
在科技日新月异的今天,人工智能(AI)正以前所未有的速度渗透到我们生活的方方面面。从赋能开发者到重塑音乐创作,再到革新视频生成,AI技术正在不断突破边界,开启新的可能性。本文将深入探讨近期AI领域的几项重大进展,剖析其技术特点、应用场景以及潜在影响。
Kimi Playground:AI从对话到智能助理的跃迁
月之暗面推出的Kimi Playground,标志着AI正在从被动的信息提供者向主动的问题解决者转变。通过集成工具调用功能,Kimi Playground能够主动分析问题、调用合适的工具并执行相应的操作,真正实现了AI的智能化。
这一平台为开发者提供了一站式的工具调用体验,支持多种工具的接入和调试,极大地提升了开发效率。例如,在数据分析场景中,Kimi Playground可以自动提取数据、进行分析并生成报告;在旅游行程规划场景中,它可以根据用户的偏好和预算,自动规划行程、预订机票和酒店。这种强大的自动化能力,将极大地简化复杂任务,释放人们的创造力。
OpenAI ChatGPT Agent:自主思考、行动的AI化身
OpenAI重磅发布的ChatGPT Agent,代表着人工智能从对话助手向自主任务执行者的重大飞跃。这一工具整合了Operator和Deep Research功能,使其能够通过虚拟浏览器、终端和API完成复杂任务,从而显著提升用户效率。
ChatGPT Agent具备自主浏览、点击、填写表单以及执行代码的能力,可以处理各种各样的任务。例如,它可以帮助用户挑选婚礼服装,或者制定详细的旅行行程。更为重要的是,ChatGPT Agent在多项基准测试中表现优异,准确率远超竞争对手,展现出强大的实用性。
OpenAI在安全性方面也下足了功夫。对于涉及高后果操作的任务,ChatGPT Agent需要获得用户的授权才能执行,并且实施了严格的防护措施以防止恶意攻击。这种安全至上的设计理念,为AI的广泛应用奠定了坚实的基础。
Suno v4.5+:人人都是音乐家
Suno v4.5+的发布,为音乐创作带来了革命性的变革。其推出的人声替换、伴奏生成和灵感激发功能,显著提升了音乐创作的灵活性和个性化体验。同时,音质和创作体验也得到了全面优化,为音乐创作者提供了更强大的工具。
人声替换功能允许用户上传伴奏或使用内置乐器伴奏,并输入歌词即可生成完整的歌曲。Add Instrumentals功能可以将用户的歌声或哼唱转化为完整的音乐作品。而Inspire功能则可以从播放列表中汲取灵感,快速生成符合用户审美的新歌曲。这些创新功能的加入,让音乐创作变得更加简单、有趣,让每个人都有机会成为音乐家。
Google Veo3:AI视频制作的新高度
谷歌的旗舰级视频生成模型Veo3已通过Gemini API向开发者开放,提供文本转视频功能并支持同步音频生成。这标志着AI视频制作进入了一个新的阶段。Veo3是首款能够通过单个文本提示生成高分辨率视频并同步生成对话、音乐和音效的模型。
尽管Veo3的价格相对较高,但其强大的功能和出色的性能使其在专业领域具有广泛的应用前景。例如,Cartwheel和游戏工作室Volley等公司已经开始在其项目中应用Veo3。
MirageLSD:实时视频转换的无限可能
MirageLSD作为全球首个人工智能直播流扩散模型,凭借其超低延迟和实时视频转换能力,为直播、游戏开发、动画制作等场景带来了革命性的变化。该技术突破了传统视频生成模型的时延和长度限制,同时具备简单交互和高度灵活性,展现出巨大的应用潜力。
MirageLSD实现了24帧/秒的运行速度和小于40毫秒的响应延迟,打破了传统视频生成模型的瓶颈。它还支持手势控制和连续提示编辑,用户可以实时改变视频中的外观、场景或服装,从而降低了技术门槛。在游戏开发领域,MirageLSD展现出了惊人的潜力,开发者可以在30分钟内快速构建一款游戏,并由模型自动处理所有图形效果。
Traycer:VSCode的AI编程利器
Traycer是一款专为Visual Studio Code设计的AI编程助手工具,通过智能任务拆解、代码规划与实时分析能力,显著提升了开发者的编码效率。其多代理协作和与VSCode Agent模式的高度兼容性,使其在处理复杂项目时表现尤为出色。
Traycer能够根据高级任务描述生成详细的编码计划,支持多个AI代理异步执行任务,从而提升复杂项目的处理效率。它还能持续跟踪代码库,识别潜在错误并提出优化建议。这些功能的加入,让Traycer成为开发者不可或缺的AI助手。
ART框架:一键训练AI Agent
ART框架的发布及其在强化学习领域的应用价值,为开发者提供了便捷的工具,支持多种语言模型,并适用于多场景任务,如邮件检索和游戏开发。其模块化设计和易用性使得中小型团队和个人开发者也能快速构建高性能Agent。
ART框架通过集成GRPO技术,提升AI Agent性能,使其能从经验中学习并优化任务执行。该框架支持多种语言模型,如Qwen2.5、Qwen3、Llama和Kimi,提供广泛的选择。开发者可以轻松集成ART,通过简单命令实现强化学习功能,降低使用门槛。
NVIDIA Canary-Qwen-2.5B:语音识别的新标杆
NVIDIA推出的Canary-Qwen-2.5B模型在自动语音识别和语言处理领域实现了重大突破,以5.63%的词错率登顶Hugging Face OpenASR排行榜。该模型结合了高效的转录与语言理解能力,支持直接从音频执行摘要和问答等任务,具有广泛的商业应用潜力。
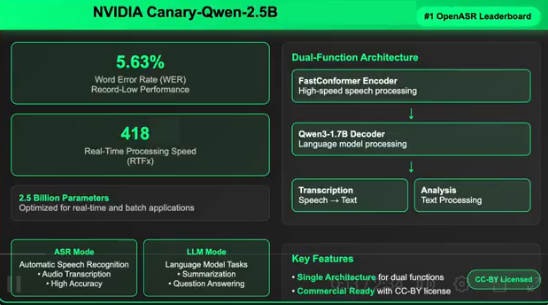
Canary-Qwen-2.5B模型的技术突破在于统一了语音理解与语言处理,实现了单一模型架构。其性能卓越,实时处理速度达418倍,参数仅25亿。该模型适用于企业转录、知识提取、会议总结及合规文档处理等场景。
Mistral AI Le Chat:追赶ChatGPT的步伐
Mistral AI的Le Chat新功能包括深度研究模式、语音交互和高级图像编辑,旨在提升用户体验并挑战OpenAI的ChatGPT。其语音识别基于Voxtral模型,具备自然、低延迟的特性,而图像编辑功能在实际使用中表现出色。
Le Chat的深度研究模式可以快速生成结构化研究报告,帮助用户追踪市场趋势和撰写商业策略书。语音交互功能基于Voxtral模型实现自然、低延迟的语音识别,便于用户随时随地获取信息。高级图像编辑功能则可以通过简单提示创建和编辑图像,表现优于OpenAI的产品。
百度小度MCP Server:AI与物理世界的桥梁
百度小度上线首个支持与物理世界交互的MCP Server,为AI应用开发带来全新变革,引领行业迈向“万物智能互联”新时代。
小度MCP Server实现了终端设备与核心IoT能力的MCP化升级。小度开放平台推出两大核心服务,降低开发者门槛,提升智能设备操控效率。小度MCP Server推动智能家居从“单点控制”向“主动服务”进化,开启“全民智能开发”新纪元。
Lightricks LTXV:图像到视频生成的突破
Lightricks推出的LTXV模型实现了从图像生成长达60秒高质量视频的突破,采用自回归流式架构和多尺度渲染技术,支持实时控制与创作灵活性,并在消费级GPU上高效运行。
LTXV支持生成最长60秒的高质量AI视频,打破行业常规限制。它还引入了动态场景控制功能,允许用户实时调整视频内容细节。LTXV高效运行于消费级GPU,显著降低计算成本,适合广泛创作者使用。
LTX-Video13B:开源AI创作的无限可能
LTX-Video13B凭借多尺度渲染技术、高效生成速度和开源特性,为创作者提供了强大的视频生成工具,显著提升了视频的连贯性和细节表现。

LTX-Video13B的多尺度渲染技术提升了生成速度与画质,支持消费级GPU运行。它支持多种视频生成模式,提供精准控制与创意灵活性。LTX-Video13B的开源模型赋能开发者,降低使用门槛并推动AI民主化。
总结
从Kimi Playground到LTX-Video13B,AI技术的每一次进步都为我们带来了新的惊喜。这些创新不仅提升了效率、降低了成本,更开启了无限的创作可能性。随着AI技术的不断发展,我们有理由相信,未来的世界将会更加智能、便捷和精彩。

