
AI版权争议:Meta Llama 3.1与《哈利·波特》的法律迷局
近年来,人工智能(AI)技术飞速发展,尤其在生成式AI领域,其强大的内容创作能力令人瞩目。然而,随之而来的版权问题也日益凸显,成为法律界和科技界共同关注的焦点。围绕AI模型训练过程中使用受版权保护的材料,以及AI生成内容与原始版权作品之间的关系,一系列诉讼案陆续浮出水面。
其中,最引人关注的莫过于针对Meta的诉讼。原告方指控Meta在训练其AI模型时,使用了大量受版权保护的图书、报纸、代码和照片等材料,侵犯了版权所有者的权益。诉讼的核心问题在于,AI模型是否能够轻易地复制原告享有版权的内容,以及这种复制行为是否构成侵权。
《纽约时报》在2023年12月对OpenAI提起的诉讼中,提供了大量证据,表明GPT-4能够精确复现《纽约时报》文章中的重要段落。OpenAI对此辩解称,这只是一种“边缘行为”,并且公司正在努力解决这个问题。然而,事实果真如此吗?AI公司是否真的有效控制了模型对版权内容的“记忆”和复制能力?
为了深入探究这一问题,斯坦福大学、康奈尔大学和西弗吉尼亚大学的计算机科学家和法学专家组成的研究团队,针对五种流行的开源模型进行了深入研究。这些模型包括Meta的三款Llama模型,以及微软和EleutherAI的各一款模型。研究人员重点关注这些模型是否能够复现Books3中的文本。Books3是一个广泛用于训练大型语言模型(LLM)的图书集合,其中包含了大量受版权保护的作品。
研究结果令人震惊。下图展示了Llama 3.1 70B模型复现《哈利·波特与魔法石》中50个token片段的难易程度。颜色越深,表示该片段越容易被模型复现。
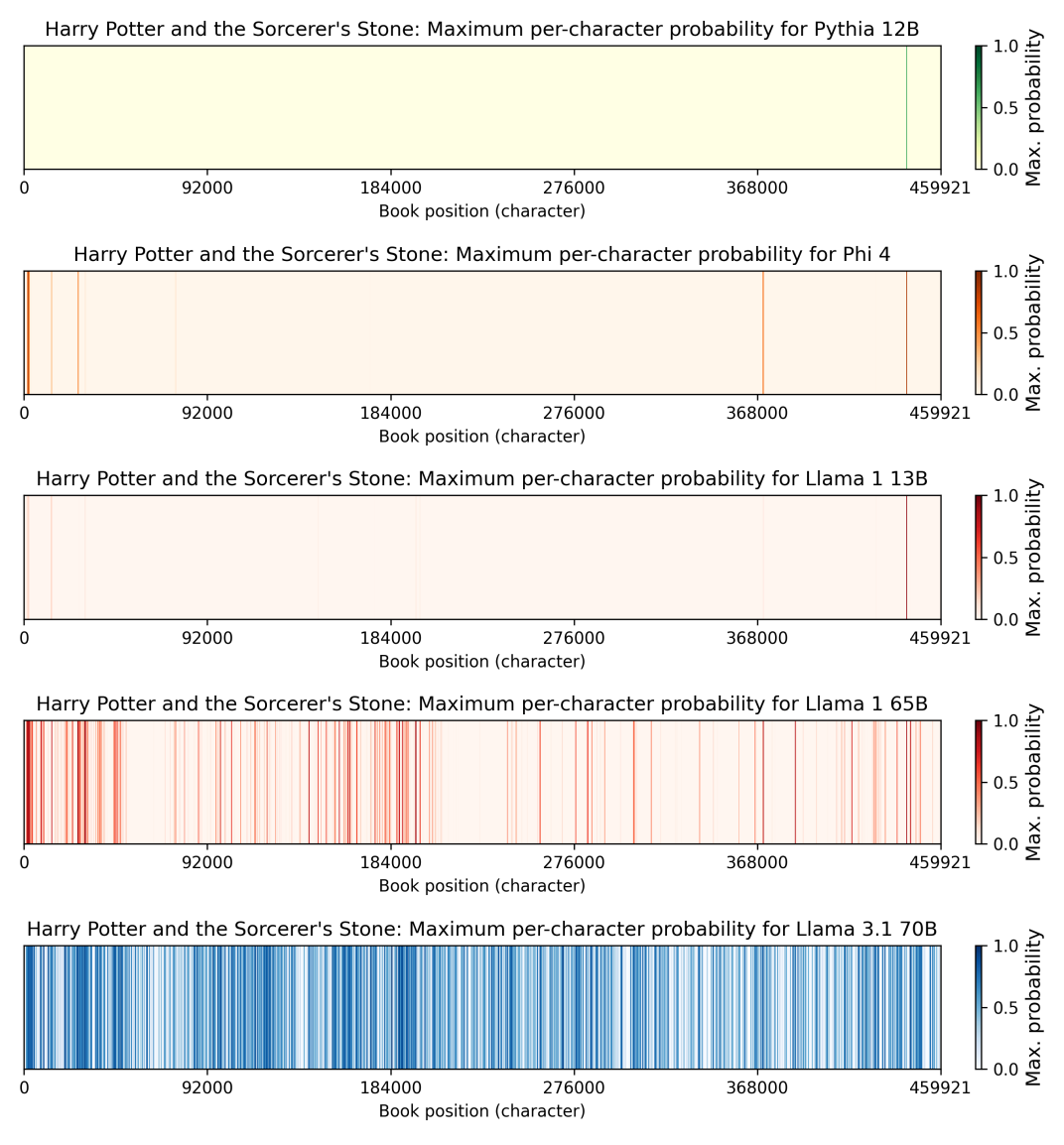
研究表明,Meta在2024年7月发布的Llama 3.1 70B模型,比其他四款模型更容易复现《哈利·波特》的文本。具体而言,该模型能够以至少50%的概率复现《哈利·波特与魔法石》中42%的50-token片段。相比之下,2023年2月发布的Llama 1 65B模型仅能复现4.4%的片段。
这一发现表明,尽管存在潜在的法律风险,Meta在训练Llama 3时并未采取有效措施来防止模型记忆和复制训练数据。至少对于《哈利·波特》这本书而言,这个问题在Llama 3中变得更加严重。
研究人员还发现,Llama 3.1 70B模型更容易复现《霍比特人》和《1984》等热门图书,而非冷门图书。对于大多数图书而言,Llama 3.1 70B模型的记忆能力都超过了其他模型。
康奈尔大学法学教授James Grimmelmann表示:“不同模型在记忆和复现文本方面的差异非常显著。” 斯坦福大学法学教授Mark Lemley也对此表示惊讶。Lemley曾是Meta法律团队的一员,但在Facebook采取了对特朗普更友好的审核政策后,于2024年1月解除了与Meta的客户关系。Lemley表示:“我们原本预计可复制的比例会很低,大约在1%到2%之间。最让我惊讶的是模型之间的差异。”
这项研究结果为AI版权辩论的各方提供了论据。对于AI行业的批评者而言,这项研究表明,至少对于某些模型和某些图书而言,记忆和复制并非一种边缘现象。另一方面,研究也发现,模型主要记忆和复制的是少数热门图书。例如,Llama 3.1 70B模型仅记忆了0.13%的《Sandman Slim》。
对于针对AI公司的集体诉讼而言,这种差异可能会带来麻烦。《Sandman Slim》的作者Richard Kadrey是针对Meta的集体诉讼的首席原告。要获得集体诉讼的资格,法院必须认定原告的法律和事实情况基本相似。如果不同作者的作品被AI模型记忆和复制的程度差异很大,那么将J.K. Rowling、Kadrey和其他数千名作者纳入同一集体诉讼是否合理,就存在疑问。这可能会对Meta有利,因为大多数作者缺乏提起个人诉讼的资源。
这项研究更重要的意义在于,版权案件的细节至关重要。长期以来,关于“生成模型是复制训练数据,还是仅仅从中学习”的讨论,往往被视为一种理论甚至哲学问题。但这个问题可以通过实证方法进行检验,而且答案可能因模型和作品而异。
如何衡量记忆能力
我们通常认为,LLM是在预测下一个token。但实际上,模型所做的是生成一个关于下一个token的所有可能性的概率分布。例如,如果你用“Peanut butter and”提示LLM,它会生成一个概率分布,如下例所示:
- P(“jelly”) = 70%
- P(“sugar”) = 9%
- P(“peanut”) = 6%
- P(“chocolate”) = 4%
- P(“cream”) = 3%
模型会根据这些概率随机选择一个选项。因此,70%的情况下,系统会生成“Peanut butter and jelly”。9%的情况下,会生成“Peanut butter and sugar”。6%的情况下,会生成“Peanut butter and peanut”。
研究人员不必生成多个输出来估计特定响应的可能性。相反,他们可以计算每个token的概率,然后将它们相乘。
假设有人想估计模型用“peanut butter and jelly”响应“My favorite sandwich is”的可能性。计算方法如下:
- 用“My favorite sandwich is”提示模型,并查找“peanut”的概率(假设为20%)。
- 用“My favorite sandwich is peanut”提示模型,并查找“butter”的概率(假设为90%)。
- 用“My favorite sandwich is peanut butter”提示模型,并查找“and”的概率(假设为80%)。
- 用“My favorite sandwich is peanut butter and”提示模型,并查找“jelly”的概率(假设为70%)。
然后,将这些概率相乘:
- 2 * 0.9 * 0.8 * 0.7 = 0.1008
因此,我们可以预测,模型大约在10%的情况下会生成“peanut butter and jelly”,而无需实际生成100或1000个输出,然后统计有多少个输出是这个短语。
这种技术大大降低了研究成本,使研究人员能够分析更多的书籍,并精确地估计非常低的概率。
例如,研究人员估计,要精确地复制某些书籍中的某些50-token序列,需要超过10千万亿个样本。显然,实际生成这么多输出是不现实的。但没有必要这样做:只需将50个token的概率相乘,就可以估计概率。
需要注意的是,概率会很快变得非常小。在上面的例子中,模型生成“peanut butter and jelly”这四个token的概率仅为10%。如果添加更多的token,概率会变得更低。如果添加46个token,概率可能会下降几个数量级。
对于任何语言模型而言,“偶然”生成任何给定的50-token序列的概率都非常小。如果模型生成了受版权保护的作品中的50个token,那么就有充分的证据表明这些token“来自”训练数据。即使它仅以10%、1%或0.01%的概率生成这些token,也是如此。
我们不知道《哈利·波特》是如何进入Llama模型的
研究人员选取了36本书,并将每本书分成重叠的100-token段落。使用前50个token作为提示,他们计算了后50个token与原始段落相同的概率。如果模型以大于50%的概率逐字复现该段落,则认为该段落被“记忆”。
这个定义非常严格。要使一个50-token序列的概率大于50%,该段落中平均每个token的概率需要至少为98.5%! 此外,研究人员只计算完全匹配的情况。他们没有尝试计算模型生成了原始段落中的48或49个token,但有一个或两个token错误的情况。如果计算这些情况,记忆量会更高。
这项研究提供了强有力的证据,表明《哈利·波特与魔法石》的大部分内容被复制到了Llama 3.1 70B模型的权重中。但这并没有告诉我们为什么或如何发生这种情况。我怀疑部分原因是Llama 3 70B模型是在15万亿个token上训练的,是Llama 1 65B模型的10倍以上。
模型在特定示例上训练的次数越多,就越有可能记住该示例。也许Meta很难找到15万亿个不同的token,因此它多次在Books3数据集上进行了训练。或者,Meta可能添加了第三方来源,例如在线哈利·波特粉丝论坛、消费者图书评论或学生读书报告,其中包含《哈利·波特》和其他热门图书的引言。
我不确定这些解释是否完全符合事实。最受欢迎的图书的记忆问题更为严重,这表明Llama可能是在引用这些图书的二级来源上进行训练的,而不是在图书本身上进行训练的。关于《哈利·波特》的在线讨论可能比《Sandman Slim》多得多。
另一方面,Llama记忆了如此多的《哈利·波特与魔法石》仍然令人惊讶。
Lemley说:“如果是引文,你会期望它集中在每个人都引用或谈论的一些流行事物周围。” Llama 3记忆了近一半的书这一事实表明,整个文本在训练数据中得到了很好的体现。
或者可能有另一种解释。也许Meta在其训练配方中做出了细微的更改,意外地加剧了记忆问题。我上周通过电子邮件发送给Meta征求意见,但尚未收到回复。
Mark Lemley告诉我:“似乎并非所有流行的书籍都如此。有些流行的书籍有这个结果,而另一些则没有。很难提出一个明确的理由来解释为什么会发生这种情况。”
三种责任理论
实际上,关于在受版权保护的作品上训练模型如何侵犯版权,有三种不同的理论:
- 在受版权保护的作品上进行训练本质上是侵权的,因为训练过程涉及制作作品的数字副本。
- 训练过程将信息从训练数据复制到模型中,使模型成为版权法下的衍生作品。
- 当模型生成受版权保护的作品的(部分)时,就会发生侵权。
到目前为止,很多讨论都集中在第一种理论上,因为它对AI公司最具威胁性。如果法院支持这一理论,那么无论当前的LLM是否记住了任何训练数据,它们中的大多数都将是非法的。
AI行业有一些非常有力的论据,认为根据2015年Google图书的裁决,在训练过程中使用受版权保护的作品是合理使用。但是,Llama 3.1 70B记住了《哈利·波特》的大部分内容可能会影响法院如何考虑这些合理使用问题。
合理使用分析的关键部分是使用是否具有“变革性”,即公司是否创造了新的东西,或者仅仅是从他人的作品中获利。语言模型能够反刍《哈利·波特》、《1984》和《霍比特人》等流行作品的大部分内容这一事实,可能会导致法官对这些合理使用论点持更怀疑的态度。
此外,Google在图书案例中的一个关键论点是,其系统旨在永远不会返回任何书籍中的短篇。如果Meta诉讼案中的法官想将Meta的论点与Google在图书案例中的论点区分开来,他可以指出Llama可以生成远远超过几行《哈利·波特》的内容。
这项新的研究“使被告在这些案件中一直在讲述的故事复杂化”,合著者Mark Lemley告诉我。“也就是说,我们只是学习单词模式。没有一个出现在模型中。”
但是,哈利·波特的结果给Meta带来了更大的危险,即根据第二种理论,Llama本身就是Rowling图书的衍生副本。
Lemley说:“很明显,你可以从模型中提取《哈利·波特》和各种其他书籍的实质部分。这向我表明,对于其中的一些书籍,可能存在法律会称为该书一部分副本的内容。”
Google图书的先例可能无法保护Meta免受这种第二种法律理论的侵害,因为Google从未将其图书数据库提供给用户下载。如果Google这样做,几乎肯定会输掉官司。
原则上,Meta仍然可以使法官相信,根据灵活的、法官制定的合理使用原则,允许复制《哈利·波特》的42%。但这将是一场艰苦的战斗。
Lemley说:“您必须进行的合理使用分析不仅是'训练集是否合理使用',而且是'模型中的合并是否合理使用?' 这使被告的故事复杂化。”
Grimmelmann还说,这项研究可能会使开放权重模型比封闭权重模型面临更大的法律风险。康奈尔大学和斯坦福大学的研究人员只能进行他们的工作,因为作者可以访问基础模型,因此可以访问令牌概率值,从而可以有效地计算令牌序列的概率。
包括OpenAI,Anthropic和Google在内的大多数领先实验室都越来越多地限制对这些所谓的logits的访问,从而使研究这些模型变得更加困难。
此外,如果一家公司将其模型权重保留在其自己的服务器上,则可以使用过滤器来尝试防止侵权输出到达外界。因此,即使底层的OpenAI,Anthropic和Google模型以与Llama 3.1 70B相同的方式记住了受版权保护的作品,公司外部的任何人都可能难以证明这一点。
此外,这种过滤使拥有封闭权重模型的公司更容易援引Google图书的先例。简而言之,版权法可能会对公司发布开放权重模型产生强大的抑制作用。
Mark Lemley告诉我:“这有点变态。我不喜欢这个结果。”
另一方面,法官可能会得出结论,有效地惩罚公司发布开放权重模型是不好的。
Grimmelmann告诉我:“在某种程度上,保持开放和共享权重是一种公共服务。我真的可以发现法官不太怀疑Meta和其他提供开放权重模型的人。”










