
近日,德国知名技术咨询公司 TNG 发布了 DeepSeek 的增强版 ——DeepSeek-TNG-R1T2-Chimera,标志着深度学习模型在推理效率和性能上的又一次重大突破。据称,新版本在推理效率上提升了 200%,并且通过创新的 AoE(Adaptive Expert)架构显著降低了推理成本。这一进展无疑为 AI 领域带来了新的可能性,预示着更高效、更经济的 AI 应用即将到来。
创新的 AoE 架构:深度解析
Chimera 版本是基于 DeepSeek 的 R1-0528、R1 和 V3-0324 三大模型的混合开发,其核心在于采用了全新的 AoE 架构。该架构通过对混合专家(MoE)架构的细致优化,能够更高效地利用模型参数,从而在提升推理性能的同时,显著节省 token 输出。这种架构的创新性在于其自适应性,能够根据不同的任务和数据特点,动态调整模型的参数使用,从而实现最优的性能表现。
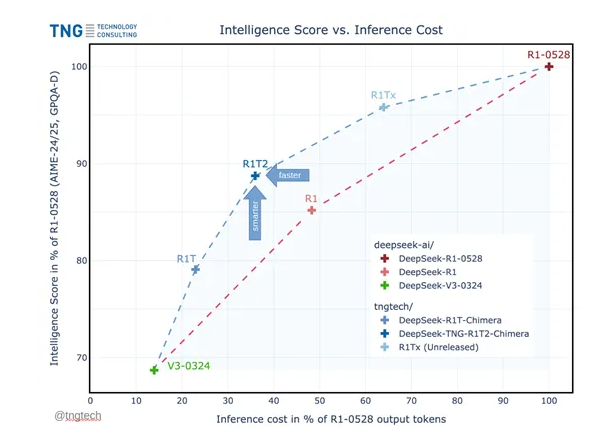
在多项主流测试基准(如 MTBench、AIME-2024)中,Chimera 版本的表现均优于普通 R1 版本,展现出卓越的推理能力和经济性。这些测试结果充分证明了 AoE 架构的有效性,以及 Chimera 版本在实际应用中的巨大潜力。
MoE 架构的优势:技术背景
要深入理解 AoE 架构,首先需要了解混合专家(MoE)架构的基本原理。MoE 架构将 Transformer 的前馈层划分为多个“专家”,每个输入标记仅会路由到部分专家。这种方法能够有效提高模型的效率和性能,因为它允许模型针对不同的输入采用不同的处理方式。
以 2023 年 Mistral 推出的 Mixtral-8x7B 模型为例,尽管其激活的参数数量仅为 13 亿,却能够与拥有 700 亿参数的 LLaMA-2-70B 模型相媲美,推理效率提高了 6 倍。这一案例充分展示了 MoE 架构的强大优势,以及其在提升模型性能和效率方面的巨大潜力。
AoE 架构正是利用了 MoE 的细粒度特性,允许研究者从现有的混合专家模型中构建具有特定能力的子模型。通过插值和选择性合并父模型的权重张量,生成的新模型不仅保留了优良特性,还能够根据实际需求灵活调整其性能表现。这种灵活性使得 AoE 架构能够适应各种不同的应用场景,从而实现更广泛的应用。
研究者选择了 DeepSeek-V3-0324 和 DeepSeek-R1 作为父模型,基于不同的微调技术,使得这两个模型在推理能力和指令遵循方面都表现卓越。这种选择的合理性在于,这两个模型在各自的领域内都具有领先的性能,它们的结合可以充分发挥各自的优势,从而实现更强大的整体性能。
权重合并与优化:技术细节
在构建新的子模型过程中,研究者首先需要准备父模型的权重张量,并通过解析权重文件进行直接操作。接着,通过定义权重系数,研究者可以平滑地插值和合并父模型的特征,生成新的模型变体。这一过程需要精细的调校和优化,以确保新模型能够继承父模型的优点,并在此基础上有所提升。
在合并过程中,研究者引入了阈值控制与差异筛选机制,确保只有在显著差异的情况下,才将相关张量纳入合并范围,从而减少模型复杂性和计算成本。这种机制的引入,有效地避免了模型过度复杂化,从而保证了模型的效率和稳定性。
在 MoE 架构中,路由专家张量是至关重要的组成部分,它决定了输入标记在推理过程中选择的专家模块。AoE 方法特别关注这些张量的合并,研究者发现,通过优化路由专家张量,可以显著提升子模型的推理能力。这种优化对于提升模型的整体性能至关重要,因为它直接影响了模型对输入的理解和处理方式。
最终,通过 PyTorch 框架,研究者实现了模型的合并。合并后的权重被保存到新的权重文件中,生成了新的子模型,展现出高效性和灵活性。这一过程的实现,标志着 AoE 架构在技术上的成熟和可行性,为未来的研究和应用奠定了坚实的基础。

未来展望:AI 领域的革命性突破
DeepSeek-TNG-R1T2-Chimera 的推出,不仅仅是一个新版本的发布,更代表了 AI 领域在推理效率和成本控制方面的一次革命性突破。其创新的 AoE 架构,为未来的 AI 模型设计提供了新的思路和方向。可以预见,随着 AoE 架构的不断完善和应用,未来的 AI 模型将更加高效、智能、经济,从而为各行各业带来更大的价值。
该模型的开源地址为:https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera,有兴趣的开发者可以自行研究。
更深入的思考:AI 技术的未来发展趋势
除了 DeepSeek-TNG-R1T2-Chimera 带来的技术革新,我们还需要对 AI 技术的未来发展趋势进行更深入的思考。以下是一些可能的方向:
- 模型小型化与边缘计算:随着移动设备和物联网设备的普及,AI 模型的小型化和边缘计算能力将变得越来越重要。未来的 AI 模型需要在保证性能的同时,尽可能地减少计算资源的需求,从而能够在各种设备上运行。
- 自适应学习与持续进化:未来的 AI 模型需要具备更强的自适应学习能力,能够根据不同的任务和数据特点,自动调整自身的参数和结构。此外,还需要具备持续进化的能力,能够不断地从新的数据中学习,从而保持自身的竞争力。
- 多模态融合与跨领域应用:未来的 AI 模型需要能够处理多种类型的数据,例如文本、图像、语音等。此外,还需要能够将 AI 技术应用到各个不同的领域,例如医疗、金融、教育等。
- 伦理与安全:随着 AI 技术的不断发展,伦理和安全问题也变得越来越重要。未来的 AI 模型需要遵循伦理规范,保护用户隐私,防止被恶意利用。
总之,DeepSeek-TNG-R1T2-Chimera 的发布,只是 AI 技术发展道路上的一个里程碑。未来,我们还需要不断地探索和创新,才能真正实现 AI 技术的潜力,为人类社会带来更大的福祉。
技术细节的深度剖析
为了更深入地理解 DeepSeek-TNG-R1T2-Chimera 的技术原理,我们需要对其核心技术细节进行更深入的剖析。以下是一些关键的技术点:
- AoE 架构的自适应性:AoE 架构的核心在于其自适应性,它能够根据不同的输入数据和任务需求,动态调整模型的参数使用。这种自适应性是通过一种特殊的路由机制实现的,该机制能够根据输入数据的特征,选择最合适的专家模块进行处理。
- 权重合并的策略:在权重合并过程中,研究者采用了多种策略来保证合并后的模型能够继承父模型的优点,并在此基础上有所提升。例如,他们采用了阈值控制和差异筛选机制,只合并那些具有显著差异的权重张量。此外,他们还对路由专家张量进行了优化,以提升子模型的推理能力。
- PyTorch 框架的应用:PyTorch 是一个非常流行的深度学习框架,它提供了丰富的工具和接口,方便研究者进行模型的设计、训练和部署。DeepSeek-TNG-R1T2-Chimera 的实现,离不开 PyTorch 框架的支持。
实际应用场景的展望
DeepSeek-TNG-R1T2-Chimera 的高性能和低成本,使得它在各种实际应用场景中都具有巨大的潜力。以下是一些可能的应用场景:
- 智能客服:DeepSeek-TNG-R1T2-Chimera 可以被用于构建更智能的客服系统,能够更快速、更准确地回答用户的问题,提高客户满意度。
- 机器翻译:DeepSeek-TNG-R1T2-Chimera 可以被用于构建更高质量的机器翻译系统,能够更准确地翻译各种语言,促进国际交流。
- 内容生成:DeepSeek-TNG-R1T2-Chimera 可以被用于自动生成各种类型的内容,例如新闻报道、产品描述、广告文案等,提高内容生产效率。
- 智能推荐:DeepSeek-TNG-R1T2-Chimera 可以被用于构建更精准的智能推荐系统,能够更准确地预测用户的兴趣,提高推荐效果。
总之,DeepSeek-TNG-R1T2-Chimera 的应用前景非常广阔,它有望在各个领域都发挥重要的作用。










