
在数字内容创作领域,Bilibili(B站)的开源动漫视频生成模型AniSora正经历着一次重大飞跃。最新发布的AniSora V3版本,作为Index-AniSora项目的重要组成部分,不仅在生成质量上实现了显著提升,更在动作流畅度和风格多样性方面为用户带来了前所未有的体验。本文将深入探讨AniSora V3的技术突破、广泛的应用场景以及对整个动漫内容创作行业产生的深远影响。
技术升级:更高质量与精准控制
AniSora V3的卓越性能得益于其坚实的技术基础。它建立在Bilibili此前开源的CogVideoX-5B和Wan2.1-14B模型之上,并巧妙地融合了强化学习与人类反馈(RLHF)框架。这一创新性的结合显著提升了生成视频的视觉质量和动作一致性,为动漫创作者提供了一款强大的工具,能够一键生成多种风格的动漫视频镜头,包括热门番剧片段、引人入胜的国创动画、充满创意的漫画视频改编以及生动有趣的VTuber内容。
时空掩码模块(Spatiotemporal Mask Module)优化
AniSora V3版本对时空掩码模块进行了深度优化,极大地增强了其时空控制能力。这使得模型能够胜任更为复杂的动画任务,例如,精确控制角色的面部表情、实现动态的镜头移动以及通过局部图像引导生成。举例来说,只需输入一段简单的提示——“五位女孩在镜头放大时起舞,左手上举至头顶再下放至膝盖”,AniSora V3便能够生成一段流畅自然的舞蹈动画,其中镜头与角色的动作完美同步,为观众带来身临其境的视觉享受。
数据集扩展
为了进一步提升生成内容的质量和丰富度,AniSora V3继续依托超过1000万高质量动漫视频片段进行训练。这些片段均从100万原始视频中精心提取,并经过新增的数据清洗流水线处理,确保生成内容的风格一致性和细节丰富度。庞大的数据集为模型提供了充足的学习素材,使其能够更好地理解和掌握各种动漫风格的特点,从而生成更具表现力和吸引力的作品。
硬件优化
AniSora V3版本在硬件方面也进行了重大升级,新增了对华为Ascend910B NPU的原生支持。这意味着,该模型可以完全基于国产芯片进行训练,从而摆脱了对国外技术的依赖,实现了自主可控。此外,硬件优化还带来了推理速度的显著提升,经测试,生成一段4秒高清视频仅需2-3分钟,推理速度提升约20%。
多任务学习
AniSora V3还强化了多任务处理能力,使其能够同时胜任从单帧图像生成视频、关键帧插值到唇部同步等多种任务。这一特性使得AniSora V3特别适合漫画改编和VTuber内容创作,为创作者提供了更加灵活和高效的工具。
在最新的基准测试中,AniSora V3在VBench和双盲主观测试中均表现出色,其角色一致性和动作流畅度均达到了业界顶尖水平(SOTA)。尤其值得一提的是,该模型在处理复杂动作(如违反物理规律的夸张动漫动作)时表现突出,能够轻松驾驭各种高难度动作,为动漫创作带来了更大的想象空间。
开源生态:社区驱动与透明发展
AniSora V3的完整训练和推理代码已于2025年7月2日在GitHub上更新,这一举措充分体现了Bilibili对开源生态的重视和 commitment。开发者可以通过Hugging Face访问模型权重及948个动画视频的评估数据集,从而深入了解模型的工作原理和性能特点。Bilibili强调,AniSora是“对动漫世界的开源礼物”,鼓励社区协作优化模型,共同推动动漫内容创作技术的发展。
为了获取V2.0权重和完整数据集的访问权限,用户需要填写申请表并发送至指定邮箱(如yangsiqian@bilibili.com)。这一举措旨在确保数据的合理使用,并鼓励用户积极参与到模型的改进和优化中来。
AniSora V3还引入了首个针对动漫视频生成的RLHF框架,通过AnimeReward和GAPO等工具对模型进行微调,确保输出更符合人类审美和动漫风格需求。这一创新性的框架使得模型能够更好地理解和把握动漫的精髓,从而生成更具艺术性和观赏性的作品。
目前,社区开发者已开始基于V3开发定制化插件,例如增强特定动漫风格(如吉卜力风)的生成效果。这些插件的出现将进一步丰富AniSora V3的功能和应用场景,为用户提供更多个性化的选择。
应用场景:从创意到商业
AniSora V3凭借其强大的功能和灵活性,支持多种动漫风格,包括备受欢迎的日本动漫、充满创意的国产原创动画、引人入胜的漫画改编、生动有趣的VTuber内容以及恶搞动画(鬼畜动画),几乎覆盖了90%的动漫视频应用场景。
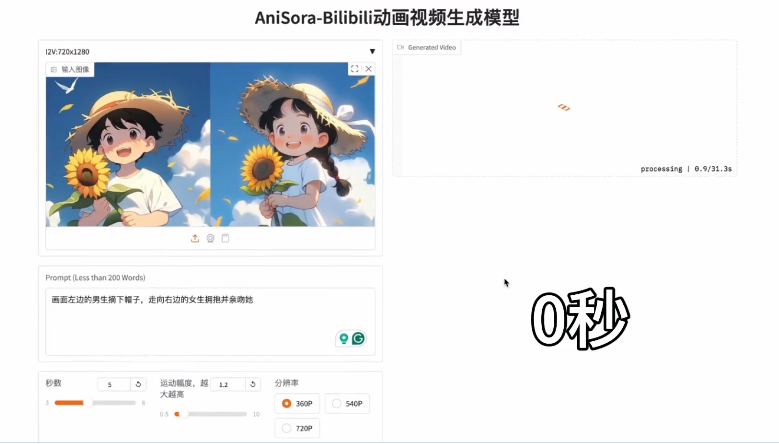
单图转视频
用户只需上传一张高质量动漫图像,并配合一段简单的文本提示(如“角色在向前行驶的车中挥手,头发随风摆动”),即可生成一段动态视频,且能够保持角色细节和风格一致。这一功能为动漫爱好者提供了一种快速便捷的创作方式,让他们能够轻松将静态图像转化为生动的视频作品。
漫画改编
AniSora V3还可以从漫画帧生成带唇部同步和动作的动画,非常适合快速制作预告片或短篇动画。这一功能极大地简化了漫画改编的流程,降低了制作成本,为漫画创作者带来了更多的可能性。
VTuber与游戏
AniSora V3支持实时生成角色动画,助力独立创作者和游戏开发者快速测试角色动作。这一功能为VTuber和游戏开发者提供了一种高效的动画制作解决方案,让他们能够更加专注于角色的设计和故事的创作。
高分辨率输出
AniSora V3生成的视频支持高达1080p的分辨率,确保在社交媒体、流媒体平台上的专业呈现。这意味着,用户可以使用AniSora V3创作出高质量的动漫视频,并在各种平台上分享和传播,从而获得更多的关注和认可。
AIbase的测试显示,V3在生成复杂场景(如多角色交互、动态背景)时,相比V2减少了约15%的伪影问题,生成时间缩短至平均2.5分钟(4秒视频)。这一数据充分证明了AniSora V3在性能上的显著提升。
AniSora V3的发布进一步降低了动漫创作的门槛,使得独立创作者和小型团队能够以低成本实现高质量动画制作。相比OpenAI的Sora或Kling等通用视频生成模型,AniSora V3专注于动漫领域,填补了市场空白。与字节跳动的EX-4D相比,AniSora V3更专注于2D/2.5D动漫风格,而非4D多视角生成,展现了不同的技术路线。这种差异化的发展策略使得AniSora V3能够在动漫内容创作领域占据一席之地,并为用户提供更具针对性的解决方案。










