
字节跳动豆包大模型1.6:多模态深度思考的新里程碑
在人工智能领域,大型语言模型(LLM)的快速发展不断推动着技术的边界。字节跳动推出的豆包大模型1.6(Doubao-Seed-1.6)正是一款集多模态输入、深度思考和高质量输出于一体的先进模型。本文将深入探讨豆包大模型1.6的主要功能、性能表现、定价模式以及应用场景,为企业和开发者提供全面的了解。
豆包大模型1.6的核心功能
豆包大模型1.6不仅仅是一个语言模型,它更是一个多功能的AI工具,具备以下几个核心功能:
强大的推理能力:
豆包大模型1.6在推理速度、准确性和稳定性方面都得到了显著提升。这意味着该模型能够支持更为复杂的业务场景,从而满足企业在实际应用中的需求。例如,在金融领域,豆包大模型1.6可以用于风险评估和欺诈检测,其强大的推理能力能够更准确地识别潜在风险。
边想边搜与DeepResearch:
这一功能是豆包大模型1.6的一大亮点。它不仅具备传统的搜索能力,还能基于缺失信息进行主动搜索,并通过多轮思考和搜索给出最佳推荐。DeepResearch功能则支持快速生成高质量的调研报告,大大提升了研究效率。例如,市场分析师可以使用DeepResearch功能快速生成竞争对手分析报告,从而更好地了解市场动态。
多模态理解能力:
豆包大模型1.6全系列原生支持多模态思考能力,能够理解和处理文本、图像、视频等多种模态的数据。这意味着该模型可以应用于更广泛的场景,例如,在电商领域,豆包大模型1.6可以通过分析商品图片和用户评论,生成更具吸引力的商品描述。

图形界面操作能力(GUI操作):
豆包大模型1.6具备基于视觉深度思考与精准定位的图形界面操作能力,能够与浏览器及其他软件进行交互和操作,高效执行各类任务。例如,用户可以通过简单的指令,让模型自动完成网页表单的填写、数据录入等繁琐任务,从而节省大量时间和精力。
豆包大模型1.6的三大模型
豆包大模型1.6系列包含三个各具特色的模型,以满足不同用户的需求:
doubao-seed-1.6:全能综合型模型
这是豆包大模型1.6系列中的全能型选手,也是国内首个支持256K上下文的思考模型。它具备深度思考、多模态理解及图形界面操作等多项能力。用户可以根据需求灵活选择开启或关闭深度思考功能,同时支持自适应思考模式。自适应模式能够根据提示词的难度自动判断是否开启深度思考,在提升效果的同时,大幅减少tokens的消耗。例如,在内容创作场景中,用户可以使用该模型生成高质量的文章、博客或社交媒体帖子。
doubao-seed-1.6-thinking:深度思考强化版
该模型是豆包大模型1.6系列中专注于深度思考的强化版本。它在代码编写、数学计算、逻辑推理等基础能力上进行了进一步提升,能够处理更为复杂的任务。同时,该模型支持256K的上下文,能够理解和生成更长的文本内容,适合需要深度分析和复杂推理的场景。例如,在科研领域,研究人员可以使用该模型进行数据分析、模型构建和结果预测。
doubao-seed-1.6-flash:极速响应版本
该模型是豆包大模型1.6系列中的极速版本,具备深度思考和多模态理解能力,支持256K上下文。它的延迟极低,TOPT(Top-of-Pipeline Time)仅需10ms,能够快速响应用户的请求。该模型的视觉理解能力与友商旗舰模型相当,适合对响应速度要求极高的场景,例如实时交互和视觉任务处理。例如,在智能客服领域,该模型可以快速响应用户的问题,提供高效的客户服务。
豆包大模型1.6的卓越性能表现
豆包大模型1.6在多个权威测评中表现优异,证明了其强大的技术实力:
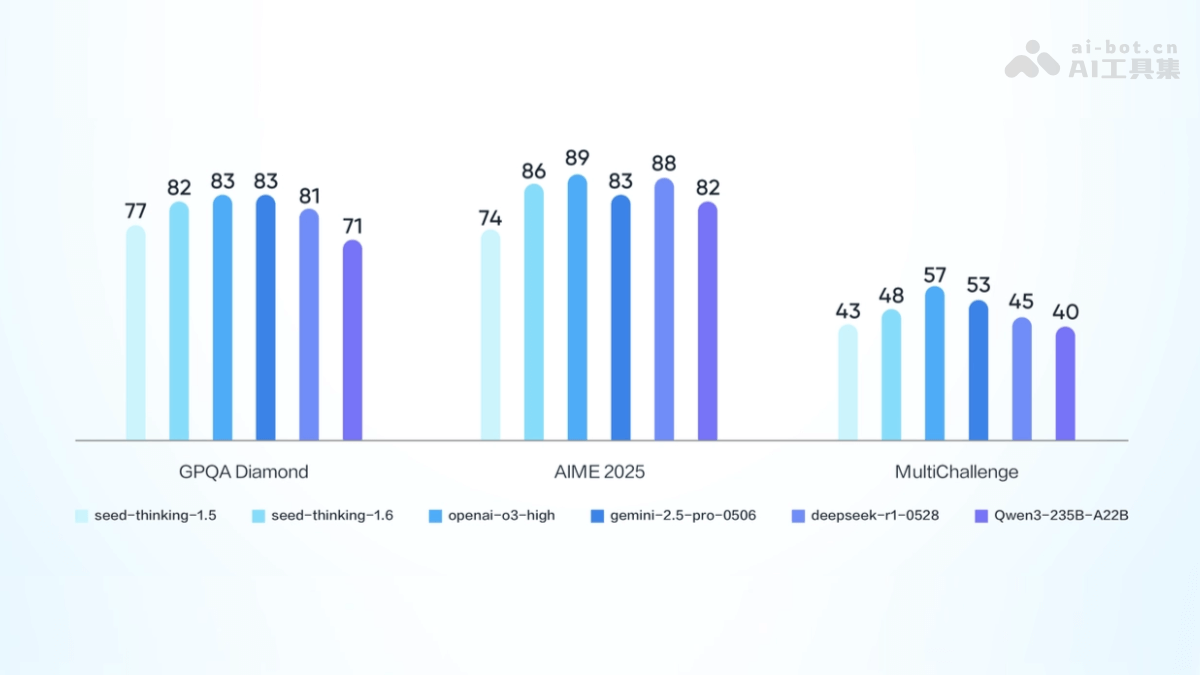
GPQA Diamond测试:
豆包1.6-thinking模型在该测试中取得了81.5分的成绩,达到全球第一梯队水平,是目前最好的推理模型之一。这表明该模型在处理复杂推理问题方面具有卓越的能力。
数学测评AIME25:
豆包1.6-thinking模型的成绩达到86.3分,相比豆包1.5深度思考模型提升了12.3分。这表明该模型在数学计算和问题解决方面取得了显著进步。
豆包大模型1.6的灵活定价模式
豆包大模型1.6采用了统一的定价模式,无论是否开启深度思考模式,无论是文本还是视觉输入,tokens价格均一致。这种定价模式简化了用户的计费方式,提高了使用的便捷性。
具体的定价如下:
- 输入长度0-32K:
- 输入价格:0.8元/百万tokens。
- 输出价格:8元/百万tokens。
- 输入长度32K-128K:
- 输入价格:1.2元/百万tokens。
- 输出价格:16元/百万tokens。
- 输入长度128K-256K:
- 输入价格:2.4元/百万tokens。
- 输出价格:24元/百万tokens。
- 输入32K、输出200 tokens以内:
- 输入价格:0.8元/百万tokens。
- 输出价格:2元/百万tokens。
如何高效使用豆包大模型1.6
要充分利用豆包大模型1.6的强大功能,可以按照以下步骤进行:
注册并登录火山引擎平台:
首先,访问火山引擎官方网站,按照提示完成注册和登录。火山引擎是豆包大模型1.6的官方服务平台,提供了全面的技术支持和文档。
开通豆包大模型服务:
登录后,进入服务页面,找到豆包大模型1.6的服务页面,并根据页面提示开通服务。
选择合适的模型版本:
根据实际需求选择合适的模型版本,例如doubao-seed-1.6、doubao-seed-1.6-thinking或doubao-seed-1.6-flash。不同的模型版本在性能和功能上有所差异,选择合适的版本可以更好地满足业务需求。
获取API密钥:
在开通服务后,平台会提供一个API密钥,用于在调用模型时进行身份验证。请妥善保管API密钥,避免泄露。
调用模型API:
豆包大模型1.6基于API接口进行调用。您需要构建请求数据,包括输入文本、参数设置等,并使用HTTP请求将数据发送到模型的API接口。模型处理完成后,会返回响应数据,包括生成的文本或其他结果。
Python示例代码:
以下是使用Python调用豆包大模型1.6的示例代码:
import requests
import json
api_key = "your_api_key"
api_secret = "your_api_secret"
model_version = "doubao-seed-1.6" # 或doubao-seed-1.6-thinking、doubao-seed-1.6-flash
api_url = f"https://api.volcengine.com/v1/model/{model_version}"
data = {
"input": "你的输入文本",
"parameters": {
"max_length": 256, # 输出的最大长度
"temperature": 0.7, # 随机性参数
"top_p": 0.9, # 核心采样参数
"top_k": 50, # 核心采样参数
"do_sample": True # 是否采样
}
}
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
response = requests.post(api_url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
result = response.json()
print("模型输出:", result["output"])
else:
print("请求失败,状态码:", response.status_code)
print("错误信息:", response.text)豆包大模型1.6的应用场景展望
豆包大模型1.6具有广泛的应用前景,以下是一些典型的应用场景:
内容创作:
豆包大模型1.6可以用于生成各种类型的文本内容,例如广告文案、新闻报道、故事、小说等。它可以帮助用户快速产出高质量的内容,从而提高工作效率。
智能对话:
豆包大模型1.6可以应用于智能客服和聊天机器人,提供自然流畅的多轮对话体验,提升用户交互效率。例如,在电商平台上,智能客服可以快速解答用户的问题,提供个性化的购物建议。
代码生成:
豆包大模型1.6可以根据需求生成前端代码片段,辅助开发者排查错误,提高开发效率。例如,开发者可以使用该模型快速生成HTML、CSS和JavaScript代码。
教育辅导:
豆包大模型1.6可以解答学科问题,生成教学资源,辅助学生学习和教师备课。例如,学生可以使用该模型解答数学题、语文题等,教师可以使用该模型生成教学PPT、练习题等。
多模态内容生成:
豆包大模型1.6可以结合图片或视频输入,生成相关文字描述或创意内容,助力多媒体创作。例如,用户可以上传一张风景照片,让模型生成一段优美的文字描述。
总结
字节跳动推出的豆包大模型1.6以其多模态输入、深度思考和高质量输出等特点,为人工智能领域树立了新的标杆。无论是企业还是开发者,都可以通过豆包大模型1.6提升工作效率、创新业务模式,从而在激烈的市场竞争中脱颖而出。随着技术的不断发展,我们有理由相信,豆包大模型1.6将在更多领域发挥重要作用,为人类带来更多便利和价值。

