
在人工智能领域,字节跳动再次走在了前沿,推出了其最新力作——VINCIE-3B。这款拥有3亿参数的模型,不仅仅是一个技术上的突破,更代表着图像编辑领域的一次革新。VINCIE-3B 的独特之处在于,它能够理解并利用上下文信息,实现对图像的连续编辑,这在以往的图像编辑工具中是难以想象的。本文将深入剖析 VINCIE-3B 的技术原理、应用场景以及它可能对行业带来的深远影响。
技术原理:从视频中学习上下文
传统的图像编辑模型往往需要大量标注数据,且依赖于专业的分割或修复模型来生成训练数据。这种方式不仅成本高昂,而且流程繁琐。VINCIE-3B 则另辟蹊径,它直接从视频数据中学习,通过将视频转化为交错多模态序列(文本 + 图像),从而实现上下文感知的图像编辑。这种方法的创新之处在于,它摆脱了对专家模型的依赖,大大降低了数据准备的成本。
VINCIE-3B 的核心技术之一是块因果扩散变换器(Block-Causal Diffusion Transformer)。这种架构在文本和图像块之间实现了因果注意力,同时在块内采用双向注意力。这样的设计既保证了信息的高效流动,又维护了时间序列的因果一致性。简单来说,模型能够理解图像之间的时序关系,从而在编辑时保持上下文的连贯性。
为了进一步提升模型的性能,VINCIE-3B 采用了三重代理任务训练。这包括下一帧预测、当前帧分割预测和下一帧分割预测。通过这三种任务的训练,模型能够更好地理解动态场景和物体之间的关系。此外,VINCIE-3B 还采用了干净与噪声条件结合的方法,解决了扩散模型中噪声图像输入的问题。通过同时输入干净和噪声图像标记,并利用注意力掩码,模型能够确保噪声图像仅基于干净的上下文进行条件生成,从而提升编辑质量。
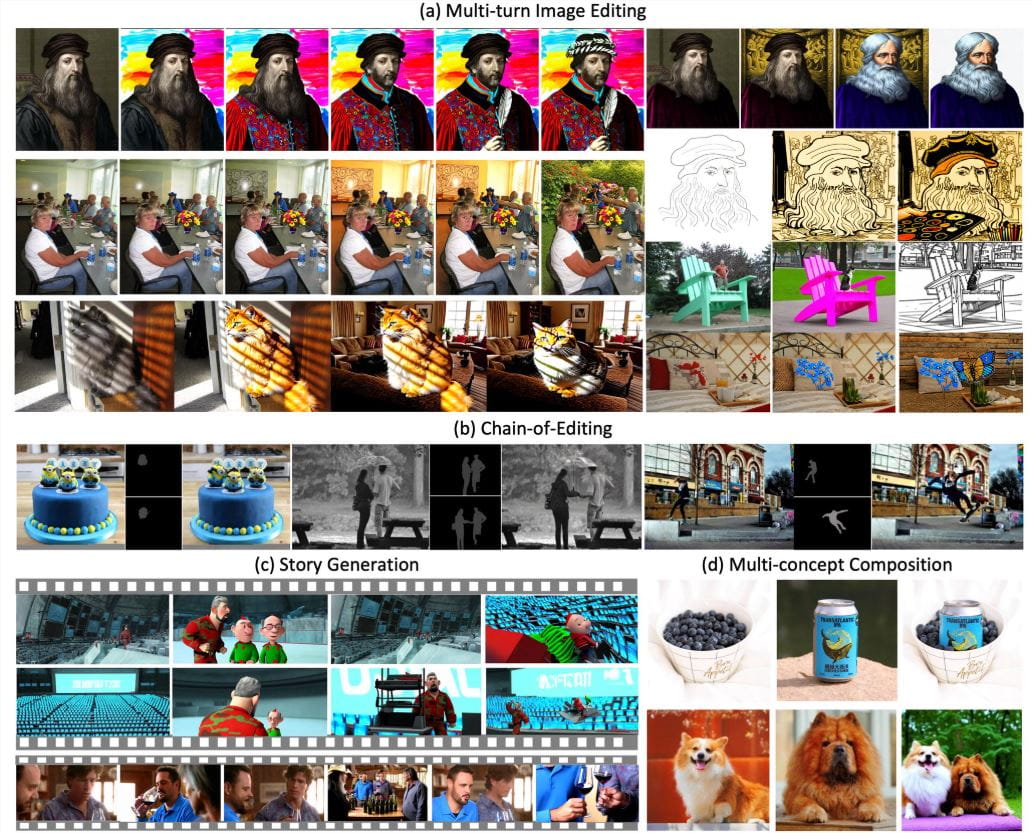
在性能测试中,VINCIE-3B 在 KontextBench 和新型多轮图像编辑基准测试中均达到了业界领先水平。尤其在文本遵循性、角色一致性和复杂场景编辑(如动态物体移动)等方面表现出色。值得一提的是,VINCIE-3B 生成一张高质量编辑图像的平均时间约为 4 秒,推理效率比同类模型快约 8 倍。这意味着用户可以更快地获得编辑结果,极大地提升了工作效率。
开源生态:赋能全球开发者
字节跳动选择将 VINCIE-3B 开源,无疑是一个明智之举。开源不仅能够吸引更多的开发者参与到模型的改进和优化中来,还能够推动整个图像编辑领域的发展。目前,VINCIE-3B 的完整代码、模型权重及训练数据处理流程已在 GitHub 和 arXiv 上发布。开发者可以通过申请获取完整数据集,并基于 Apache 2.0 许可证进行非商业用途的开发。对于商业应用,则需要联系字节跳动获取许可。
字节跳动还推出了一个多轮图像编辑基准测试,其中包含了真实场景用例,旨在鼓励社区验证和优化模型性能。这一举措无疑将加速 VINCIE-3B 的发展,并推动其在更多场景中的应用。
应用场景:创意与生产力的双赢
VINCIE-3B 的强大功能使其在多个领域具有广泛的应用前景。
影视后期:VINCIE-3B 可以从视频帧中提取角色或物体,并进行连续编辑,以适应不同的场景。例如,将角色从室内移到室外,并保持光影和视角的一致性。这大大简化了影视后期的制作流程,提高了制作效率。
品牌营销:品牌营销人员可以将产品或 Logo 置入不同的背景中(如咖啡店、户外广告牌),并自动调整光照、阴影和透视,从而简化多场景宣传素材的制作。这使得品牌营销更加灵活和高效。
游戏与动画:游戏和动画开发者可以通过文本指令调整角色动作或场景元素,从而快速进行原型设计和动画预览。这大大缩短了开发周期,降低了开发成本。
社交媒体内容:社交媒体创作者可以基于单张图像生成动态序列,例如将静态角色图像转为动态表情包。这为社交媒体内容的创作带来了更多的可能性。
举个例子,如果用户想要将一个穿着红裙的女孩从公园移到海滩,并保持裙子的纹理和调整为夕阳光照,VINCIE-3B 可以生成自然融合的图像,裙子细节和光影效果都高度逼真。AIbase 的测试显示,VINCIE-3B 在多轮编辑中能够保持 90% 以上的角色一致性,优于 FLUX.1Kontext 在复杂场景下的表现。
局限与挑战:持续改进的方向
尽管 VINCIE-3B 表现出色,但仍然存在一些局限性。
多轮编辑限制:过多轮次的编辑可能会引入视觉伪影,导致图像质量下降。因此,建议用户在 5 轮以内完成编辑,以保持最佳效果。
语言支持:目前,VINCIE-3B 主要支持英文提示,中文和其他语言的文本遵循性稍逊。字节跳动计划在后续版本中优化多语言能力。
版权问题:由于训练数据部分来自公开视频,存在潜在的版权争议。因此,用户在商业应用中需要确保内容合规。
AIbase 建议用户在使用 VINCIE-3B 时,结合其提供的 KontextBench 数据集进行测试,以优化提示设计。对于商业用户,建议联系字节跳动明确许可条款。
行业影响:重塑图像编辑范式
VINCIE-3B 的发布标志着图像编辑从静态到动态、从单一到上下文连续的范式转变。与 Black Forest Labs 的 FLUX.1Kontext(专注于静态图像编辑)相比,VINCIE-3B 通过视频学习实现了更强的动态场景理解,特别适合需要时间序列一致性的应用。相比 Bilibili 的 AniSora V3(专注于动漫视频生成),VINCIE-3B 更通用,覆盖现实场景和虚拟内容生成。
字节跳动的开源策略进一步巩固了其在 AI 创意工具领域的领先地位。VINCIE-3B 的“视频到图像”训练方法可能启发其他公司探索类似路径,降低 AI 模型开发成本,推动创意产业的民主化。可以预见,未来将有更多的 AI 模型涌现,为创意产业带来更多的可能性。










