在保证性能的同时,实现了轻量化和高效率。以下将从模型架构、训练方法和优化策略三个方面,深入分析 S1-Mini 的技术特点。
模型架构:高效 Transformer 结构
S1-Mini 基于 Transformer 架构,但为了减少计算量和模型大小,采用了以下优化策略:
- 知识蒸馏:通过知识蒸馏技术,将大型 S1 模型的知识迁移到小型 S1-Mini 模型中,使得 S1-Mini 在参数量减少的情况下,仍然能够保持较高的性能水平。具体来说,S1 模型作为“教师”模型,S1-Mini 作为“学生”模型,通过最小化两者输出的差异,使得 S1-Mini 学习到 S1 模型的表达能力。
- 层数缩减:减少 Transformer 模型的层数,从而降低模型的复杂度和计算量。但为了避免性能下降,OpenAudio 可能采用了更高效的注意力机制和残差连接,以弥补层数减少带来的信息损失。
- 参数共享:在模型的不同层之间共享参数,进一步减少参数量。这种方法可以有效地降低模型的存储需求,并提高模型的泛化能力。
训练方法:大规模数据与多语言支持
S1-Mini 的训练数据来源于超过 200 万小时的音频数据集,涵盖了 14 种语言。大规模的数据训练是保证模型性能的关键。为了更好地利用这些数据,OpenAudio 采用了以下策略:
- 数据增强:通过对原始音频数据进行各种变换,如添加噪声、调整语速、改变音调等,增加数据的多样性,提高模型的鲁棒性。数据增强可以有效地防止模型过拟合,提高模型的泛化能力。
- 多语言混合训练:将不同语言的音频数据混合在一起进行训练,使得模型能够学习到不同语言之间的共性和差异。这种方法可以提高模型的多语言支持能力,使得模型在处理不同语言的文本时,都能够产生高质量的语音。
优化策略:RLHF 与情感控制
S1-Mini 采用了 RLHF 技术,通过人类反馈来优化模型的输出。具体来说,OpenAudio 收集了大量的人类评价数据,用于训练一个奖励模型。该奖励模型用于评估 S1-Mini 生成的语音质量,并根据评估结果调整模型的参数。这种方法可以有效地提高模型的自然性和情感表达能力。
此外,S1-Mini 还支持 50 多种情感和语气的语音表达。为了实现这一目标,OpenAudio 可能采用了以下技术:
- 情感嵌入:将情感信息嵌入到文本输入中,使得模型能够根据不同的情感输入,生成具有相应情感的语音。情感嵌入可以通过预训练的情感分类器来实现。
- 风格迁移:借鉴风格迁移的思想,将不同风格的语音特征迁移到 S1-Mini 模型中,使得模型能够生成具有不同风格的语音。风格迁移可以通过对抗训练来实现。
OpenAudio S1-Mini 的应用前景展望
OpenAudio S1-Mini 作为一款轻量级、高性能的 TTS 模型,具有广泛的应用前景。以下将从教育、娱乐、人机交互三个方面,探讨 S1-Mini 的潜在应用场景。
教育领域:个性化语言学习助手
S1-Mini 可以应用于语言学习工具中,为学生提供个性化的语音学习体验。例如,S1-Mini 可以根据学生的学习进度和水平,生成不同难度和风格的语音材料。此外,S1-Mini 还可以模拟不同的口音和语调,帮助学生提高听力和口语能力。
具体应用场景包括:
- 在线教育平台:S1-Mini 可以为在线教育平台提供高质量的语音合成服务,使得学生能够更好地理解和掌握课程内容。
- 语言学习 App:S1-Mini 可以集成到语言学习 App 中,为用户提供个性化的语音学习体验。
- 智能语音词典:S1-Mini 可以为智能语音词典提供清晰、准确的发音,帮助用户学习单词和短语。
娱乐领域:沉浸式内容创作工具
S1-Mini 可以应用于娱乐内容创作中,为创作者提供更多的创作空间和灵感。例如,S1-Mini 可以用于生成有声读物、播客、游戏配音等。此外,S1-Mini 还可以模拟不同的角色声音,为创作者提供更多的角色选择。
具体应用场景包括:
- 有声读物制作:S1-Mini 可以为有声读物制作提供高质量的语音合成服务,降低制作成本,提高制作效率。
- 播客节目制作:S1-Mini 可以为播客节目制作提供多样化的声音选择,增加节目的趣味性和吸引力。
- 游戏角色配音:S1-Mini 可以为游戏角色配音,提供更加生动、逼真的游戏体验。
人机交互领域:自然流畅的语音助手
S1-Mini 可以应用于人机交互领域,为用户提供更加自然、流畅的语音助手服务。例如,S1-Mini 可以用于智能家居、智能客服、语音导航等。此外,S1-Mini 还可以根据用户的情感状态,生成具有相应情感的语音回复,提高用户满意度。
具体应用场景包括:
- 智能家居控制:S1-Mini 可以集成到智能家居系统中,通过语音控制家电设备,提高生活便利性。
- 智能客服系统:S1-Mini 可以为智能客服系统提供自然、流畅的语音回复,提高客户满意度。
- 车载语音导航:S1-Mini 可以为车载语音导航系统提供清晰、准确的语音导航,提高驾驶安全性。
结论
OpenAudio S1-Mini 的发布,为 AI 语音技术的发展注入了新的活力。其轻量级设计、高性能表现和开源特性,使其在各个领域都具有广泛的应用前景。随着技术的不断进步和社区的不断参与,S1-Mini 有望成为 AI 语音技术领域的一颗耀眼明星,为人们的生活带来更多便利和乐趣。










