
在科技的浪潮中,人工智能(AI)正以惊人的速度渗透到我们生活的方方面面。2025年6月6日,AI领域再次迎来一系列重大突破,预示着一个更加智能化、高效化的未来。本文将深入剖析当日发布的几项重要成果,带您一览AI技术的最新进展。
通义千问Qwen3-Embedding系列模型:多语言文本理解的飞跃
通义千问团队正式发布的Qwen3-Embedding系列模型,无疑是自然语言处理(NLP)领域的一颗璀璨新星。该模型基于Qwen3基础模型构建,提供了从0.6B到8B三种不同参数规模的配置,旨在满足各种应用场景下对性能和效率的需求。更令人瞩目的是,Qwen3-Embedding系列模型支持超过100种语言,具备强大的多语言、跨语言及代码检索能力。这种广泛的语言支持使其在处理全球化信息时具有显著优势。

在多语言文本嵌入基准测试(MTEB)中,Qwen3-Embedding系列模型取得了70.58分的优异成绩,超越了众多商业API服务,充分展示了其卓越的文本表征和排序能力。这一成就不仅证明了通义千问团队在AI技术研发方面的实力,也为全球开发者提供了更高效、更强大的文本处理工具。
Qwen3-Embedding系列模型的成功,离不开其独特的技术架构。该模型采用了双塔和单塔结构设计,能够灵活适应不同的任务需求。双塔结构适用于语义相似度计算和信息检索等任务,而单塔结构则更适合于文本分类和序列标注等任务。这种灵活的设计使得Qwen3-Embedding系列模型在各种NLP应用中都能发挥出色。
字节跳动SeedEdit 3.0:图像编辑的精细化革命
字节跳动发布的图像编辑模型SeedEdit 3.0,是基于Seedream 3.0开发的又一力作。该模型通过多样化数据融合和专用奖励模型,显著提升了主体保持、背景细节处理及指令遵循能力。尤其在人像编辑、背景更换和复杂光影处理方面,SeedEdit 3.0展现出了卓越的性能。
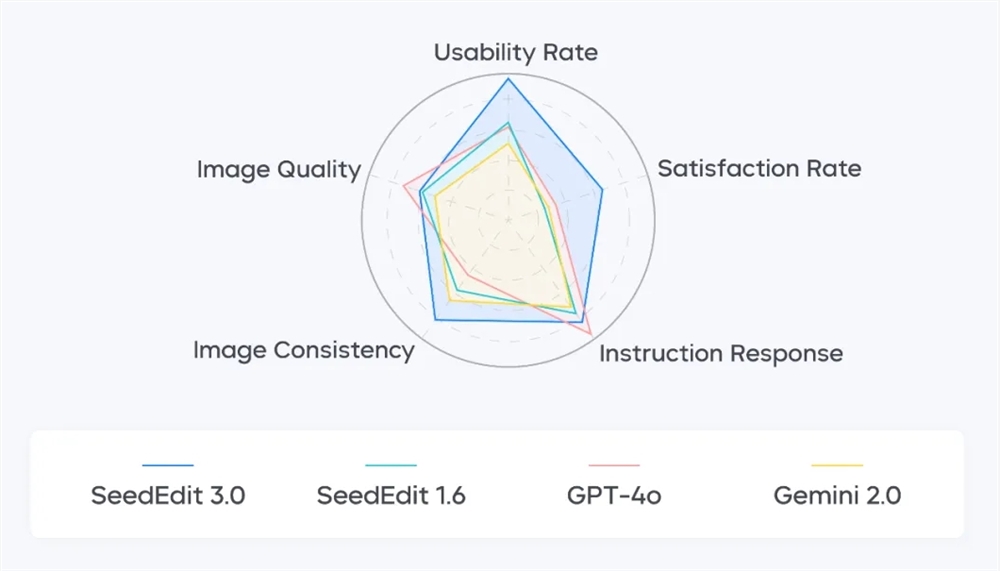
SeedEdit 3.0的一大亮点是其引入的高效数据融合策略与专用奖励模型。这些技术手段使得模型在进行图像编辑时,能够更好地保持图像的主体特征,同时精细处理背景细节,确保编辑后的图像既美观又自然。此外,SeedEdit 3.0还支持4K分辨率编辑,能够处理复杂场景如人像、光影变换,充分满足专业用户的需求。
在性能方面,SeedEdit 3.0的推理速度也得到了显著提升,达到了10秒级。在23类编辑任务评测中,SeedEdit 3.0均表现领先,可用率更是提升至56.1%。这些数据充分证明了SeedEdit 3.0在图像编辑领域的强大实力。
ElevenLabs v3Alpha版:AI语音的情感化飞跃
ElevenLabs推出的Eleven v3Alpha版,以其卓越的情感表达、多语言支持和自然对话能力,重新定义了文本转语音(TTS)技术。该模型不仅能够准确地将文本转化为语音,还能赋予语音丰富的情感,使其听起来更加自然、生动。
Eleven v3Alpha版的一大创新是引入了音频标签。通过这些标签,用户可以精确控制语音的情感、语速,并添加音效,从而使语音更具表现力。例如,用户可以使用“兴奋”标签来让语音听起来更加激动,或者使用“悲伤”标签来让语音听起来更加低沉。
此外,Eleven v3Alpha版还支持70多种语言,具备多角色对话能力,适用于影视配音、教育及客户服务等多种场景。无论是为电影配音,还是为在线课程制作语音讲解,Eleven v3Alpha版都能胜任。
Anthropic Claude Gov:国家安全领域的AI利器
Anthropic推出的Claude Gov模型套件,专为国家安全机构设计,旨在增强涉密材料处理能力。该产品获得了亚马逊和谷歌的战略支持,但同时也面临Reddit的法律诉讼,后者指控Anthropic未经授权使用用户数据训练模型。
Claude Gov模型套件的推出,标志着AI技术在国家安全领域的应用进入了一个新的阶段。该模型套件能够帮助国家安全机构更高效地处理涉密材料,提高情报分析的准确性和效率。然而,数据隐私问题也随之而来,Anthropic面临的法律诉讼就是一个警示。
可灵AI:商业化道路上的成功典范
可灵AI在推出10个月后,年化收入运行率突破1亿美元,P端付费订阅会员贡献了主要收入,全球用户规模突破2200万。这一成就证明了AI技术在商业化道路上的巨大潜力。
可灵AI的成功,离不开其精准的市场定位和优质的产品服务。通过提供P端付费订阅服务,可灵AI成功吸引了一批忠实用户,并实现了稳定的收入增长。同时,可灵AI还为企业客户提供API服务,进一步拓展了其商业版图。
Meta Aria Gen2:AR眼镜的技术革新
Meta首次全面披露了Aria Gen2研究眼镜的技术细节。相比初代产品,Aria Gen2在硬件设计、传感器技术和AI处理能力等方面实现了全面升级。这款眼镜配备了四摄像头,采用全局快门传感器解决运动失真问题,深度测量精度显著提高。
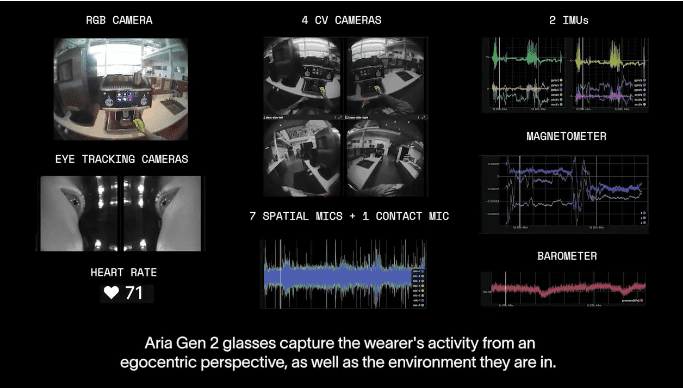
Aria Gen2还新增了接触式麦克风,鼻托内置结构声传导技术,即使在嘈杂环境下也能清晰拾音。此外,Aria Gen2的AI处理能力也得到了大幅增强,支持六自由度位置追踪、眼动追踪及3D手部追踪,为未来的增强现实(AR)交互奠定了基础。
爱诗科技PixVerse国内版“拍我AI”:视频创作的 democratization
爱诗科技旗下的PixVerse国内版“拍我AI”正式上线,支持网页端和移动端,并提供API开放平台,旨在大幅降低视频制作成本与时间。

拍我AI通过AI特效和WoW发射器,助力用户轻松创作个性化视频内容。国内版支持V4.5版本,提供便捷的视频生成解决方案,满足多种需求。此外,拍我AI还开放平台与多家头部企业合作,为企业用户提供高效视频生成工具。
富国银行预测:ChatGPT广告收入的未来
富国银行分析师预测,到2030年,ChatGPT将占据全球搜索广告市场30%的份额,年收入接近1000亿美元,这将对谷歌的主导地位构成挑战。这一预测引发了业界广泛关注。
目前,谷歌在搜索广告领域占据超过90%的市场份额,但预计到2030年将降至约60%。ChatGPT的商业化进程可能受到与手机制造商合作及反垄断裁决的推动。如果ChatGPT能够成功拓展其商业模式,那么它将成为谷歌在搜索广告领域的一个强大竞争对手。
王自如的AI创业之路
知名科技博主王自如宣布复更并更名为“王自如AI”,专注AI内容创业,助力传统产业数字化转型。同时,他还分享了在格力的经历及对董明珠和雷军的感激。
王自如选择AI领域创业,是因为看到了其巨大的潜力,认为能快速获得回报。他曾在格力重塑销售体系,得益于董明珠和雷军的鼓励,怀揣理想继续前行。我们期待他在AI领域取得更大的成就。
智源研究院的RoboOS2.0与RoboBrain2.0
在北京智源大会上,北京智源人工智能研究院发布了具身智能操作系统RoboOS2.0与大模型RoboBrain2.0,开源推动具身智能生态发展。这是AI技术在机器人领域的又一重要进展。
RoboOS2.0是首个支持MCP机制的机器人操作系统,降低了开发门槛,并提升了多机器人协作能力。RoboBrain2.0的任务规划准确率提升了74%,在空间推理与智能调度方面表现卓越。智源研究院已与多家企业合作,共同构建开放、协同的智能机器人生态体系。
谷歌Portraits:AI驱动的沟通与领导力学习
谷歌推出的Portraits是一款基于AI技术的创新产品,用户能与虚拟专家实时互动,学习沟通与领导力等技能,具有高度个性化和交互性的特点。这款产品为个人和职业发展提供了新的途径。
Portraits提供沉浸式对话学习体验,与虚拟专家互动掌握实用技能。AI驱动个性化学习,动态调整内容确保针对性。其应用场景广泛,从职场到教育,助力个人与职业发展。
OpenAudio S1-Mini:轻量级TTS模型的突破
Fish Audio推出基于S1模型的轻量化版本S1-Mini,参数仅0.5B,却具备高表现力和多语言支持,开源后大幅降低开发门槛,为教育、娱乐等领域带来创新可能。
S1-Mini采用轻量化设计,参数仅0.5B,适配边缘设备,支持14种语言与50+情感表达。开源赋能,免费下载,降低开发门槛,促进全球技术普及与创新。性能卓越,媲美行业巨头,尤其在多语言和复杂对话场景表现突出。
Diffusion Studio Pro:AI驱动的本地视频编辑工具
AI驱动的视频编辑工具Diffusion Studio Pro正式亮相,以其强大的AI功能和本地化设计受到广泛关注。它结合了CapCut和Cursor的优势,提供多模态AI赋能的非线性编辑体验,同时支持免费使用,极大降低了创作门槛。
Diffusion Studio Pro采用多模态AI赋能非线性编辑,内置智能代理侧边栏实现自动化工作流,显著提升创作效率。本地优先设计保护隐私,免费无限层级模式吸引独立创作者和小型团队。支持广泛应用场景,从短视频到专业制作,提供从创意到上线的全链条支持。
智源研究院的“悟界”系列大模型
在第七届“北京智源大会”上,智源研究院发布了“悟界”系列大模型,包括Emu3、见微Brainμ、RoboOS2.0、RoboBrain2.0和OpenComplex2,涵盖多模态智能技术,推动人工智能应用落地。
Emu3作为原生多模态世界模型,整合视觉、听觉和触觉数据,提升机器对世界的理解能力。见微Brainμ结合神经科学成果,为机器智能发展提供生物学支持。RoboOS2.0和RoboBrain2.0推动具身智能协作框架,加速机器人技术进步。
Luma Labs Modify Video:AI视频后期一键换风格
Luma Labs推出Modify Video工具,利用AI技术简化视频后期制作,实现风格重塑、场景替换等功能。
Modify Video支持风格重塑,通过文本改变视频艺术风格。场景替换,将背景换为新的场景,增强视觉效果。角色编辑,调整人物外观和表演,无需重新拍摄。
总而言之,2025年6月6日这一天,AI领域呈现出百花齐放的景象。从自然语言处理到图像编辑,从语音合成到机器人技术,AI正在以惊人的速度改变着我们的世界。我们有理由相信,在不久的将来,AI将会在更多领域发挥重要作用,为人类带来更加美好的未来。

