
在人工智能领域,每天都有新的突破和创新涌现。2025年7月3日,AI领域再次迎来一波重磅更新。本文将深入探讨B站、字节跳动、DeepSWE、Stability AI、谷歌和Topview等公司在AI领域的最新进展,并分析这些技术突破对行业的影响。
字节跳动EX-4D:单目视频秒变4D大片
字节跳动PICO-MR团队开源了EX-4D框架,这一技术能够将单目视频转化为高质量、多视角的4D视频序列。传统的视频生成技术在多视角生成方面面临诸多挑战,而EX-4D通过深度密闭网格(DW-Mesh)和轻量级适配架构,有效解决了这些问题。EX-4D在FID、FVD和VBench等指标上均超越了现有的开源方法,展现出卓越的性能表现。这项技术为影视制作、游戏开发等领域带来了新的可能性,让用户能够以更加沉浸式的方式体验视频内容。

EX-4D的实现,依赖于深度密闭网格(DW-Mesh)技术,该技术能够从单目视频中提取出高质量的深度信息,并以此生成多视角的视频内容。此外,EX-4D还采用了渲染mask和跟踪mask策略,解决了多视角数据稀缺的问题,进一步提升了生成视频的质量。通过这些创新技术的应用,EX-4D在性能指标上全面超越了现有开源方法,为4D视频生成领域树立了新的标杆。未来,随着EX-4D的不断发展和完善,有望在虚拟现实、增强现实等领域发挥更大的作用。
Bilibili AniSora V3:动漫视频生成再升级
Bilibili开源的动漫视频生成模型AniSora V3迎来了重大更新,显著提升了生成质量、动作流畅度和风格多样性。AniSora V3基于CogVideoX-5B和Wan2.1-14B模型,结合强化学习与人类反馈(RLHF)框架,支持多种动漫风格的视频生成。这一技术为动漫创作者提供了强大的工具,让他们能够更加便捷地创作出高质量的动漫内容。
AniSora V3通过时空掩码模块优化,增强了动画任务的控制能力。这一模块能够精细地控制视频中各个元素的变化,从而生成更加流畅、自然的动画效果。此外,AniSora V3还支持多任务处理,包括单帧图像生成视频、关键帧插值和唇部同步等功能,进一步拓展了其应用范围。Bilibili选择开源AniSora V3,旨在推动社区协作,让更多的开发者参与到动漫视频生成技术的发展中来。通过开源,AniSora V3能够吸纳更多的创新思想和技术,不断提升其性能和功能。
DeepSWE:AI Agent系统强势登顶
DeepSWE是一款基于Qwen3-32B模型的开源AI Agent系统,通过强化学习进行训练,并在SWE-Bench-Verified测试中取得了出色的性能表现。DeepSWE采用了rLLM框架和改进的GRPO++算法,在软件工程任务中展现出强大的学习能力与应用潜力。这一成果表明,AI Agent在软件开发领域具有广阔的应用前景,能够帮助开发者提高工作效率,降低开发成本。
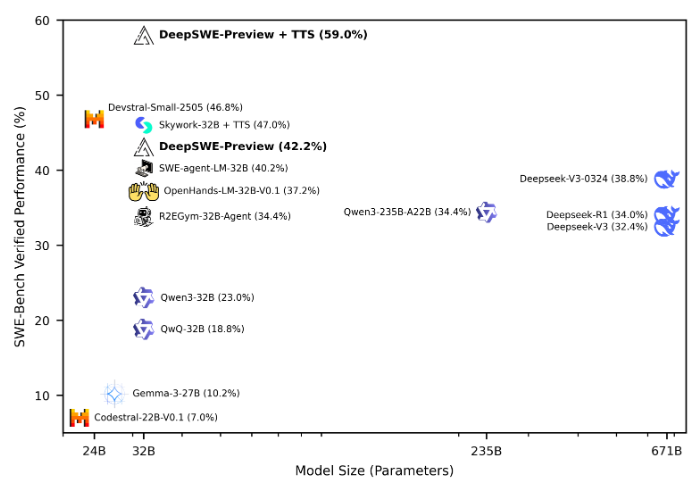
DeepSWE在SWE-Bench-Verified测试中表现出色,Pass@1准确率达到了59%,成为所有开源代理中的佼佼者。这一成绩的取得,离不开DeepSWE所采用的rLLM框架和改进的GRPO++算法。rLLM框架能够有效地利用大型语言模型的能力,提升AI Agent的推理和决策能力。而改进的GRPO++算法,则能够更加高效地进行强化学习,使AI Agent在软件工程任务中不断提升自身的能力。DeepSWE的开源,将为更多的开发者提供一个强大的AI Agent系统,助力软件工程领域的发展。
字节跳动VINCIE-3B:上下文连续图像编辑
字节跳动开源了支持上下文连续图像编辑的VINCIE-3B模型,该模型基于MM-DiT架构开发,能够从视频中学习并实现高效的图像编辑。VINCIE-3B的技术亮点包括视频驱动训练、块因果扩散变换器以及三重代理任务训练,显著提升了图像编辑的质量和效率。这项技术为视频编辑、图像处理等领域带来了新的可能性,让用户能够更加便捷地对图像进行编辑和修改。
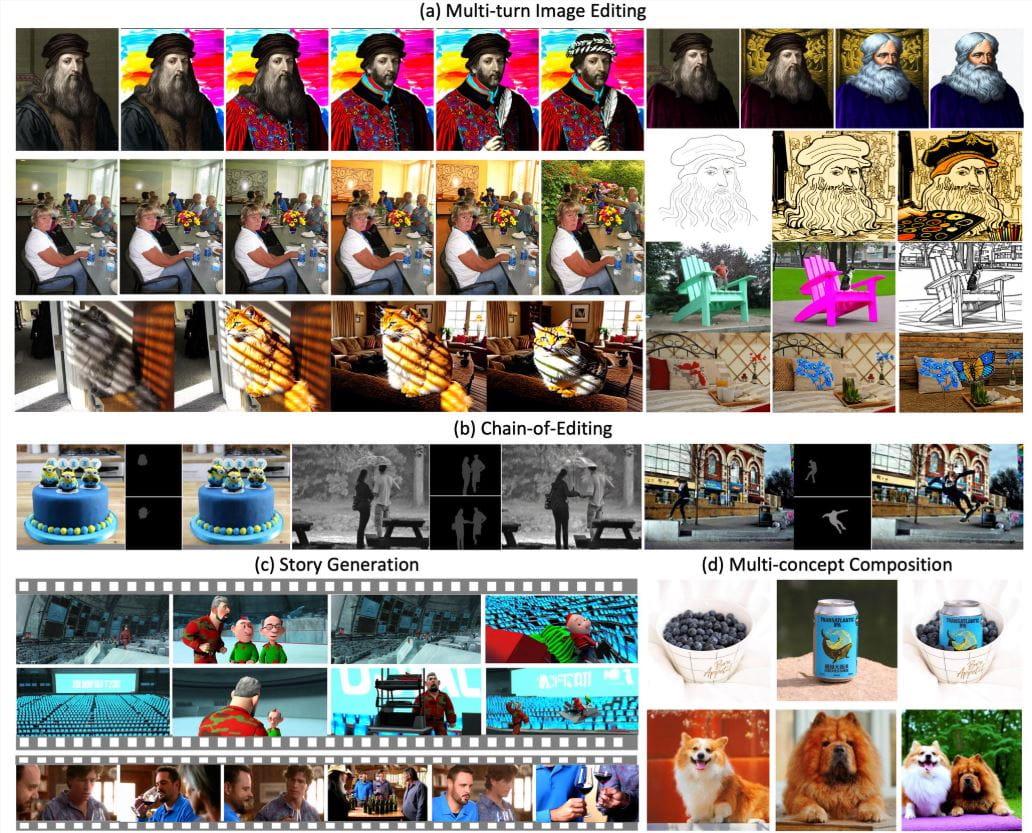
VINCIE-3B的视频驱动训练方法,能够利用视频的连续帧,自动提取文本描述与图像序列,构建多模态训练数据。这种方法不仅能够提高模型的训练效率,还能够使模型更好地理解图像的上下文信息,从而生成更加自然的编辑效果。此外,VINCIE-3B还采用了块因果扩散变换器,在文本和图像块之间实现因果注意力,块内则为双向注意力,进一步提升了图像编辑的质量。通过下一帧预测、当前帧分割预测和下一帧分割预测三种任务进行训练,VINCIE-3B能够增强模型对动态场景和物体关系的理解能力,从而实现更加高效的图像编辑。
Stability AI Stable Audio Open Small:手机秒变音频创作神器
Stability AI与Arm合作推出了Stable Audio Open Small,这是一款专为移动设备优化的轻量级文本到音频生成模型。Stable Audio Open Small在移动端本地运行,支持离线处理,具备高效、低延迟和高质量输出的特点。这一技术推动了AI音频生成技术向边缘计算和移动设备的转型,让用户能够随时随地进行音频创作。
Stable Audio Open Small的参数量压缩至341M,使其能够在移动端流畅运行。同时,该模型支持立体声音频生成,无需云端处理,进一步提升了音频生成的效率。Stability AI选择开源Stable Audio Open Small,旨在降低技术门槛,鼓励更多的开发者参与到AI音频生成技术的创新中来。通过开源,Stable Audio Open Small能够吸纳更多的创意应用,推动AI音频生成技术的发展。
谷歌Gemini for Education:免费AI工具席卷全球教育
谷歌推出了全新的AI工具套件Gemini for Education,基于最新一代Gemini2.5Pro模型和LearnLM学习型大模型,为全球师生提供免费、强大且高效的学习与教学支持。Gemini for Education覆盖30多种功能,支持40多种语言,旨在通过AI技术赋能教育工作者和学生,打造更加个性化和高效的学习体验。这一举措有望在全球范围内推动教育的普及和发展。
Gemini for Education支持40多种语言,覆盖230多个国家和地区,真正实现了全球化教育赋能。更重要的是,Gemini for Education对所有Google Workspace for Education用户完全免费,从而推动了教育的公平。谷歌在Gemini for Education中严格遵循隐私条款,确保用户数据的安全。通过这些举措,谷歌希望能够让更多的师生享受到AI技术带来的便利,从而提升教育的质量和效率。
Topview Avatar2:AI数字人革新电商带货
Topview Avatar2通过突破性的功能和逼真的效果,为出海电商和内容创作者带来了革命性的体验。其创新的AI数字人技术能够实现产品与数字人的自然交互,极大提升了视频制作效率和内容质量。这一技术有望颠覆传统的电商带货模式,开启AI数字人带货的新时代。

Topview Avatar2全球首创AI数字人“穿戴”产品,实现了更真实的交互效果。通过一键生成定制化视频,Topview Avatar2支持多语言口型同步,提升了营销的灵活性。Topview Avatar2的出现,革新了传统的UGC视频模式,降低了电商拍摄的门槛,助力品牌全球化。随着AI数字人技术的不断发展,相信未来会有更多的电商企业采用AI数字人带货,从而提升营销的效果和效率。
Perplexity Max订阅计划:解锁无限AI生产力
Perplexity推出了高端订阅计划Max,定价为每月200美元或每年2000美元,旨在满足高频用户和专业人士的需求。Max计划提供无限量访问Labs、优先体验新功能以及最新前沿模型的支持,标志着Perplexity在AI生产力工具领域的进一步深耕。这一计划的推出,将为专业用户提供更加强大的AI生产力工具,助力他们更好地完成工作。
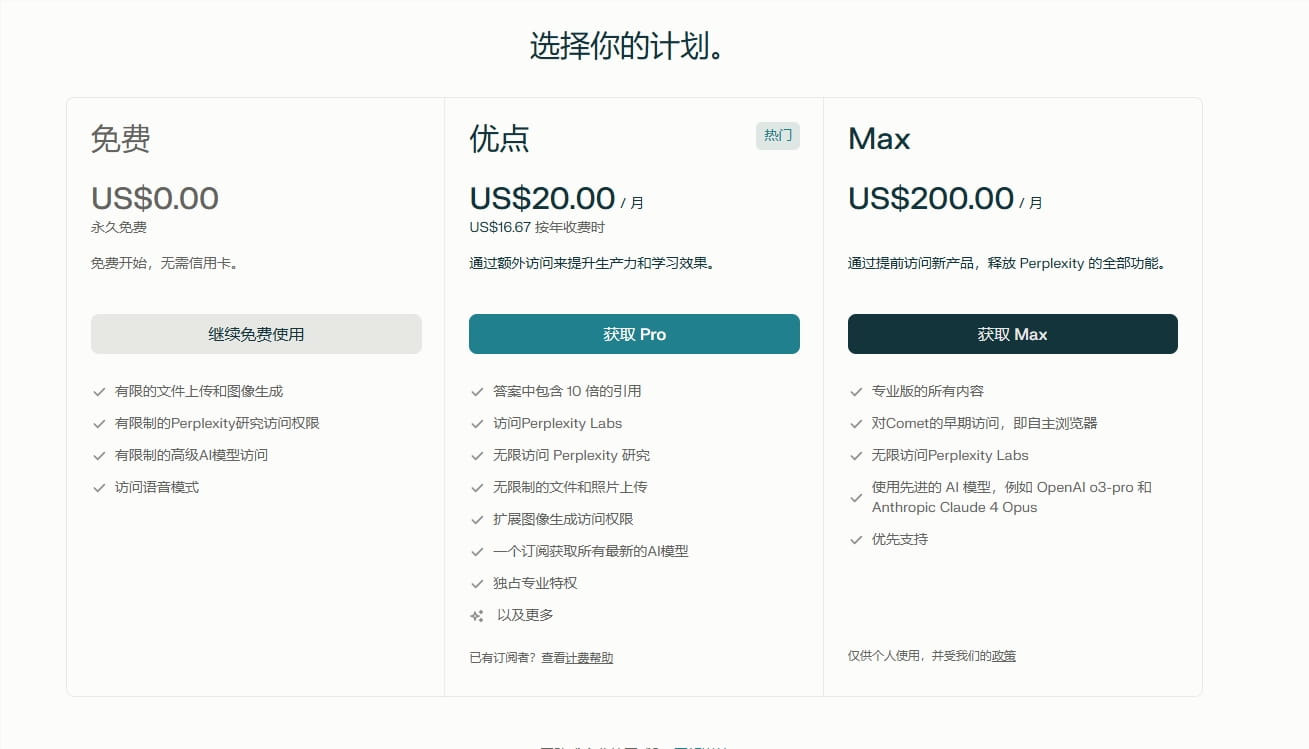
Perplexity Max计划提供无限Labs查询,能够满足专业用户对深度研究和复杂项目的需求。同时,Max计划还提供优先访问前沿模型的机会,确保用户始终站在技术前沿。此外,Perplexity Max计划还提供优先支持,包括专用基础设施和更快的客户响应时间。通过这些举措,Perplexity希望能够为专业用户提供更加优质的服务,从而提升他们的工作效率和生产力。
AI人才争夺战:Cursor挖角Anthropic核心人物
Cursor成功挖走Anthropic的两位核心人物,标志着AI编程市场竞争的加剧。尽管Anthropic面临人才流失,但其业务依然强劲,收入和估值显著增长。Anysphere则借助这些人才进一步提升产品竞争力。这一事件反映了AI领域人才的稀缺和重要性,也预示着未来AI领域的竞争将更加激烈。
OpenAI澄清:Robinh ood代币化股票与己无关
Robinh ood在欧洲推出了OpenAI和SpaceX的代币化股票,但OpenAI明确表示这些代币并非其股权,且与Robinh ood没有合作关系。尽管Robinh ood提供了限时优惠吸引用户,但美国用户无法参与。这一事件引发了市场的热烈反响,Robinh ood股价一度飙升。这一事件提醒投资者,在投资代币化股票时需要谨慎,了解清楚代币的性质和风险。










