
在人工智能领域,视觉语言模型(VLM)正迎来新的发展高度。智谱AI开源的GLM-4.1V-Thinking模型,以其卓越的复杂认知任务处理能力,受到了业界的广泛关注。本文将深入探讨GLM-4.1V-Thinking的技术原理、功能特性、性能表现及其应用前景,力求为读者呈现一个全面而深入的解读。
GLM-4.1V-Thinking:技术架构与核心功能
GLM-4.1V-Thinking并非横空出世,而是在GLM-4V架构基础上的迭代创新。其核心在于引入了思维链推理机制,并通过课程采样强化学习策略,实现了跨模态因果推理能力与稳定性的系统性提升。这种设计思路,使得模型在处理多模态输入时,能够像人类一样进行逐步思考和推理,从而更好地理解和解决复杂问题。
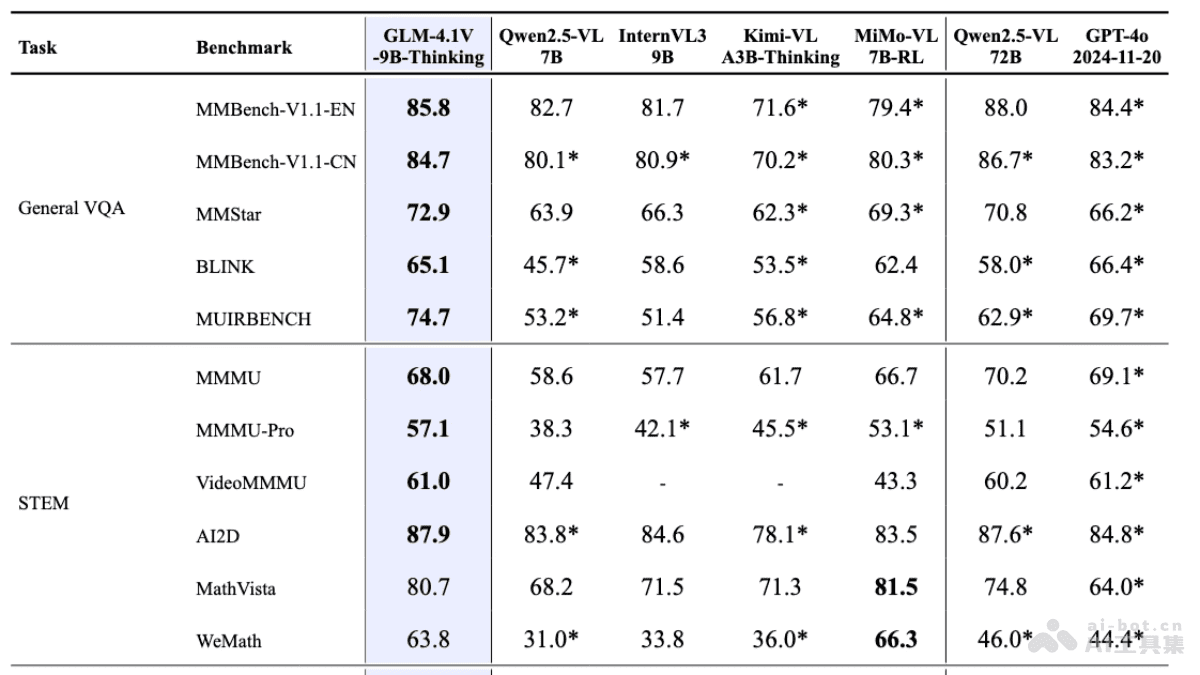
更令人瞩目的是,GLM-4.1V-Thinking的轻量版GLM-4.1V-9B-Thinking,参数量仅为10B级别。然而,在28项权威评测中,它却有23项取得了10B级模型中的最佳成绩,更有18项甚至超越了参数量高达72B的Qwen-2.5-VL。这充分展现了小体积模型所蕴含的巨大性能潜力,也为VLM的轻量化发展提供了新的思路。
GLM-4.1V-Thinking的功能十分强大,涵盖了多个方面:
- 图像理解:模型能够精准地识别和分析图像内容,支持目标检测、图像分类、视觉问答等复杂的视觉任务。这意味着它可以从图像中提取出有用的信息,并将其用于后续的推理和决策。
- 视频处理:GLM-4.1V-Thinking具备时序分析和事件逻辑建模能力,可以处理视频输入,并进行视频理解、视频描述和视频问答。这使得它能够理解视频中的动作、场景和事件,并生成相应的描述或回答相关问题。
- 文档解析:模型支持处理文档中的图像和文本内容,能够进行长文档理解、图表理解和文档问答。这对于处理包含大量图文信息的文档来说非常有用,可以帮助用户快速找到所需的信息。
- 数学与科学推理:GLM-4.1V-Thinking能够处理复杂的数学题解、多步演绎和公式理解,胜任STEM领域的推理任务。这意味着它可以像一个数学家或科学家一样,进行复杂的数学计算和科学推理。
- 逻辑推理:模型支持进行逻辑推理和因果分析,能够处理多步推理和逻辑判断等复杂任务。这使得它能够像一个逻辑学家一样,进行严密的逻辑推理和判断。
- 跨模态推理:GLM-4.1V-Thinking可以整合视觉和语言信息进行推理,支持图文理解、视觉问答和视觉锚定等任务。这意味着它可以将图像和文本信息结合起来,进行更深入的理解和推理。
技术原理:多模态融合与强化学习
GLM-4.1V-Thinking的技术原理主要体现在以下几个方面:
- 架构设计:模型采用AIMv2Huge作为视觉编码器,负责处理和编码图像和视频输入。MLP适配器则将视觉特征对齐到语言模型的token空间。语言解码器使用GLM作为语言模型,处理多模态token并生成输出。这种架构设计实现了视觉和语言信息的有效融合。
- 训练方法:模型基于大规模的图像-文本对、学术文献和知识密集型数据进行预训练,构建强大的视觉语言基础模型。同时,使用长链推理(CoT)数据进行监督微调,以提升模型的推理能力和人类对齐。此外,还采用了基于课程采样强化学习(RLCS)的方法,动态选择最具信息量的样本进行训练,从而提升模型在多种任务上的性能。
- 技术创新:GLM-4.1V-Thinking引入了思维链推理机制,让模型逐步思考并生成详细的推理过程。基于课程采样策略,动态调整训练样本的难度,确保模型在不同阶段都能获得最有效的训练。此外,还采用了基于2D-RoPE和3D-RoPE技术,支持任意分辨率和宽高比的图像输入,增强模型的时空理解能力。
性能表现:超越同级别模型
在性能方面,GLM-4.1V-Thinking在MMStar、MMMU-Pro、ChartQAPro、OSWorld等28项权威评测中表现出色,有23项达到了10B级模型的最佳成绩,其中18项甚至持平或超越了参数量高达72B的Qwen-2.5-VL。这些数据充分证明了GLM-4.1V-Thinking在视觉语言理解和推理方面的强大实力。
如何使用GLM-4.1V-Thinking
目前,使用GLM-4.1V-Thinking主要有以下几种方式:
- API接口:用户可以通过智谱AI开放平台注册账号并获取API Key,然后根据API文档,使用HTTP请求调用模型接口,发送输入数据并获取模型的输出结果。这种方式适合于需要将模型集成到自己的应用或系统中的开发者。
- 开源模型:用户可以从Hugging Face模型库下载GLM-4.1V-Thinking的开源模型,并使用相应的深度学习框架(如PyTorch)加载模型,然后将输入数据预处理后输入模型,获取模型的输出结果。这种方式适合于研究人员或对模型有较高定制需求的开发者。
- 在线体验平台:用户可以直接访问Hugging Face平台上的GLM-4.1V-Thinking体验页面,在网页上上传图像或输入文本,然后点击“运行”按钮,等待模型处理并查看结果。这种方式适合于想要快速体验模型功能的用户。
GLM-4.1V-Thinking的应用场景
GLM-4.1V-Thinking的应用场景非常广泛,以下列举几个典型的例子:
- 教育辅导:GLM-4.1V-Thinking可以辅助学生解决数学、科学等学科的复杂问题,提供详细的解题步骤和推理过程,帮助学生更好地理解和掌握知识。例如,它可以分析一道复杂的物理题,识别出题中的关键信息,并给出详细的解题步骤,帮助学生理解解题思路。
- 内容创作:GLM-4.1V-Thinking可以结合图像和文本生成创意内容,如广告文案、社交媒体帖子、新闻报道等,提升内容创作的效率和质量。例如,它可以根据一张图片和一些关键词,自动生成一段吸引人的广告文案。
- 智能交互:GLM-4.1V-Thinking可以作为智能客服或虚拟助手,理解用户的问题和需求,提供准确、及时的回答和解决方案,支持多模态输入。例如,它可以根据用户上传的一张产品图片和一段文字描述,快速识别出用户想要购买的产品,并给出相应的购买建议。
- 行业应用:在医疗、金融、工业等领域,GLM-4.1V-Thinking可以辅助专业人员进行数据分析、报告生成、设备监控等任务,提高工作效率和准确性。例如,在医疗领域,它可以分析医学影像,辅助医生进行疾病诊断;在金融领域,它可以分析市场数据,辅助分析师进行投资决策。
- 娱乐与生活:GLM-4.1V-Thinking可以为旅游提供攻略和景点介绍,为美食推荐菜品和烹饪方法,为游戏生成剧情和任务设计,丰富用户的娱乐体验。例如,它可以根据用户输入的旅游目的地,自动生成一份详细的旅游攻略,包括景点介绍、交通方式、住宿推荐等。
GLM-4.1V-Thinking的开源,无疑将推动VLM技术的发展和应用。我们期待在未来,GLM-4.1V-Thinking能够在更多领域发挥其强大的能力,为人类带来更多的便利和价值。










