
OmniAvatar,由浙江大学与阿里巴巴联袂打造,是一款划时代的音频驱动全身视频生成模型。它不仅能根据输入的音频生成逼真的全身动画视频,还能确保人物动作与音频的精准同步,并赋予角色丰富的表情。该模型巧妙地融合了像素级多级音频嵌入策略与LoRA训练方法,显著提升了唇部同步的精确度与全身动作的自然度。更令人 впечатляющим的是,OmniAvatar还支持人物与物体的互动、背景的自由控制以及情绪的细腻表达,使其在播客、互动视频、虚拟场景等多元领域拥有广阔的应用前景。
在数字内容创作领域,高质量的虚拟形象和动画视频的需求日益增长。传统的动画制作流程繁琐且成本高昂,而OmniAvatar的出现,为解决这些痛点提供了全新的可能性。通过结合先进的AI技术,OmniAvatar能够高效地生成逼真、自然的全身动画视频,极大地降低了制作门槛和成本,为内容创作者带来了前所未有的便利。
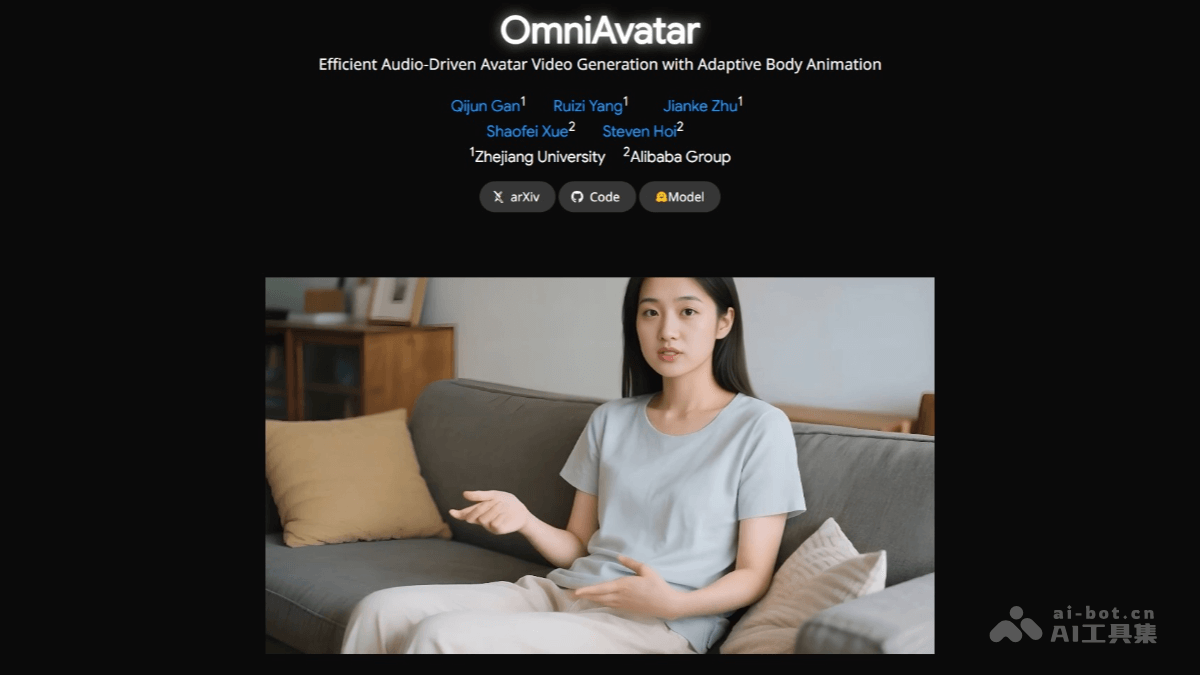
OmniAvatar的核心功能
OmniAvatar之所以能够在众多视频生成模型中脱颖而出,得益于其卓越的功能特性:
自然唇部同步:这是OmniAvatar的一大亮点。它能够生成与音频内容完美同步的唇部动作,即便在复杂的场景下,也能保持极高的准确性。这种高度的同步性,让生成的视频更加逼真自然,提升了观看体验。
在实际应用中,无论是制作虚拟播客还是互动视频,精准的唇部同步都能确保观众更好地理解内容,增强互动感和沉浸感。传统的唇部同步技术往往难以应对复杂场景,而OmniAvatar通过先进的算法,克服了这一难题,实现了在各种场景下的高精度唇部同步。
全身动画生成:除了唇部同步,OmniAvatar还能生成流畅自然的全身动作。这些动作不仅真实,而且富有表现力,使得动画角色更加生动逼真。通过对人物姿态、动作幅度以及肢体协调性的精确控制,OmniAvatar能够创造出令人信服的动画效果。
例如,在虚拟现实应用中,逼真的全身动画能够显著提升用户的沉浸感和互动体验。用户可以通过OmniAvatar创建个性化的虚拟形象,并在虚拟环境中进行自然的互动和交流。
文本控制:OmniAvatar支持基于文本提示的视频内容控制。用户可以通过简单的文本指令,精确地控制视频中的人物动作、背景以及情绪等元素,实现高度定制化的视频生成。这种强大的文本控制能力,使得OmniAvatar能够满足各种不同的创作需求。
例如,用户可以通过文本指令指定人物的特定动作,如“举手”、“跳跃”或“微笑”。同时,还可以通过文本指令改变视频的背景,如“海滩”、“森林”或“城市”。此外,用户还可以通过文本指令控制人物的情绪表达,如“快乐”、“悲伤”或“愤怒”。
人物与物体互动:OmniAvatar还支持生成人物与周围物体互动的场景。例如,人物可以拿起物品、操作设备等。这种功能的加入,极大地拓展了OmniAvatar的应用范围,使其能够应用于更广泛的场景。
例如,在教育培训领域,可以利用OmniAvatar生成虚拟教师形象,并让其与虚拟教具进行互动,从而提高教学的趣味性和互动性。在广告营销领域,可以生成虚拟代言人形象,并让其与产品进行互动,从而实现更具吸引力的广告宣传。
背景控制:用户可以根据文本提示,轻松改变视频的背景,以适应各种不同的场景需求。无论是创建梦幻般的奇幻场景,还是模拟真实的办公环境,OmniAvatar都能轻松胜任。
通过灵活的背景控制功能,用户可以为视频内容赋予不同的情感色彩和氛围,从而更好地传达信息和表达创意。例如,在制作浪漫爱情故事时,可以选择夕阳下的海滩作为背景;在制作紧张刺激的动作片时,可以选择阴暗的巷道作为背景。
情绪控制:OmniAvatar允许用户基于文本提示,控制人物的情绪表达。无论是快乐、悲伤、愤怒还是平静,OmniAvatar都能准确地表达出来,从而增强视频的表现力。
通过情绪控制功能,用户可以为视频角色赋予更加丰富的情感,使其更具感染力。例如,在制作感人的剧情片时,可以通过控制人物的表情和肢体语言,来表达角色的内心痛苦和挣扎。
OmniAvatar的技术原理
OmniAvatar的卓越性能,源于其背后一系列先进的技术原理:
像素级多级音频嵌入策略:OmniAvatar采用了一种创新的像素级多级音频嵌入策略。该策略将音频特征映射到模型的潜在空间,并在像素级别上进行嵌入。这种嵌入方式使得音频特征能够更自然地影响全身动作的生成,从而显著提高唇部同步的精度和全身动作的自然度。
传统的音频嵌入方法往往只关注全局特征,而忽略了音频的局部细节。OmniAvatar的像素级多级音频嵌入策略则能够捕捉到音频的细微变化,并将其转化为相应的动作和表情,从而实现更加精准和自然的同步效果。
LoRA训练方法:OmniAvatar基于低秩适应(LoRA)技术对预训练模型进行微调。LoRA通过在模型的权重矩阵中引入低秩分解,减少了训练参数的数量,同时保留了模型的原始能力。这种方法不仅提高了训练效率,还提升了生成质量。
在大规模模型训练中,参数数量往往是一个重要的瓶颈。LoRA通过减少需要训练的参数数量,降低了计算资源的需求,使得在有限的硬件条件下也能进行高效的模型训练。
长视频生成策略:为了生成连贯的长视频,OmniAvatar采用了基于参考图像嵌入和帧重叠策略。参考图像嵌入确保视频中人物身份的一致性,而帧重叠则保证视频在时间上的连贯性,避免动作的突变。
在长视频生成中,保持人物身份的一致性和动作的连贯性是一个巨大的挑战。OmniAvatar通过参考图像嵌入和帧重叠策略,有效地解决了这些问题,实现了高质量的长视频生成。
基于扩散模型的视频生成:OmniAvatar基于扩散模型(Diffusion Models)作为基础架构,逐步去除噪声生成视频。这种模型能够生成高质量的视频内容,且在处理长序列数据时表现出色。
扩散模型是一种强大的生成模型,它通过逐步去除噪声的方式,从随机噪声中生成高质量的图像和视频。相比于传统的生成对抗网络(GAN),扩散模型在生成质量和稳定性方面具有显著优势。
Transformer架构:在扩散模型的基础上,OmniAvatar引入了Transformer架构,以更好地捕捉视频中的长期依赖关系和语义一致性,进一步提升生成视频的质量和连贯性。
Transformer架构是一种强大的序列建模工具,它通过自注意力机制,能够有效地捕捉序列中的长期依赖关系。在视频生成中,Transformer架构可以帮助模型理解视频的内容和结构,从而生成更加连贯和自然的视频。
OmniAvatar的项目地址
对于对OmniAvatar感兴趣的开发者和研究者,以下是相关的项目地址:
- 项目官网:https://omni-avatar.github.io/
- GitHub仓库:https://github.com/Omni-Avatar/OmniAvatar
- HuggingFace模型库:https://huggingface.co/OmniAvatar/OmniAvatar-14B
- arXiv技术论文:https://arxiv.org/pdf/2506.18866
OmniAvatar的应用场景
OmniAvatar的应用前景广阔,以下是一些典型的应用场景:
虚拟内容制作:OmniAvatar可以用于生成播客、视频博主等的虚拟形象,从而降低制作成本,丰富内容表现形式。
通过OmniAvatar,内容创作者可以轻松创建个性化的虚拟形象,并利用其生成各种有趣的视频内容。这不仅可以降低制作成本,还可以提高创作效率,让内容创作者专注于内容的创意和设计。
互动社交平台:在虚拟社交场景中,OmniAvatar可以为用户提供个性化的虚拟形象,实现自然的动作和表情互动,增强社交体验。
在虚拟社交平台中,用户可以使用OmniAvatar创建自己的虚拟化身,并与其他用户进行互动。逼真的动作和表情可以增强社交的真实感和沉浸感,让用户更好地表达自己。
教育培训领域:OmniAvatar可以生成虚拟教师形象,基于音频输入讲解教学内容,提高教学的趣味性和吸引力。
虚拟教师可以24小时在线授课,为学生提供个性化的学习体验。通过OmniAvatar,可以创建各种不同风格的虚拟教师,以满足不同学生的学习需求。
广告营销领域:OmniAvatar可以生成虚拟代言人形象,根据品牌需求定制形象和动作,实现精准的广告宣传。
虚拟代言人可以降低广告成本,提高广告效果。通过OmniAvatar,可以快速生成各种不同风格的虚拟代言人,并根据品牌需求进行定制,从而实现更精准的广告宣传。
游戏与虚拟现实:OmniAvatar可以快速生成具有自然动作和表情的虚拟游戏角色,丰富游戏内容,提升虚拟现实体验的逼真度。
在游戏和虚拟现实应用中,逼真的角色形象可以增强用户的沉浸感和代入感。通过OmniAvatar,可以快速生成各种不同风格的游戏角色,并赋予其自然的动作和表情,从而提升游戏和虚拟现实的体验。
总而言之,OmniAvatar作为一款由浙江大学和阿里巴巴共同推出的音频驱动全身视频生成模型,凭借其自然唇部同步、全身动画生成、文本控制、人物与物体互动、背景控制和情绪控制等强大功能,以及像素级多级音频嵌入策略、LoRA训练方法、长视频生成策略、基于扩散模型的视频生成和Transformer架构等先进技术原理,在虚拟内容制作、互动社交平台、教育培训领域、广告营销领域以及游戏与虚拟现实等领域都具有广阔的应用前景。它的出现无疑将为数字内容创作领域带来革命性的变革,并推动相关产业的快速发展。









