
在人工智能领域,特别是生成式对抗网络(AIGC)的快速发展下,语音交互技术已成为一个备受瞩目的研究领域。传统的语音交互模型往往依赖于文本处理作为中介,这在一定程度上限制了人机音频交互的自然性和流畅性。为了打破这一瓶颈,提升用户体验,Step-Audio 团队开源了一款全新的端到端语音大模型——Step-Audio-AQAA,这一举措无疑为语音交互领域注入了新的活力。
Step-Audio-AQAA 模型的核心优势在于其能够直接从原始音频输入生成自然流畅的语音输出。这种端到端的处理方式避免了传统方法中将音频转换为文本的中间步骤,从而减少了信息损失和处理延迟,使得人机交流更加自然高效。该模型的开源,不仅为研究者提供了一个强大的工具,也为未来的智能语音应用打下了坚实的基础。以下将从模型架构、技术特点以及潜在应用等方面对 Step-Audio-AQAA 进行深入分析。
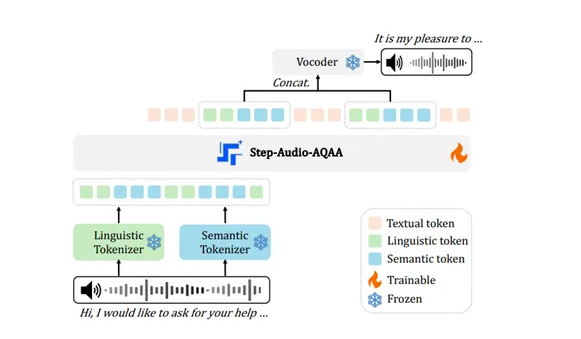
Step-Audio-AQAA 模型架构:
Step-Audio-AQAA 模型的架构设计独具匠心,主要由三个核心模块组成:双码本音频标记器、骨干 LLM(大型语言模型)和神经声码器。这三个模块协同工作,实现了从音频输入到语音输出的无缝衔接。
1. 双码本音频标记器:
双码本音频标记器是 Step-Audio-AQAA 模型的重要组成部分,其主要功能是将输入的音频信号转化为结构化的标记序列。这一模块采用了创新的双码本设计,包含两个子模块:语言标记器和语义标记器。
- 语言标记器: 负责提取语言的结构化特征,如音素、词汇和语法结构。它通过分析音频信号的频谱和时域特征,将语音分解为一系列离散的语言单元,为后续的语言建模提供基础。
- 语义标记器: 专注于捕捉语音中的情感、语调等副语言信息。这些信息对于理解语音的真实含义至关重要。语义标记器通过分析音频的韵律特征、能量变化等,提取出能够反映说话者情感状态和意图的特征向量。
通过这种双码本设计,Step-Audio-AQAA 能够更全面、更深入地理解语音中的复杂信息,为后续的语音生成提供更丰富的输入。
2. 骨干 LLM (Step-Omni):
在 Step-Audio-AQAA 模型中,骨干 LLM 扮演着至关重要的角色。Step-Audio 团队采用了 Step-Omni,一款预训练的 1300 亿参数的多模态模型,作为骨干 LLM。Step-Omni 具备强大的文本、语音和图像处理能力,能够胜任复杂的语音理解和生成任务。
Step-Omni 采用了 Decoder-Only 架构,这种架构在处理序列生成任务时表现出色。它能够高效地处理来自双码本音频标记器的标记序列,通过深度的语义理解和特征提取,为后续生成自然语音做好充分准备。
具体来说,Step-Omni 首先将双码本音频标记器输出的语言标记和语义标记进行融合,形成一个统一的表示。然后,通过多层 Transformer 解码器对该表示进行处理,捕捉语音中的长程依赖关系和上下文信息。最后,Step-Omni 根据学习到的知识和模式,预测下一个音频标记,从而生成完整的音频标记序列。
3. 神经声码器:
神经声码器是 Step-Audio-AQAA 模型的最后一个关键模块,其主要作用是将离散的音频标记合成为高质量的语音波形。该模块采用了 U-Net 架构,U-Net 是一种在图像处理领域广泛应用的深度学习模型,以其高效性和准确性而闻名。
在 Step-Audio-AQAA 模型中,神经声码器首先将 Step-Omni 输出的音频标记序列转换为频谱图。然后,通过 U-Net 架构对频谱图进行处理,恢复语音的细节和自然度。最后,神经声码器将处理后的频谱图转换为时域波形,生成最终的语音输出。
通过这种创新的架构设计,Step-Audio-AQAA 能够在听懂音频问题后,迅速合成自然、流畅的语音回答,为用户提供卓越的交互体验。
Step-Audio-AQAA 技术特点分析:
Step-Audio-AQAA 模型的成功离不开其独特的技术特点。以下将对 Step-Audio-AQAA 的主要技术特点进行深入分析:
- 端到端语音生成:
与传统的语音交互系统相比,Step-Audio-AQAA 最大的优势在于其端到端的语音生成能力。传统的语音交互系统通常需要将音频转换为文本,然后由文本生成语音,这种过程不仅复杂,而且容易引入误差。Step-Audio-AQAA 则直接从音频生成语音,避免了中间步骤,提高了效率和准确性。
- 双码本音频标记:
双码本音频标记是 Step-Audio-AQAA 的另一大亮点。通过将语言信息和副语言信息分别编码,Step-Audio-AQAA 能够更全面地理解语音的含义。这种方法不仅提高了语音识别的准确率,还有助于生成更富有表现力的语音。
- 预训练多模态模型:
Step-Audio-AQAA 采用了预训练的 Step-Omni 模型作为骨干 LLM。Step-Omni 经过大规模的文本、语音和图像数据训练,具备强大的语言理解和生成能力。通过使用 Step-Omni,Step-Audio-AQAA 能够更好地处理复杂的语音交互任务。
- 神经声码器:
神经声码器是 Step-Audio-AQAA 生成高质量语音的关键。U-Net 架构的神经声码器能够有效地恢复语音的细节和自然度,使得生成的语音听起来更加真实。
Step-Audio-AQAA 的潜在应用:
Step-Audio-AQAA 技术的进步为人机交互开辟了新的可能性。以下将探讨 Step-Audio-AQAA 在不同领域的潜在应用:
- 智能助手:
Step-Audio-AQAA 可以应用于各种智能助手,如智能家居助手、车载助手等。通过 Step-Audio-AQAA,智能助手可以更自然地理解用户的语音指令,并生成更流畅的语音回复,从而提高用户体验。
- 语音客服:
Step-Audio-AQAA 可以用于构建更智能的语音客服系统。传统的语音客服系统通常只能识别简单的指令,而 Step-Audio-AQAA 可以理解更复杂的语音问题,并提供更个性化的解答。
- 教育领域:
Step-Audio-AQAA 可以应用于教育领域,例如,可以开发出能够根据学生的语音提问提供解答的智能 tutor。此外,Step-Audio-AQAA 还可以用于生成各种语音教材,帮助学生更好地学习。
- 娱乐领域:
Step-Audio-AQAA 还可以应用于娱乐领域,例如,可以开发出能够与用户进行语音互动的游戏角色。此外,Step-Audio-AQAA 还可以用于生成各种语音故事,为用户带来更丰富的娱乐体验。
总结与展望:
Step-Audio 团队开源的 Step-Audio-AQAA 模型代表了人机音频交互技术的一个重要进展。该模型通过端到端的语音生成、双码本音频标记、预训练多模态模型和神经声码器等技术,实现了高质量的语音交互。Step-Audio-AQAA 的开源不仅为研究者提供了一个强大的工具,也为未来的智能语音应用奠定了坚实的基础。随着人工智能技术的不断发展,我们有理由相信,Step-Audio-AQAA 将在未来的语音交互领域发挥更大的作用。










