
在机器人技术领域,Hugging Face开源的SmolVLA模型无疑是一个引人注目的创新。这款轻量级的视觉-语言-行动(VLA)模型,以其高效的设计和强大的功能,为机器人技术的普及和发展带来了新的可能性。更令人兴奋的是,SmolVLA完全基于开源数据集训练,这意味着开发者可以更容易地获取、使用和定制这个模型,进一步推动机器人技术的创新。
SmolVLA:轻量级机器人模型的典范
SmolVLA模型拥有4.5亿参数,这使得它在保持高性能的同时,又足够小巧,可以在CPU上运行,甚至可以在单个消费级GPU上进行训练。这种低资源消耗的特性,使得SmolVLA非常适合在资源有限的环境中部署,例如移动机器人或嵌入式系统。想象一下,你可以在一台普通的MacBook上训练和部署一个强大的机器人模型,这在以前是难以想象的。
更重要的是,SmolVLA的设计目标是实现经济高效的机器人解决方案。这意味着它不仅在硬件资源上具有优势,还在数据和训练成本上具有优势。通过完全基于开源数据集进行训练,SmolVLA降低了开发者获取高质量训练数据的门槛,从而加速了机器人技术的开发进程。
SmolVLA的核心功能解析
SmolVLA之所以能够在机器人领域脱颖而出,离不开其强大的功能。它主要有以下几个核心功能:
- 多模态输入处理
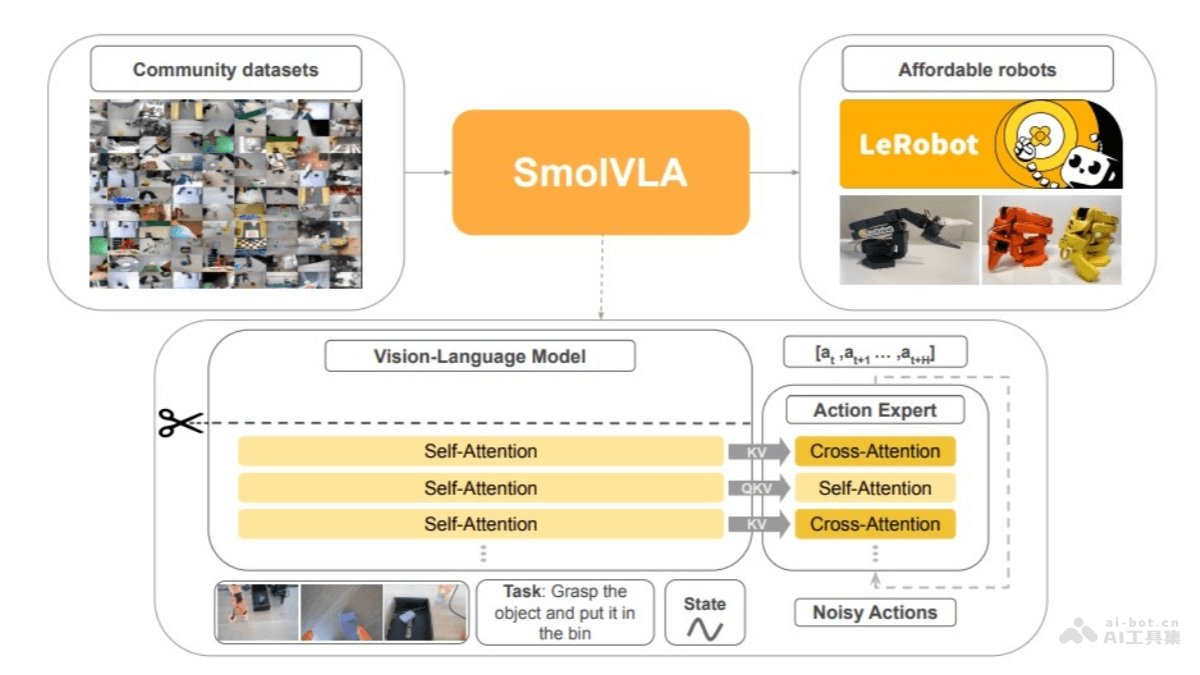
SmolVLA模型能够处理多种输入信息,包括多幅图像、自然语言指令以及机器人的状态信息。这种多模态输入处理能力,使得机器人能够更好地理解周围环境和人类指令,从而做出更智能的决策。具体来说,SmolVLA使用视觉编码器从图像中提取特征,将语言指令标记化后输入解码器,并将传感运动状态通过线性层投影到一个标记上,与语言模型的标记维度对齐。这种处理方式,使得不同类型的输入信息能够有效地融合在一起,为后续的动作生成提供更全面的信息。
举个例子,假设一个机器人需要完成“将桌子上的红色杯子放到厨房”的任务。SmolVLA可以通过摄像头获取桌子的图像,识别出红色杯子的位置和形状。同时,它还可以理解“放到厨房”的自然语言指令,并结合自身的状态信息(例如当前位置和姿态),生成一系列的动作指令,最终完成任务。
- 动作序列生成
SmolVLA模型包含一个动作专家模块,这是一个轻量级的Transformer,能够基于视觉-语言模型(VLM)的输出,生成未来机器人的动作序列块。这个动作专家模块采用了流匹配技术进行训练,通过引导噪声样本回归真实数据分布来学习动作生成,从而实现高精度的实时控制。
动作序列生成是机器人控制的核心环节。它需要根据当前的环境信息和任务目标,生成一系列的动作指令, guiding机器人按照预定的轨迹运动。SmolVLA的动作专家模块通过学习大量的机器人动作数据,能够生成平滑、自然的动作序列,从而提高机器人的运动性能。
- 高效推理与异步执行
为了提高机器人的响应速度和任务吞吐量,SmolVLA引入了异步推理堆栈。这种堆栈将动作执行与感知和预测分离,使得机器人可以在执行当前动作的同时,开始处理新的观察并预测下一组动作。这种异步执行方式,消除了推理延迟,提高了控制频率,使得机器人可以在快速变化的环境中更快速地响应。
异步推理是机器人技术的一个重要发展方向。它可以让机器人更加灵活和高效地完成任务。SmolVLA的异步推理堆栈为机器人技术的发展提供了一个新的思路。
SmolVLA的技术原理深度剖析
SmolVLA之所以能够实现上述强大的功能,离不开其独特的技术原理。下面,我们将深入剖析SmolVLA的技术原理:
- 视觉-语言模型(VLM)
SmolVLA使用SmolVLM2作为其VLM主干。SmolVLM2模型经过优化,能够处理多图像输入。它包含一个SigLIP视觉编码器和一个SmolLM2语言解码器。图像标记通过视觉编码器提取,语言指令被标记化后直接输入解码器,传感运动状态则通过线性层投影到一个标记上,与语言模型的标记维度对齐。解码器层处理连接的图像、语言和状态标记,得到的特征随后传递给动作专家。
VLM是连接视觉和语言的关键桥梁。它能够将图像和语言信息融合在一起,使得机器人能够理解图像中的内容和人类的语言指令。SmolVLA选择SmolVLM2作为其VLM主干,充分利用了SmolVLM2在多模态信息处理方面的优势。
- 动作专家
动作专家是SmolVLA的核心组成部分。它是一个轻量级的Transformer(约1亿参数),基于VLM的输出,生成未来机器人的动作序列块。动作专家采用流匹配技术进行训练,通过引导噪声样本回归真实数据分布来学习动作生成,实现高精度的实时控制。
流匹配技术是一种先进的生成模型训练方法。它可以让模型学习到复杂的数据分布,从而生成高质量的动作序列。SmolVLA的动作专家模块通过采用流匹配技术,能够生成平滑、自然的动作序列,从而提高机器人的运动性能。
- 视觉 Token 减少
为了提高效率,SmolVLA限制每帧图像的视觉Token数量为64个,大大减少了处理成本。
视觉Token数量的减少,可以显著降低计算复杂度,提高模型的运行速度。SmolVLA通过限制视觉Token数量,实现了在保持性能的同时,降低计算成本的目标。
- 层跳跃加速推理
SmolVLA跳过VLM中的一半层进行计算,有效地将计算成本减半,同时保持了良好的性能。
层跳跃是一种有效的模型加速技术。它可以减少模型的计算量,从而提高模型的推理速度。SmolVLA通过层跳跃技术,实现了在保持性能的同时,降低计算成本的目标。
- 交错注意力层
与传统的VLA架构不同,SmolVLA交替使用交叉注意力(CA)和自注意力(SA)层。提高了多模态信息整合的效率,加快推理速度。
交错注意力层是一种创新的注意力机制。它可以让模型更好地整合多模态信息,从而提高模型的性能。SmolVLA通过采用交错注意力层,实现了在提高性能的同时,加快推理速度的目标。
- 异步推理
SmolVLA引入了异步推理策略,让机器人的“手”和“眼”能独立工作。在这种策略下,机器人可以一边执行当前动作,一边已经开始处理新的观察并预测下一组动作,消除推理延迟,提高控制频率。
异步推理是机器人技术的一个重要发展方向。它可以让机器人更加灵活和高效地完成任务。SmolVLA的异步推理策略为机器人技术的发展提供了一个新的思路。
SmolVLA的应用场景展望
SmolVLA模型的强大功能和高效设计,使其在各种机器人应用场景中都具有广泛的应用前景。以下是一些典型的应用场景:
- 物体抓取与放置
SmolVLA可以控制机械臂完成复杂的抓取和放置任务。例如,在工业生产线上,机器人需要根据视觉输入和语言指令,准确地抓取零件并将其放置到指定位置。SmolVLA可以通过其多模态输入处理能力,准确地识别零件的位置和形状,并理解人类的语言指令,从而生成精确的动作序列,完成抓取和放置任务。
- 家务劳动
SmolVLA可以应用于家庭服务机器人,帮助完成各种家务劳动。例如,机器人可以根据自然语言指令,识别并清理房间中的杂物,或者将物品放置到指定位置。SmolVLA可以通过其强大的视觉识别能力和自然语言理解能力,理解人类的需求,并执行相应的家务劳动。
- 货物搬运
在物流仓库中,SmolVLA可以控制机器人完成货物的搬运任务。机器人可以根据视觉输入识别货物的位置和形状,结合语言指令,生成最优的搬运路径和动作序列,提高货物搬运的效率和准确性。SmolVLA可以通过其高效的路径规划和动作生成能力,优化搬运路径,减少搬运时间,提高搬运效率。
- 机器人教育
SmolVLA可以作为机器人教育的工具,帮助学生和研究人员更好地理解和开发机器人技术。SmolVLA的开源特性,使得学生和研究人员可以更容易地获取、使用和定制这个模型,从而加速机器人技术的学习和研究。
结语
SmolVLA的开源,为机器人技术的发展注入了新的活力。我们有理由相信,在SmolVLA的推动下,机器人技术将迎来更加广阔的发展前景。无论是工业生产、家庭服务,还是物流运输、教育科研,机器人都将在我们的生活中扮演越来越重要的角色。
让我们共同期待SmolVLA在未来的机器人领域大放异彩!

