
在人工智能领域,创新如潮水般涌现,不断刷新着我们对技术的认知。近日,AI领域又迎来了一系列令人瞩目的进展,从智谱AI的PPT生成功能到NVIDIA的3D场景重建技术,再到谷歌DeepMind的AI工作流开源项目,每一项都预示着AI技术的巨大潜力。本文将深入剖析这些前沿动态,并探讨其对未来内容创作、产品设计以及软件开发等领域的深远影响。
智谱AI的AI Slides:PPT制作的效率革命
智谱AI全新推出的AI Slides功能,无疑为PPT制作领域带来了一场效率革命。该功能基于强大的GLM-Experimental模型,能够根据用户提供的主题或文档,快速生成结构清晰、图文并茂的高质量PPT。更令人惊喜的是,这项功能完全免费,用户可以通过chat.z.ai轻松体验。

AI Slides的出现,极大地降低了PPT制作的门槛。以往,制作一份高质量的PPT需要耗费大量的时间和精力,从内容构思到排版设计,每一个环节都需要精心打磨。而现在,只需输入主题或上传文档,AI Slides就能自动完成PPT的生成,大大节省了用户的时间和精力。此外,AI Slides还能够根据数据自动生成图表,使得PPT的内容更加直观易懂,信息传达更加高效。
可灵AI可图2.1:图像生成的全新高度
可灵AI发布的新一代图像生成模型——可图2.1,在图像生成能力上实现了显著提升。新模型不仅在指令遵循、人像美感和电影质感等方面表现出色,还具备强大的文字生成能力,支持超过180种风格响应,为用户提供了更加丰富的创作选择。
可图2.1的强大之处在于其对复杂指令的精准理解和执行能力。用户只需输入简单的指令,即可生成高质量的图像,无需具备专业的图像处理知识。同时,可图2.1还支持多种风格的图像生成,用户可以根据自己的需求,选择不同的风格,创作出独具特色的作品。这一功能的推出,无疑将极大地激发用户的创作热情,推动图像生成技术的发展。
NVIDIA DiffusionRenderer:3D场景重建的突破
NVIDIA及其合作伙伴推出的DiffusionRenderer技术,是一项突破性的创新,它将视频生成与编辑结合,实现了对3D场景的理解和操作。该模型通过神经逆渲染器和神经前向渲染器的协同工作,提升了视频的真实感和适应性,并在多项任务中表现出色。

DiffusionRenderer的出现,为3D场景的创作带来了全新的可能性。以往,创建和编辑3D场景需要专业的建模软件和复杂的操作流程,而现在,通过DiffusionRenderer,用户可以直接从视频中提取3D场景,并进行编辑和修改。这项技术不仅可以应用于电影制作、游戏开发等领域,还可以为虚拟现实、增强现实等应用提供强大的技术支持。
墨刀AI:原型设计的效率倍增器
墨刀AI推出的全新原型生成功能,让用户只需30秒即可从想法生成高保真、可编辑的原型。该功能支持多轮对话优化和局部修改,极大地提升了产品设计与验证的效率。

墨刀AI的强大之处在于其快速生成和灵活编辑的能力。用户只需输入简单的想法,墨刀AI就能自动生成高保真的原型,并且支持多终端适配和多轮对话优化。同时,用户还可以根据自己的需求,对原型进行局部修改,使得原型更加符合实际需求。这一功能的推出,将极大地缩短产品设计周期,降低产品设计成本,为产品创新提供强大的支持。
Higgsfield Soul ID:数字自我的全新表达
Higgsfield AI推出的Soul ID,是一款革命性的AI工具,它能够通过上传10张以上个人照片,生成高度个性化的虚拟形象。Soul ID的核心功能包括真实感与多样性的完美融合、多样化风格预设以及自动提示词优化,为内容创作者和时尚博主提供了强大的创作工具。
Soul ID的出现,为数字自我的表达带来了全新的方式。以往,人们只能通过照片、视频等方式来展示自己,而现在,通过Soul ID,用户可以创建一个高度个性化的虚拟形象,并在虚拟世界中自由地表达自己。这项技术不仅可以应用于社交娱乐领域,还可以为虚拟偶像、数字代言人等应用提供强大的技术支持。
谷歌DeepMind GenAI Processors:AI工作流构建的加速器
谷歌DeepMind开源的GenAI Processors库,为开发者提供了一个轻量级、高效的工具,用于构建异步、可组合的生成式AI工作流。该库支持多模态数据处理,显著提升了基于Gemini API的应用程序开发效率。
GenAI Processors的强大之处在于其模块化设计和异步流处理能力。开发者可以通过GenAI Processors,将复杂的AI工作流分解为多个模块,并进行组合和优化。同时,GenAI Processors还支持音频、视频和文本等多模态数据的异步流处理,极大地提升了实时应用的效率。这一开源项目的推出,将极大地推动AI技术的普及和应用,为开发者带来更多的创新机会。
谷歌Veo3:图像转视频功能的拓展
谷歌在AI视频生成领域持续发力,推出图像转视频功能并强化内容识别机制,显示出市场对AI创作工具的强烈需求。

谷歌通过Gemini应用程序新增的图像到视频生成功能,进一步扩展了AI创作工具的能力。用户可以上传照片生成视频片段,并添加描述音频,支持下载或分享作品。同时,所有使用Veo3模型生成的视频将带有可见和不可见的数字水印,确保内容的可追溯性。
Mistral AI Devstral2507:代码中心语言建模的突破
Mistral AI与All Hands AI合作推出的Devstral2507系列模型,包含开源的Devstral Small1.1和企业版的Devstral Medium2507。这些模型专注于代码推理、程序合成和结构化任务执行,适用于大型软件代码库的实际应用。
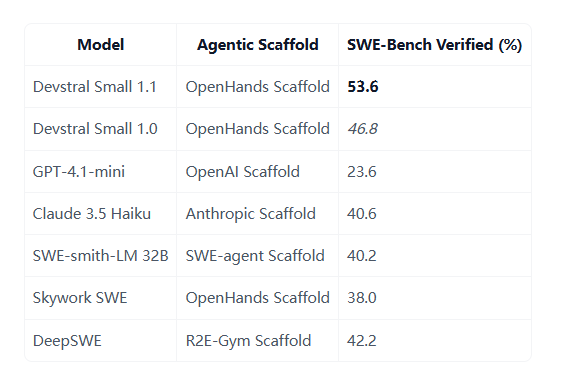
Devstral2507系列模型的出现,为代码中心语言建模带来了突破性的进展。这些模型不仅在代码推理和程序合成方面表现出色,还支持与代码代理框架集成,适用于从本地开发到企业级服务的多种应用场景。其中,Devstral Small1.1在SWE-Bench基准测试中得分53.6%,而Devstral Medium2507得分61.6%,后者表现优于一些商业模型。
结语
综上所述,近期AI领域涌现出的一系列创新,涵盖了内容创作、产品设计、3D场景重建、AI工作流构建以及代码中心语言建模等多个领域。这些技术的不断发展和完善,将为各行各业带来更多的机遇和挑战,推动人类社会向着更加智能化的未来迈进。我们有理由相信,在AI技术的驱动下,未来的世界将更加美好。

