
在历史研究的浩瀚领域中,人工智能正逐渐崭露头角,成为研究者们探索过去、理解现在的得力助手。由普林斯顿大学 AI 实验室与复旦大学历史学系联合推出的 HistAgent,正是这样一款专为历史研究设计的人工智能助手系统。它旨在解决历史研究中多模态信息处理、跨语言分析和复杂推理等难题,为历史研究注入新的活力。
HistAgent 的出现,弥补了传统历史研究在处理海量、复杂历史资料方面的不足。它能够处理手稿、图像、音频、视频、铭文和文本等多种历史资料,支持 29 种古今语言,涵盖从古代到现代的多种历史时期和世界不同地区的内容。更重要的是,HistAgent 在专门设计的历史推理评测基准 HistBench 上,表现显著优于通用大语言模型和其他 AI Agent,这充分证明了其在历史研究领域的专业性和有效性。
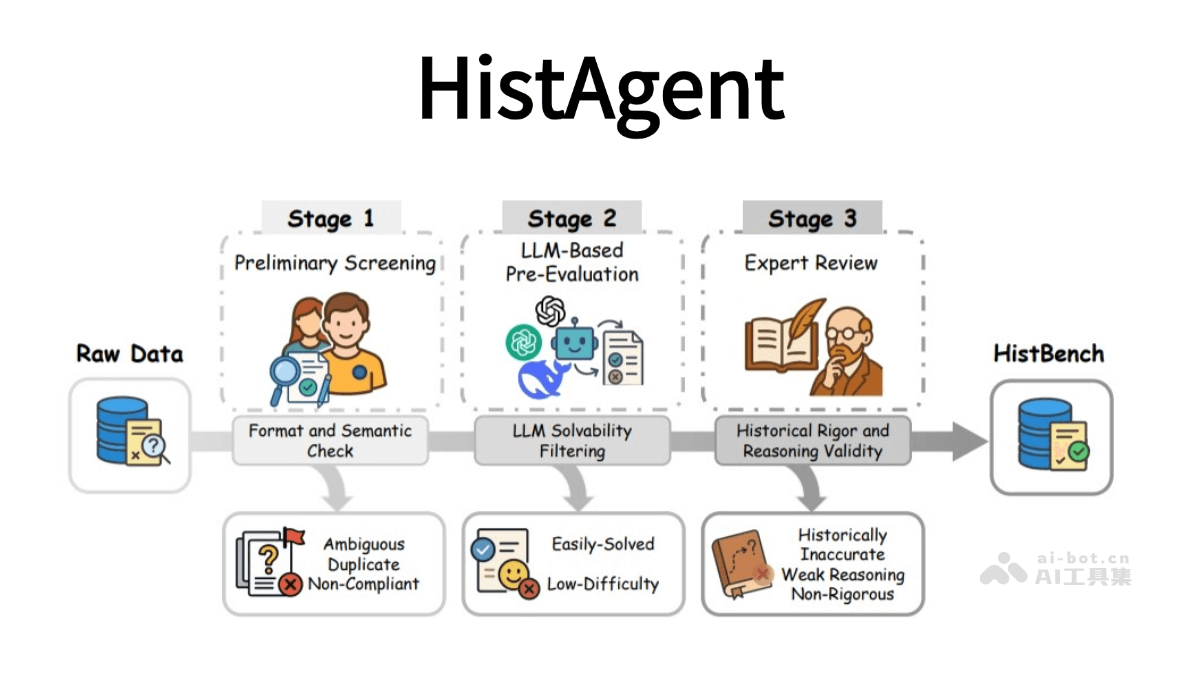
HistAgent 的核心功能
HistAgent 的强大功能主要体现在以下几个方面:
多模态资料处理
历史研究涉及的资料形式多样,包括手稿、图像、地图、音频、视频等。HistAgent 能够有效地处理这些不同模态的资料。例如,通过 OCR 模块,HistAgent 可以识别手稿和碑铭等文档中的文字,将这些珍贵的历史记录转化为可编辑、可搜索的文本数据。此外,HistAgent 还支持图片反向搜索和文物识别,帮助研究者们追溯历史图像的来源,还原历史文物的背景信息。对于历史演讲和访谈记录等音频材料,HistAgent 也能进行有效的处理,提取关键信息。
多语言支持
语言是历史研究的重要载体。HistAgent 支持 29 种古今语言的翻译和处理,包括古典语言和小众语言。这使得研究者们能够跨越语言的障碍,更广泛地获取和理解历史资料。HistAgent 不仅能够翻译文本的表面意思,还能结合语境优化译文,确保翻译的准确性和流畅性。例如,在研究古希腊文献时,HistAgent 能够将古希腊语翻译成现代语言,帮助研究者们理解其中的思想和文化。
文献检索与文件解析
文献检索是历史研究的基础环节。HistAgent 支持多步网页搜索和页面解析,能够快速检索学术网站和历史资料。此外,HistAgent 还可以解析 PDF、DOCX、XLSX、PPTX 等多种格式的文件,方便研究者们整理和分析资料。
历史推理与信息整合
历史研究不仅仅是信息的收集,更重要的是对信息的整合和推理。HistAgent 能够结合历史知识辅助推理,帮助研究者们梳理线索、整合信息并形成学术判断。HistAgent 通过中央调度模块(Manager Agent)智能协调各个子模块,根据任务需求调用相应的工具,整合多模态结果,最终输出符合历史学科规范的完整回答。例如,在研究某个历史事件时,HistAgent 可以整合来自不同来源的资料,分析事件的起因、发展和影响,帮助研究者们形成全面的认识。
多智能体协作
HistAgent 是一个包含多个子模块的多智能体协作系统。它能够模拟历史研究的流程,将复杂任务拆解为不同的子任务,并根据每个子任务的需求调用最合适的工具。这种多智能体协作的模式,提高了 HistAgent 的工作效率和准确性。
HistAgent 的技术原理
HistAgent 能够实现上述功能,得益于其先进的技术原理:
多智能体架构
HistAgent 采用了多智能体系统(Multi-Agent System)的设计模式。这种架构将复杂的任务拆解为多个子任务,分配给不同的智能体(Agent)来处理。每个智能体专注于特定的任务,例如图像识别、语言翻译、文献检索等。通过这种方式,HistAgent 能够高效地处理多种类型的历史资料,整合不同模态的结果。
任务规划与执行是多智能体架构的关键环节。用户输入的查询首先被分解为多个子任务,每个子任务由相应的智能体执行。执行结果会经过观察和验证,如果结果不合格或出现错误,系统会重新规划并调整任务。
多视角分析与协同是多智能体架构的优势所在。每个智能体可以独立处理特定领域的问题,降低了对记忆和提示长度的要求。通过多智能体的协同工作,HistAgent 能够更全面、更深入地分析历史问题。
多模态处理技术
HistAgent 能够处理多种模态的历史资料,包括文本、图像、音频和视频。多模态处理技术的核心在于将不同模态的信息转化为统一的语义表示,方便进行进一步的分析和推理。
视觉处理是多模态处理的重要组成部分。HistAgent 通过计算机视觉(CV)模型(如 YOLOv8)对图像和视频进行处理,提取关键信息并转化为结构化描述,然后注入到大语言模型的上下文中。例如,在处理一张历史照片时,HistAgent 可以识别照片中的人物、建筑和事件,并将这些信息用于后续的分析。
语音处理是另一种重要的多模态处理技术。HistAgent 基于自动语音识别(ASR)技术(如 Whisper)将音频转换为文本,再通过大语言模型进行处理,最后通过语音合成(TTS)技术输出结果。这使得 HistAgent 能够处理历史演讲和访谈记录等音频材料,提取其中的关键信息。
知识增强与推理
为了提高推理的准确性和可靠性,HistAgent 采用了知识增强技术。通过将知识库中的文档向量化存储(如 ChromaDB),在处理用户查询时动态检索和注入相关知识。这种知识增强的方法,可以有效抑制大语言模型的幻觉问题,提高输出结果的可信度。
工具调用与扩展
HistAgent 支持动态调用外部工具和插件。通过工具调用模块,HistAgent 可以根据任务需求调用特定的 API 或工具,例如文献检索、文件解析等。这种工具调用机制,提高了系统的灵活性,支持开发者通过增加新的插件来扩展 HistAgent 的功能。
记忆系统
HistAgent 的记忆系统采用了混合记忆架构,包括短期记忆和长期记忆。短期记忆用于存储当前任务的上下文信息,长期记忆则通过向量数据库(如 ChromaDB)存储重要的历史信息。这种混合记忆架构,使得 HistAgent 能够更好地理解用户的问题,并提供更准确的答案。
HistAgent 的应用场景
HistAgent 在历史研究领域具有广泛的应用前景:
- 文献检索与分析:通过多步网页搜索和页面解析,检索学术网站和历史资料,提供权威背景信息和证据支持。
- 图像与文物识别:能进行图片反向搜索、文物识别,为历史图像材料寻找出处、补充背景。
- 历史推理与线索整合:结合历史知识辅助推理,帮助研究者梳理线索、整合信息并形成学术判断。
- 历史教学辅助:为教师提供丰富的历史资料和案例,辅助教学设计,提升教学效果。
- 文化遗产保护:通过图像识别和 OCR 技术,帮助保护和研究古籍、碑刻等文化遗产。
HistBench 的特点
HistBench 是普林斯顿大学 AI 实验室与复旦大学历史学系联合开发的全球首个专注于历史研究能力的 AI 评测基准。它具有以下特点:
- 高质量问题库:HistBench 数据集包含 414 道高质量的历史问题,这些问题由历史学者撰写,涵盖从基础史料读取到跨学科深度分析的多个层次。
- 多语言与多模态覆盖:基准涵盖 29 种古今语言,支持手稿、图像、音视频、历史文物等多种史料类型,真实模拟历史研究情境。
- 难度分级:问题分为三个难度等级,从基础的信息检索到复杂的多模态史料处理和跨学科分析。
- **Level 1(基础):**166题,由历史背景助理设计,聚焦基本信息检索和提取。
- **Level 2(进阶):**172题,由研究生撰写,要求在材料处理或逻辑推理上构成一定难度。
- **Level 3(挑战):**76题,由资深学者设计,涉及小/死语言语言读取、多模态史料处理和跨学科分析。
- 广泛的历史领域覆盖:涵盖 20 多个历史区域和 36 个子领域,包括古典时代研究、全球史、新文化史、艺术史、环境史、科学技术与医学史等。
HistAgent 的出现,为历史研究带来了新的可能性。它不仅能够提高研究效率,还能帮助研究者们更深入地理解历史,为人类文明的传承和发展做出贡献。随着人工智能技术的不断发展,我们有理由相信,HistAgent 将在历史研究领域发挥更大的作用。

