
在人工智能领域,每天都有新的突破和创新涌现。今天的AI日报精选了几个引人注目的进展,涵盖了开源模型、音色克隆、大模型应用等多个方面,让我们一起深入了解这些前沿动态。
月之暗面Kimi-Dev-72B:开源模型的新标杆
月之暗面最新发布的开源模型Kimi-Dev-72B,专注于软件工程任务,并在SWE-bench Verified测试中取得了令人瞩目的成绩。这款模型以72亿的参数量超越了DeepSeek-R1,成为开源模型中的佼佼者,展示了其在编程领域的强大实力。
Kimi-Dev-72B在SWE-bench Verified测试中获得了60.4%的高分,这一成绩不仅刷新了开源模型的记录,也证明了其在代码质量和正确性方面的卓越表现。该模型结合了BugFixer和TestWriter双重角色,通过自我博弈机制不断提升性能。未来,Kimi-Dev-72B计划与流行的开发工具深度集成,持续优化并推出更强大的版本,为开发者提供更高效的编程支持。
MiniMax-M1:超长上下文推理的开源王者
MiniMax-M1以其超长上下文推理能力、高效的训练成本以及开源特性,在AI领域引发了广泛关注。这款模型不仅具备1M的超长上下文窗口,还实现了高效推理和低成本训练,成为开源模型中的一颗耀眼新星。
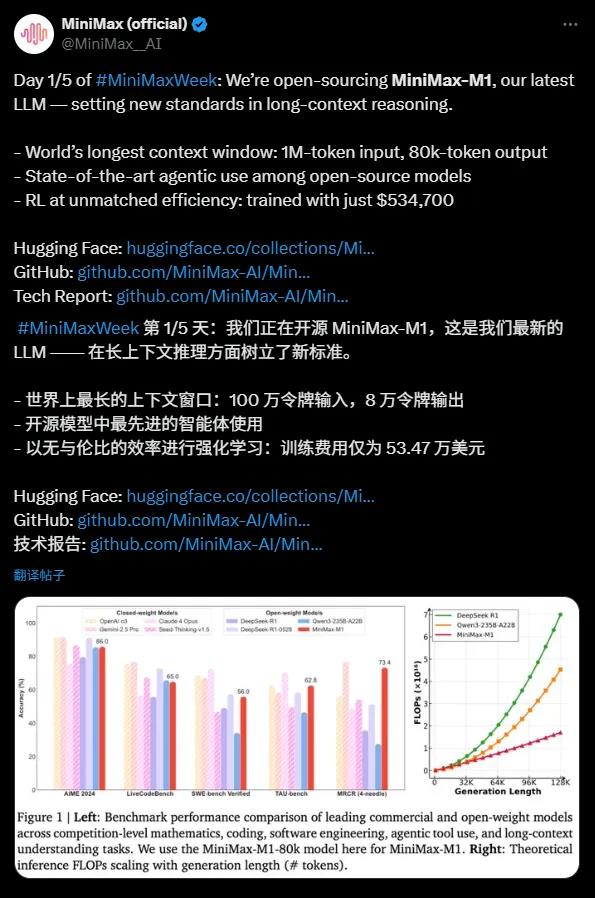
MiniMax-M1的上下文窗口达到了1M输入和80k输出,远超GPT-4o,使其在复杂文档分析和多轮对话等场景中表现出色。更令人惊喜的是,MiniMax-M1的训练成本仅为53万美元,这得益于其采用的MoE架构和CISPO算法。目前,MiniMax-M1已在Hugging Face平台开源,支持40k和80k思维预算,性能媲美顶级商业模型。
腾讯LeVo:零样本音色克隆的AI唱歌模型
腾讯AI团队推出的LeVo模型,以其强大的音色克隆、分轨生成和高保真音乐表现,在音乐创作领域掀起了一场革命。与Suno4.5相比,LeVo在多项关键指标上表现出色,同时支持零样本音色克隆和分轨生成,为音乐创作者提供了前所未有的便利。
LeVo模型支持零样本音色克隆,仅需3秒音频即可精准复制音色,大幅降低了音乐创作的门槛。此外,LeVo还提供分轨生成模式,支持人声与伴奏分离,为专业音乐制作提供了更高的灵活性。腾讯以开源形式发布LeVo模型,旨在促进全球音乐创作社区的发展,提升中国AI技术的国际影响力。
阿里巴巴Qwen3升级版:适配苹果MLX架构
阿里巴巴发布的Qwen3升级版,与苹果MLX架构兼容,标志着苹果智能在中国市场的发展迈出了重要一步。Qwen3升级版不仅支持更多语言,还增强了性能和推理能力,为苹果用户带来更智能的体验。

新版Qwen3支持119种语言,具备更强的性能和混合推理能力,为苹果智能在中国市场的落地提供了有力支持。虽然苹果智能尚未在中国上线,但预计将在iOS18.6正式公测版中提供预览,让用户提前体验到Qwen3带来的智能魅力。
豆包“AI播客”:信息接收的新方式
豆包电脑版与网页版上线了“AI播客”功能,用户只需上传PDF或链接,即可生成自然双人对话播客,这种全新的信息接收方式,让用户可以利用碎片时间高效获取信息。

豆包“AI播客”适用于工作、学习等多种场景,用户可以通过听播客的方式,轻松获取知识和信息。其语音效果逼真,去机器感,提供沉浸式听觉体验,让用户仿佛置身于真实的对话之中。
夸克App“夸克老师”:个性化AI辅导
夸克App推出了全新的学习产品“夸克老师”,这款AI家教功能强大,集讲题、批作业、出题、找试卷等多种功能于一体,尤其擅长数学和物理难题的解答。同时,“夸克老师”还具备因材施教的能力,通过分析学生的学习数据,提供个性化的辅导。
“夸克老师”能够根据学生特点提供个性化辅导,模拟真人教师的教学思路,帮助学生理解并提升学习效果。此外,“夸克老师”还拥有海量题库资源,包括专业题库和名校真题,满足学生多样化的学习需求。
松下OmniFlow:多模态大模型
松下全新OmniFlow多模态大模型,实现了文本、图像与音频的自由切换,为用户带来了全新的多模态体验。这款模型不仅能轻松转换文本、图像和音频,还能让用户根据需求定制生成结果,极大提升了操作灵活性和效率。
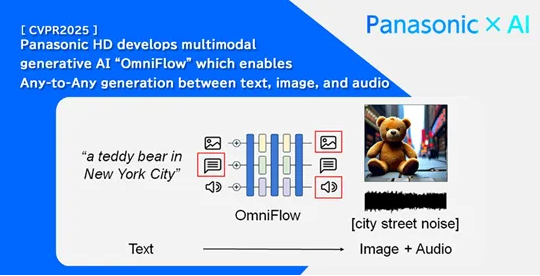
OmniFlow采用模块化设计,各组件独立预训练,提高了资源利用效率并优化了训练效果。此外,OmniFlow还引入了多模态引导机制,用户可以精准控制生成过程,满足多样化的需求。
TikTok Symphony AI工具:简化视频创作
TikTok推出了三款AI视频创作工具,包括“图像转视频”、“文字转视频”和“Showcase Products”,旨在简化品牌广告内容制作流程。这些工具集成到Symphony Creative Studio中,并与Adobe Express及WPP Open合作,提升广告商的效率。
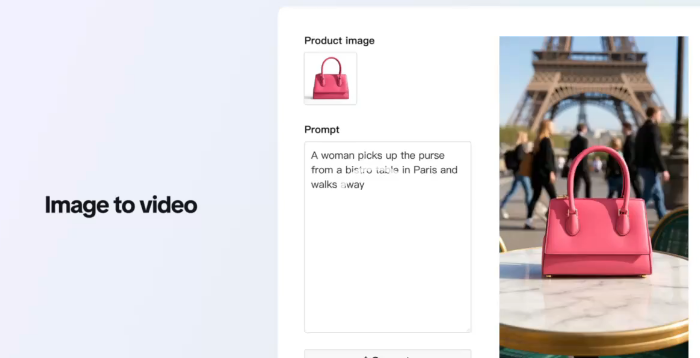
“图像转视频”功能让静态图片轻松变为动态视频,只需上传图片和添加文字提示即可生成多个AI视频选项。“文字转视频”功能无需图片或模板,仅凭文字即可制作视频,助力广告商快速测试和完善创意。“Showcase Products”工具融合产品图片与数字化身,打造沉浸式广告体验,提升用户原创内容风格。
极氪与火山引擎:豆包大模型赋能智能座舱
极氪汽车与火山引擎合作,将豆包大模型接入ZEEKR AI OS的新版中,提升智能座舱服务能力,优化个性化体验。通过豆包大模型的接入,极氪智能座舱实现了精准推荐与个性化服务。
升级后的极氪智能语音助手Eva,支持从传统语音交互到大语言模型服务的无缝切换。此外,极氪第50万台车型009光辉下线,刷新了豪华纯电车型最快纪录。
Meta Llama3.1:文本记忆的新突破
斯坦福大学等机构的研究表明,Meta的Llama3.170B模型在文本记忆方面表现出色,尤其在热门书籍如《哈利波特》中的表现令人瞩目。Llama3.170B模型在《哈利波特》中能记住42%的内容,远超Llama165B的4.4%。
研究采用Books3数据库,通过标记段落测试模型的记忆能力。结果显示,热门书籍记忆效果更佳,显示AI在理解和处理文本上的进步。
Grok任务功能:定时追踪X热门话题
xAI旗下的AI助手Grok推出了全新的Tasks定时任务功能,通过自动化执行查询和外部通知,为用户提供高效便捷的信息获取体验。Grok支持多种任务频率,从即时到长期跟踪,满足用户多样化的需求。
Grok还提供外部通知功能,如邮件推送,结果主动找用户,提升使用便利性。SuperGrok用户享有更高配额和优先体验尖端功能,如DeepSearch和Big Brain Mode。
Gemini2.5Pro:Deep Think功能即将更新
Gemini2.5Pro即将更新Deep Think功能,这一功能不仅提升了AI在复杂任务中的推理能力,还在用户体验和安全性上做出了重要改进。Deep Think功能通过多线程推理显著提升复杂任务中的性能,特别是在数学、编程和多模态任务中表现出色。
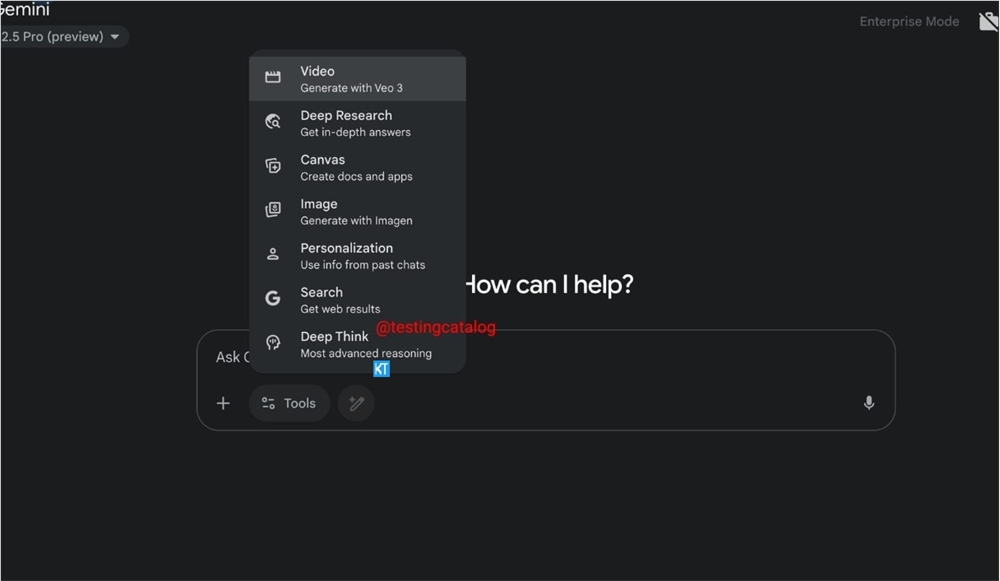
用户可通过网页UI直观切换至Deep Think模式,功能将逐步向更多用户开放。在正式发布前,Google通过API收集反馈并进行安全评估,确保功能的稳定性和数据安全性。
谷歌地图:全新AI功能带来智能体验
谷歌地图通过引入生成式人工智能技术,对导航、探索及个性化推荐等功能进行了全面升级,为用户提供更加智能、高效的体验。谷歌地图使用生成式AI搜索功能,通过自然语言实现精准地点查询。

智能评论分析功能,自动总结用户评论并解答关于地点的具体问题。此外,谷歌地图还推出了节油路线优化功能,结合多因素分析推荐更环保的行驶路线。
总结
今天AI领域的进展可谓是百花齐放,从开源模型到多模态应用,再到智能座舱和AI助手,每一项创新都为我们的生活和工作带来了更多的可能性。期待未来AI技术能够继续突破,为我们创造更加美好的未来。










