
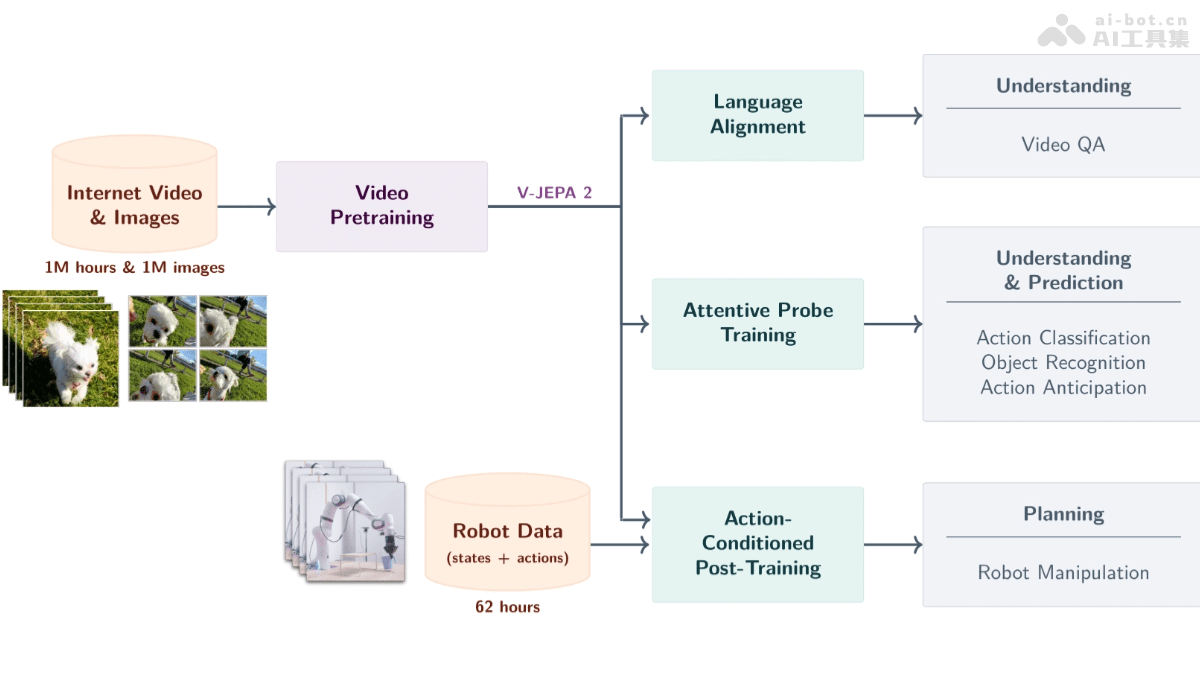
在人工智能领域,Meta AI 近期开源的 V-JEPA 2 模型引起了广泛关注。这款大型世界模型,通过对视频数据的深度学习,旨在实现对物理世界的理解、预测和规划。V-JEPA 2 基于联合嵌入预测架构(JEPA),拥有12亿参数,通过自监督学习,从超过100万小时的视频和100万张图像中汲取知识。它在动作识别、动作预测和视频问答等多个任务中表现出色,甚至能够应用于零样本机器人规划,使机器人在未知环境中与陌生物体互动。
那么,V-JEPA 2 究竟有哪些主要功能?它的技术原理又是如何实现的?本文将深入探讨这些问题,并展望其未来的应用前景。
V-JEPA 2 的主要功能
V-JEPA 2 的核心在于其对物理世界的深刻理解和预测能力。它能够从视频输入中理解物体、动作和运动,捕捉场景中的语义信息。更进一步,V-JEPA 2 能够基于当前状态和动作,预测未来视频帧或动作的结果,支持短期和长期预测。这种预测能力是其实现规划和控制的基础。例如,它可以用于零样本机器人规划,使机器人在新环境中完成任务,如抓取、放置和操作物体。
此外,V-JEPA 2 还可以与语言模型结合,回答与视频内容相关的问题。这些问题可能涉及物理因果关系、动作预测和场景理解等方面。更重要的是,V-JEPA 2 展现出强大的泛化能力,在未见过的环境和物体上也能表现良好,支持在新场景中的零样本学习和适应。这使得它在各种实际应用中具有巨大的潜力。
V-JEPA 2 的技术原理
V-JEPA 2 的技术原理主要包括自监督学习、编码器-预测器架构、多阶段训练、动作条件预测和零样本规划等几个方面。
首先,自监督学习是 V-JEPA 2 的基石。通过自监督学习,模型能够从大规模视频数据中学习通用的视觉表示,而无需人工标注数据。这种方法大大降低了数据准备的成本,并使模型能够从海量数据中提取有用的信息。
其次,V-JEPA 2 采用编码器-预测器架构。编码器负责将原始视频输入转换为语义嵌入,捕捉视频中的关键信息。预测器则基于编码器的输出和额外的上下文(如动作信息),预测未来的视频帧或状态。这种架构使得模型能够理解视频内容,并预测未来的发展趋势。
多阶段训练是 V-JEPA 2 的另一个关键技术。在预训练阶段,模型使用大规模视频数据训练编码器,学习通用的视觉表示。在后训练阶段,模型在预训练的编码器基础上,使用少量机器人交互数据训练动作条件预测器,使模型能够进行规划和控制。
动作条件预测是 V-JEPA 2 实现规划和控制的关键。通过引入动作信息,模型能够预测特定动作对世界状态的影响,支持基于模型的预测控制。这意味着模型可以根据不同的动作选择,预测不同的结果,并选择最优的动作序列来实现目标。
最后,V-JEPA 2 采用零样本规划。这意味着模型可以在新环境中进行零样本规划,基于优化动作序列来实现目标,而无需额外的训练数据。这种能力使得 V-JEPA 2 在各种未知环境中具有很强的适应性。
V-JEPA 2 的应用场景
V-JEPA 2 的应用场景非常广泛,涵盖了机器人控制与规划、视频理解与问答、智能监控与安全、教育与培训以及医疗与健康等多个领域。
在机器人控制与规划方面,V-JEPA 2 支持零样本机器人规划,使机器人能够在新的环境中完成抓取、放置等任务,而无需额外的训练数据。这大大降低了机器人部署的成本,并提高了其在各种环境中的适应性。
在视频理解与问答方面,V-JEPA 2 可以结合语言模型,回答与视频内容相关的问题,支持动作识别、预测和视频内容生成。这使得 V-JEPA 2 可以应用于各种需要视频理解的场景,如智能客服、视频搜索等。
在智能监控与安全方面,V-JEPA 2 可以检测异常行为和环境变化,应用于视频监控、工业设备监测和交通管理。通过对视频流的实时分析,V-JEPA 2 可以及时发现潜在的安全隐患,并发出警报。
在教育与培训方面,V-JEPA 2 可以应用于虚拟现实和增强现实环境,提供沉浸式体验和技能培训。例如,可以利用 V-JEPA 2 模拟各种 реальные场景,帮助学生和 профессионалы提高技能。
在医疗与健康方面,V-JEPA 2 可以辅助康复训练和手术操作,基于预测和分析动作提供实时反馈和指导。例如,可以利用 V-JEPA 2 监测病人的康复进度,并提供个性化的康复方案。
V-JEPA 2 的局限性与未来发展方向
尽管 V-JEPA 2 具有诸多优点,但它仍然存在一些局限性。例如,V-JEPA 2 的计算复杂度较高,需要大量的计算资源才能进行训练和推理。此外,V-JEPA 2 在处理 сложных场景时,可能仍然存在一定的误差。
未来,V-JEPA 2 的发展方向可能包括以下几个方面:
- 降低计算复杂度:通过模型压缩、量化等技术,降低 V-JEPA 2 的计算复杂度,使其能够在资源受限的设备上运行。
- 提高预测精度:通过引入更多的上下文信息、改进模型结构等方式,提高 V-JEPA 2 的预测精度。
- 增强泛化能力:通过使用更多样化的数据、采用更鲁棒的训练方法等方式,增强 V-JEPA 2 的泛化能力。
- 扩展应用场景:将 V-JEPA 2 应用于更多的领域,如自动驾驶、智能家居等。
结语
V-JEPA 2 作为 Meta AI 开源的世界大模型,在理解物理世界、预测未来状态以及规划和控制方面取得了显著的进展。虽然 V-JEPA 2 仍有进步空间,但其在机器人、视频理解、智能监控等领域的应用前景广阔,为人工智能的发展注入了新的活力。随着技术的不断进步,我们有理由相信,V-JEPA 2 将在未来发挥更加重要的作用。

