
大模型再「战」高考:从一本直升 985 的背后逻辑
一年提升上百分,或许我们正在见证最后一代能被考住的 AI。
过去一年,大型 AI 模型(也称大模型)的发展速度令人惊叹,技术迭代以周为单位,能力边界不断扩展,从写诗作画到视频生成,再到科学发现,无不展现出其强大的潜力。那么,如何精准、客观地评估 AI 的能力呢?在中国,没有什么比「高考」更能触动人心。
本文将深入探讨 AI 在高考中的表现,通过对比去年的测评结果,分析 AI 在各科目上的进步与不足,并探讨其背后的原因。
AI 高考成绩:从一本到冲击顶尖学府
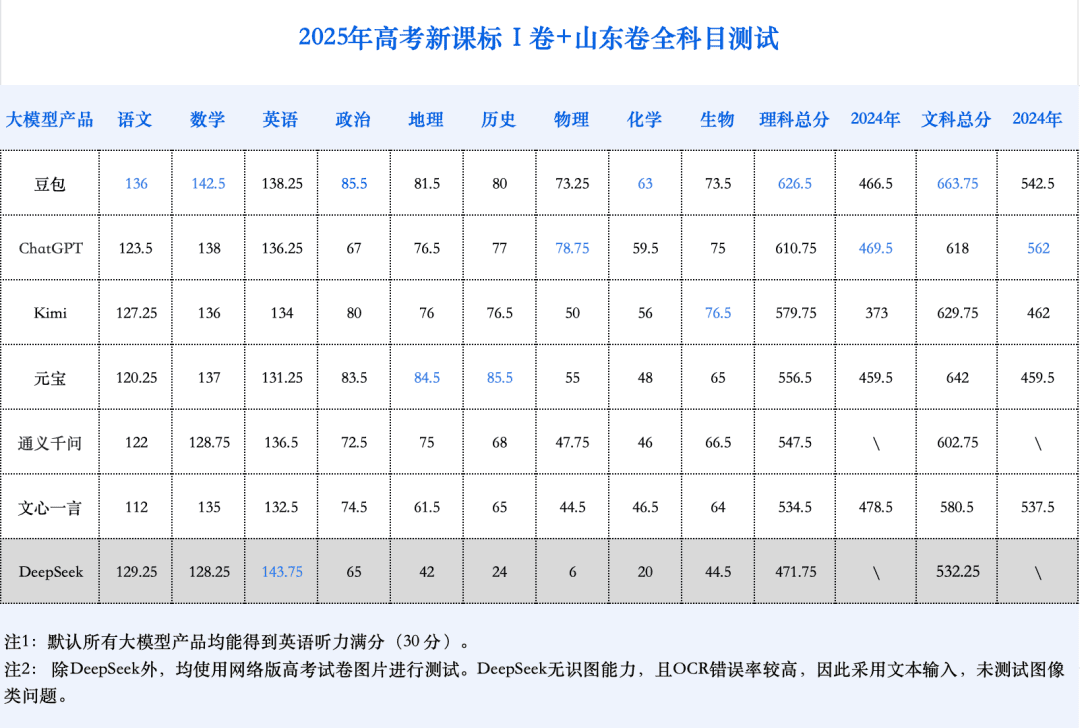
今年的 AI 高考模拟测评中,AI 的综合能力首次展现出足以考上顶尖学府的潜力。与 2024 年相比,所有参与测试的大模型在文理科成绩上均实现了显著飞跃。具体来看:
- 总分提升显著:AI 模型的总分大幅提升,按照山东省的报考策略估算,有望排进全省前 500-900 名,达到报考人大、复旦、上海交大、浙大等名校人文社科专业的水平。
- 不再严重偏科:各大模型的文科和理科成绩均有显著增长。文科总分平均增长 115.6 分,理科总分平均增长 147.4 分。尽管理科增速更快,但文科平均总分仍高于理科,表明 AI 在文科方面仍具有一定优势。
- 数学能力大幅增强:数学是进步最显著的科目,平均分较去年提升了 84.25 分。AI 在数学上的表现甚至超过了语文和英语,预示着 AI 未来可能更擅长处理逻辑性强、有标准化解题路径的题目。
- 多模态能力成为关键:模型的视觉理解能力显著提升,这一点在包含大量图像题的学科中尤为突出。物理和地理的平均分提升了约 20 分,生物提升了 15 分。化学科目整体表现稍弱,但平均分也比去年提高了 12.6 分。
考试细节与评分标准
为了更贴合读者的使用体验,本次评测均在各模型的公开 PC 端进行,测评采取采样两次取平均分的形式。本次参与考试的国内外考生包括:豆包、DeepSeek(R1-0528 版)、ChatGPT(o3)、元宝(Hunyuan t1)、Kimi(k1.5)、文心一言、通义千问。
DeepSeek-R1 目前仍然不支持图片识别作答,因此只测试了纯文字题目,最终成绩参考性不强。其他测试细节如下:
- 测试卷:选用 2025 年新高考山东卷。山东卷的综合难度在各省份中名列前茅,其语文、数学、英语三科采用全国一卷,其余科目则为自主命题。
- 联网功能:在可以关闭模型联网能力的产品中,统一关闭了模型的联网功能,以杜绝「搜题」的可能。o3 和文心无法关闭联网,不过检查模型思考过程发现,文心没有发生联网搜题的情形,o3 发生少量搜题情形,但没有明显收益,得分率反而低于非联网答题。同时,默认开启了深度思考模式,但没有开启研究模式,以模拟用户在标准交互下的即时问答场景。
- 评分:非选择题各学科分别请两名专业同学打分,如存在题目分值 1/6 以上的差异,则引入第三人讨论定分(与真实高考判卷流程一致),并邀请参与过真实高考打分的高中老师抽检,对存在差异的题目统一标准。我们特邀了资深教师进行对 AI 作文进行匿名评审,以保证客观公正。此外,由于无法获取英语听力部分的试题,我们设定所有模型在该项上均计为满分。
数学:逼近满分,却倒在基础题上
在整场 AI 高考的测评中,AI 考生在数学科目上的进步十分瞩目。在 2024 年的测评中,当时的 AI 考生们在填空题和解答题上表现惨淡,得分普遍在 0 至 2 分之间徘徊,最终 9 款参评模型的数学成绩的平均分仅为 47 分。而今年,则完全不同。
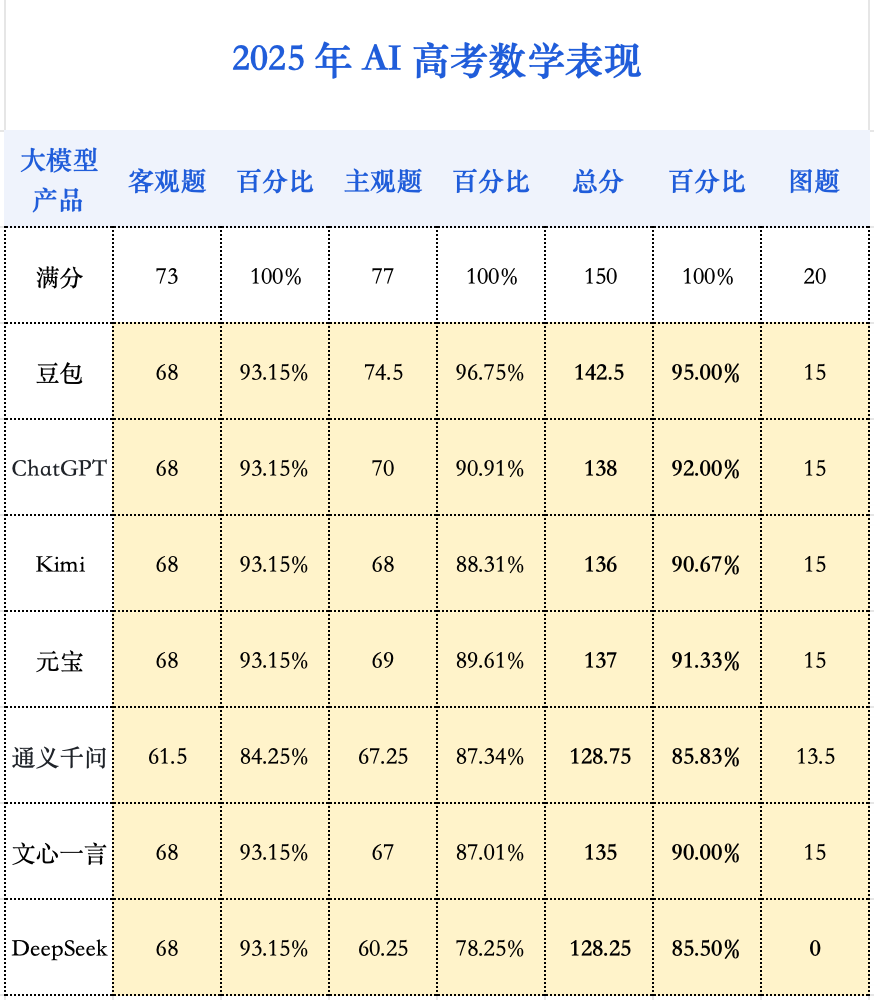
可以看出,无论是客观选择题,还是复杂的主观解答题,新一代大模型的正确率都今非昔比。这清晰地表明,大模型自身的能力,尤其是核心的推理能力,已经取得了根本性的突破。
然而,令人意外的是,在数学科目中,AI 们却在同一道基础题上栽了跟头。这道题是一道简单的向量加减法选择题,只需通过观察图像即可得出答案。然而,所有数学学霸 AI 均未能正确解答。
究其原因,在于图像的视觉信息过于混乱,虚线、实线、坐标轴、数字、文字相互交织,导致 AI 无法精准识别关键信息。以本次数学表现最佳的豆包为例,它的解题过程表明,它从一开始读取题目信息时就已出错。

语文:擅长举例,不擅长思辨
作为大语言模型,语文和英语一向是 AI 的传统强项。然而,在大模型的数理逻辑大幅进步后,大模型的语文和英语能力反而显得有点不够看了。这与现实世界也是一致的:一名顶尖考生或许能在数学上拿到满分,却极难在语文科目上获得同等分数。AI似乎也触碰到了同样的瓶颈。

在选择题部分,AI 的错误率较高,这或许揭示了 AI 与人类不同的一个困境:对于人类考生,组织语言、阐述观点时,可能更容易因疏漏而失分;但对于 AI,要读一段长材料,在一组高度迷惑性的选项中,精准辨析每一个细微的语义差别和逻辑陷阱,难度可能反而更高。
在作文题上,AI 的表现延续了去年的趋势:平均分高于人类,但难有真正的佳作。AI 作文大多属于稳妥的「二类文」,很少偏题,但因其深刻性、丰富性、创造性不足,难以产生动人心弦的「一类文」,其结尾部分的升华更是套路化明显。今年的新课标卷的语文作文考题为:
全国一卷作文「民族魂」
阅读下面的材料,根据要求写作。(60 分)
他想要给孩子们唱上一段,可是心里直翻腾,开不了口。
——老舍《鼓书艺人》
假如我是一只鸟,我也应该用嘶哑的喉咙歌唱
——艾青《我爱这土地》
我要以带血的手和你们一一拥抱,
因为一个民族已经起来
——穆旦《赞美》
以上材料引发了你怎样的联想和思考?请写一篇文章。
AI 作文的语言华丽,引经据典丰富,但逻辑上却略显生硬,像是在执行一个固化的写作模板:用排比式的案例填充框架,最终导向一个略显生硬的僵化升华。它能写出看似优秀的段落,却难以织就一篇真正动人的文章。
比如下面这篇元宝生成的 AI 作文。它在人类阅卷老师处获得了 53.5 分的高分,是 AI 作品中的佼佼者。
英语:作文成短板
与语文相似,AI 在传统强项——英语上的表现也进入了一个平台期。各家 AI 的英语成绩已然不错,今年的模型能力并未产生飞跃。事实上,所有参评模型的平均分仅比去年提高了 3.2 分,进步幅度远小于数学。
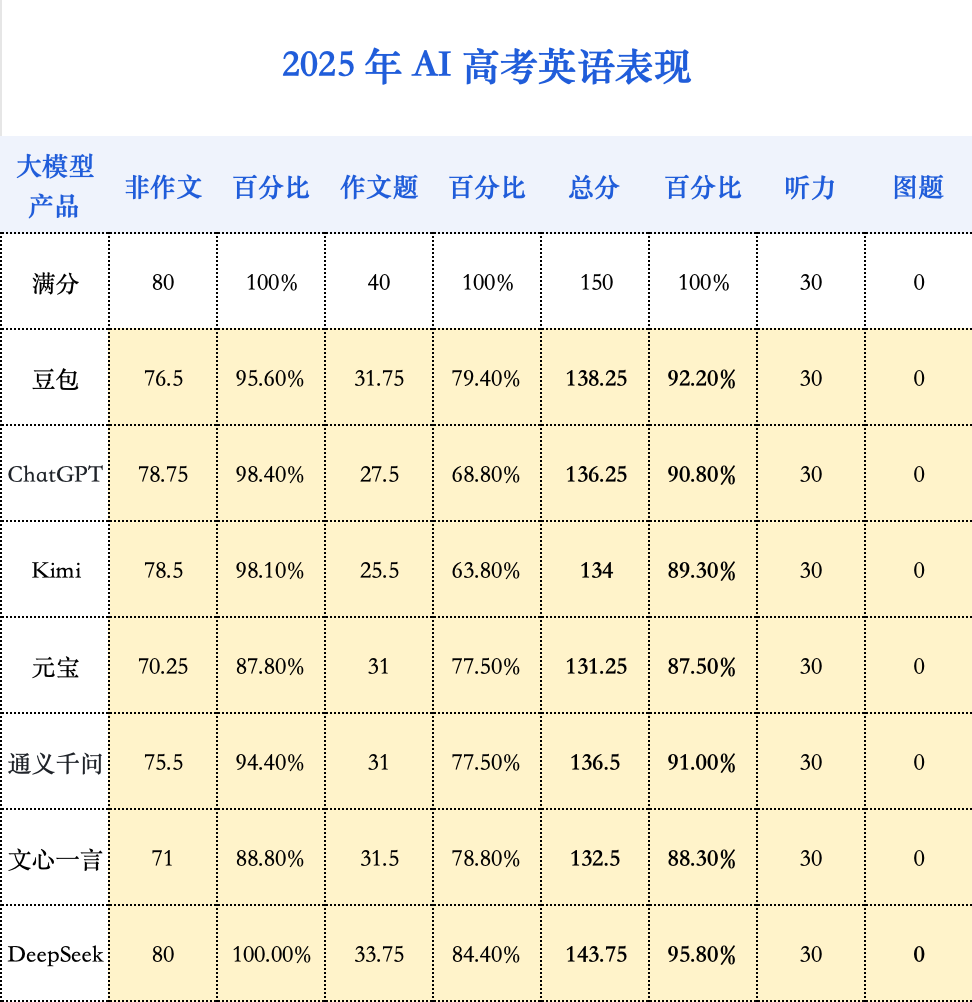
AI 的英文水平毋庸置疑,但高考英语这张试卷本身远未触及母语者的语言天花板。AI 考生并未在此表现出更强的统治力,作文题可能是一大拖累。
在有限的篇幅内,人类考生会有意识地使用更高级句式、时态来「炫技」以博取高分。而 AI 的目标通常是清晰、完整地传达信息,它不会刻意为了得分而优化句式复杂度,因此在评分细则上可能吃了暗亏。
理综:进步明显,仍有差距
AI 在数学上的进步是「一飞冲天」,那么在理综三科上的表现,则更像是一次「破冰启航」。相较于去年,理综三科有一定进步,但整体成绩依旧挣扎在及格线附近,清晰地标示出 AI 与顶尖人类考生之间的能力鸿沟。
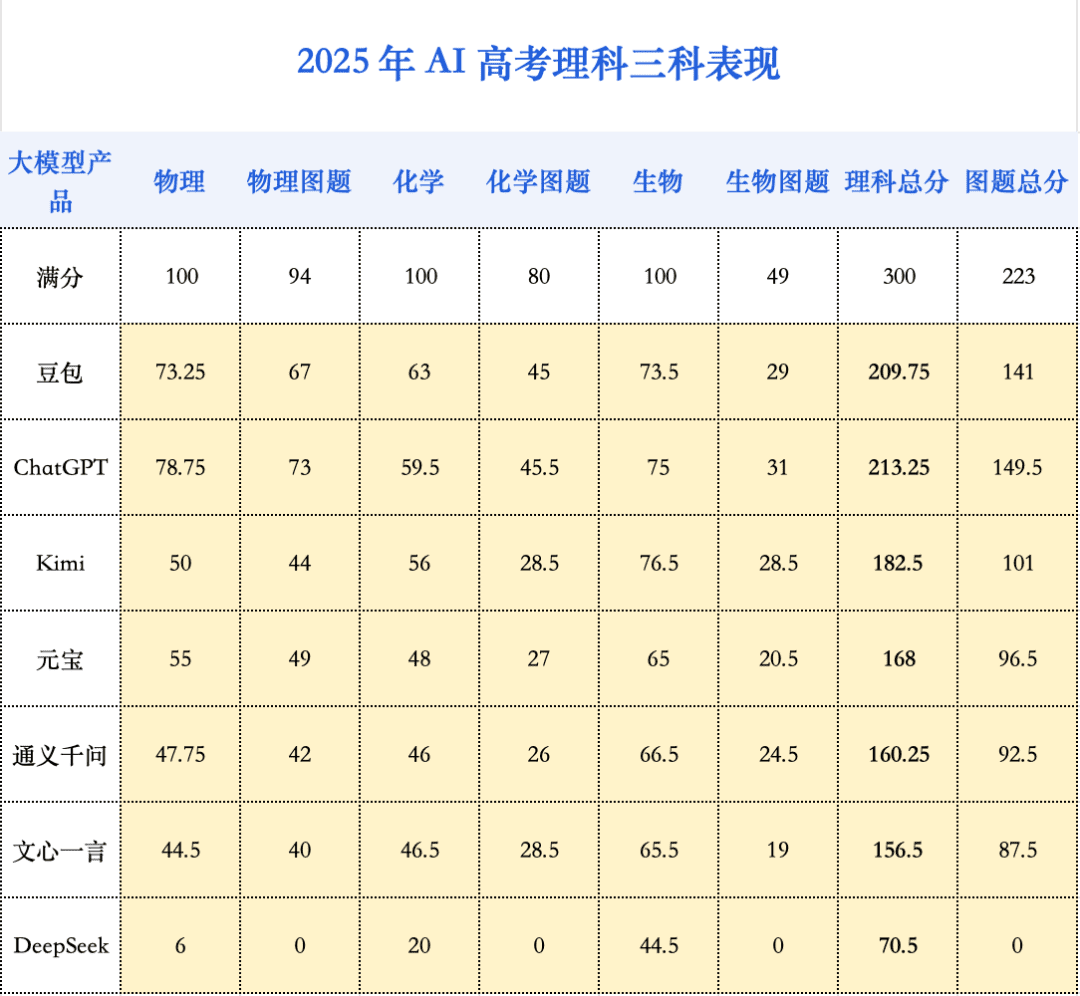
- 物理:进步最快的「排头兵」,平均分提升了 20.25 分。ChatGPT 的选择题正确率高达 92.13%,豆包也达到了 89.81%,展现了对物理基本概念和规律的扎实掌握。
- 化学:拉低理综总分的「重灾区」。整体得分偏低,仅有豆包勉强及格,选择题和填空题的平均得分率均低于 60%。有机物大题依旧是所有大模型的主要软肋。例如,满分为 12 分的第 25 题(有机化学),所有模型得分极低。
- 生物:折戟于遗传计算的逻辑关。例如,分值高达 16 分的第 22 题(遗传大题),大模型普遍表现不佳,得分最高的 ChatGPT 也仅拿到 9 分。该题重点考察基因型分析、遗传概率计算等,这恰恰是考验模型在抽象信息基础上进行多步推理的能力。
文综:AI 的舒适区
在今年的 AI 高考评测中,文科综合依然是 AI 的高分舒适区。早在去年,ChatGPT 就已拿下文综 237 分的高分。而今年,元宝更是将文综最高分推升至 253.5 分,这一成绩,与理科综合最高分(213.25 分)形成了鲜明对比。
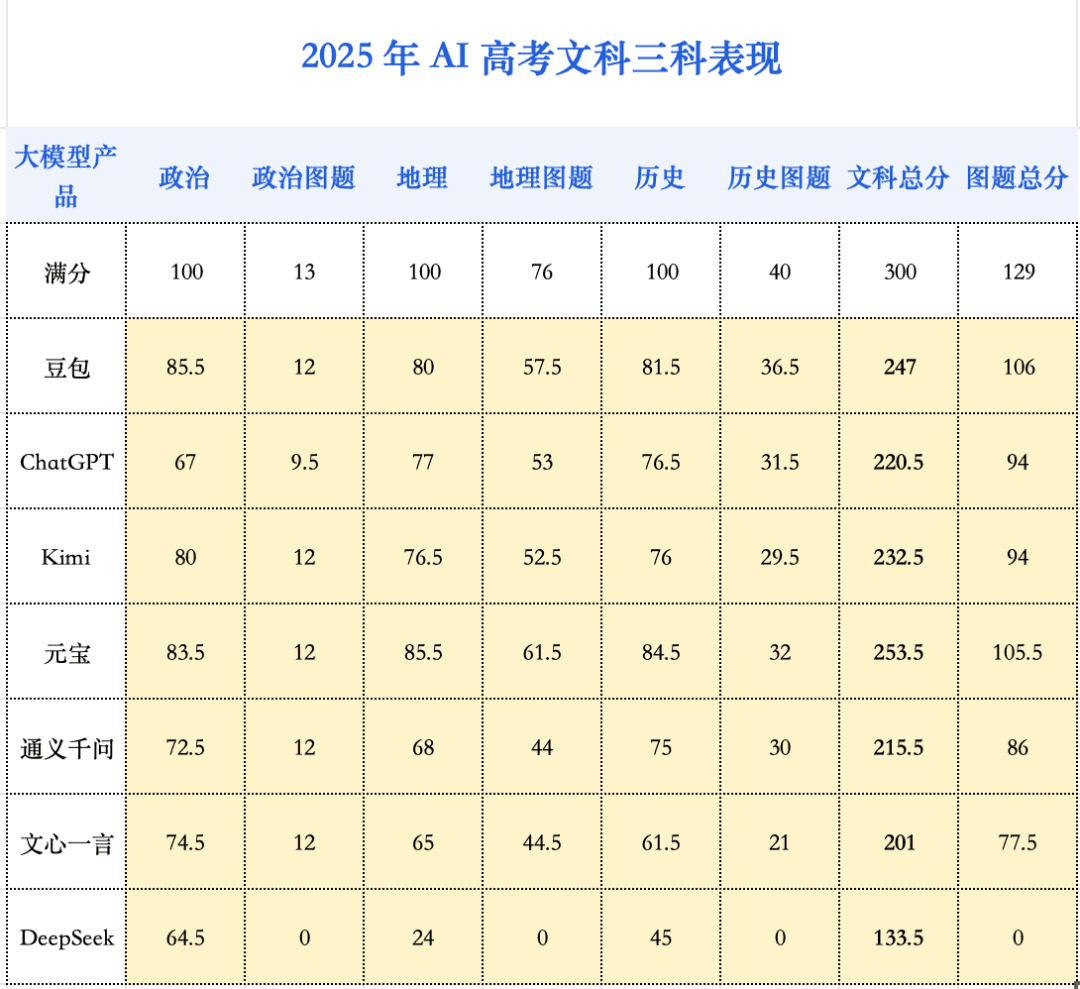
今年的分数增长,主要由地理科目贡献。得益于多模态能力的飞跃,AI 在地理图题上的理解力显著增强,使得该科目平均分激增了 20.3 分,成为进步的火车头。
- 地理:AI 在地理图题上的理解力显著增强,使得该科目平均分激增了 20.3 分,成为进步的火车头。
- 政治和历史:分数则基本处于高位平台期,并未呈现显著进步。DeepSeek-R1 就因思路过于发散、偏离考点而大量失分。而在历史小论文上,AI 普遍难以做到对历史原因进行深刻的多维度剖析,论述仍显单薄。
AI 眼镜作弊?尚不成熟
今年的高考也迎来了一项新变化:考场安检门全面升级,旨在精准防范智能眼镜等新型作弊工具。那么,这些新兴的、能与视频进行实时交互的多模态大模型,真的能用来在考场上「大显神通」吗?
我们选择国外的 ChatGPT 与国内的元宝,进行了一次非常规的测试。结果表明,视频大模型仍处于非常早期的阶段,存在严重的幻觉问题、被动的交互模式以及混乱的结果等问题。

AI 的审美偏好
我们进行了一项有趣的尝试: 让参与本次评测的大模型们,对彼此生成的作文进行交叉打分和排序。结果表明,模型并没有表现出对自家作品的特殊偏爱,AI 与人类判分员的审美,大方向仍然是一致的。
结论
今年,或许是高考测试对大模型仍具挑战意义的最后一年。当 AI 已经能展现出冲击顶尖学府的实力时,这个人类社会的智能筛选器,可能未来不再能成为对 AI 有区分度的测试了。
高考测试,不仅仅是一场对人类智慧与 AI 智慧的对比,也是我们观察 AI 智能发展的一个刻度表。AI 正加速逼近甚至超越普通人的能力边界。但它的发展并非线性——它能攻克人类眼中的难题,却也会在看似简单的题目上意外失足。高考,这个完美融合了知识掌握、逻辑推理与应试策略的综合场景,让 AI 展现出了它最迷人而矛盾的一面:它时而展现出顶尖人类的才华,轻而易举地攻克难题;时而又暴露出孩童般的认知盲区,在基础问题上犯下令人啼笑皆非的错误。










