
在人工智能领域,每天都有新的突破和创新涌现。今天的AI日报聚焦于几个引人注目的进展,涵盖了从同声传译到多模态搜索,再到AI设计和语音合成等多个领域。这些技术不仅预示着AI能力的增强,也为开发者和用户带来了前所未有的机遇。
Seed LiveInterpret 2.0:同声传译的飞跃
字节跳动Seed团队最新推出的Seed LiveInterpret 2.0模型,无疑是同声传译领域的一项重大突破。该模型在中英同传翻译质量上达到了业界顶尖水平,更令人印象深刻的是其低延迟和实时声音复刻功能。这意味着跨语言交流不再是冰冷的机器翻译,而是更接近真人同传的自然和流畅体验。

传统的同声传译往往受限于延迟和翻译质量,使得跨语言沟通显得生硬。Seed LiveInterpret 2.0通过端到端的模型设计,实现了接近真人同传的准确率,同时将延迟降低至3秒,极大地提升了用户体验。更重要的是,该模型支持实时声音复刻功能,无需提前采集声音样本即可合成“原声”语音翻译,这无疑为国际会议、在线教育等场景带来了革命性的改变。
在专业评测中,Seed LiveInterpret 2.0在中英互译任务中表现优异,评分远超其他系统,这充分证明了其在技术上的领先地位。这项技术的突破,将进一步推动全球化交流的便利性和效率。
秘塔搜索API:多模态搜索的新选择
秘塔AI搜索正式推出的搜索API,为开发者提供了一个替代Bing Search API的新选择。该API定价0.03元/查询,支持多模态搜索,并且无使用门槛,便于快速接入。在信息爆炸的时代,搜索技术的重要性不言而喻。传统的文本搜索已经无法满足用户对信息获取的需求,多模态搜索成为了新的趋势。
秘塔搜索API的上线,为开发者提供了一个低成本、高效便捷的多模态搜索解决方案。0.03元/查询的定价极具竞争力,降低了开发者的使用门槛。更重要的是,该API支持多模态搜索,可以处理图像、音频、视频等多种类型的数据,从而为用户提供更全面、更精准的搜索结果。开发者无需复杂的申请流程,即可快速接入该API,提升应用的功能和用户体验。
Lovart AI正式版:AI设计重塑创作体验
Lovart AI正式版的全球发布,标志着人工智能在设计领域的应用进入了一个新的阶段。作为首个人工智能设计Agent,Lovart AI通过自然语言交互和全链路设计能力,重新定义了设计行业标准。传统的设计流程往往需要设计师具备专业技能和丰富的经验,而Lovart AI的出现,让设计变得更加简单、高效和智能化。

Lovart AI通过自然语言交互,用户只需简单描述设计需求,即可生成高质量的视觉资产。新功能ChatCanvas支持多轮对话和实时调整布局、配色等,进一步提升了创作效率。针对中国市场优化的“星流Agent”支持中文语义和国风审美,助力本土创作者高效创作。Lovart AI的发布,不仅降低了设计门槛,也为设计师提供了更强大的创作工具,推动了设计行业的创新和发展。
Higgs Audio v2:语音合成的新纪元
李沐团队推出的Higgs Audio v2是语音合成领域的一次重大突破,具备多语言对话生成、韵律自动调整和声音克隆等功能。语音合成技术在近年来取得了显著进展,但仍然存在一些挑战,例如语音的自然度和情感表达。

Higgs Audio v2通过融合1000万小时的语音数据进行训练,在多项测试中表现出色,成为行业标杆。该模型支持多语言对话生成与声音克隆,可以实现复杂任务。在EmergentTTS-Eval测试中,Higgs Audio v2在情绪和问题类别中表现优异,表明其在语音情感表达方面取得了显著进展。Higgs Audio v2支持实时语音聊天和音频内容创作,适用于虚拟主播和语音助手等场景,为用户带来了更丰富、更自然的语音交互体验。
Sora2:OpenAI重夺AI视频C位
OpenAI正在开发其文本到视频模型Sora的继任者Sora2,这表明生成式AI视频领域的竞争将更加激烈。随着技术的不断发展,AI生成视频的质量和效率也在不断提高。Sora作为OpenAI的明星产品,一直备受关注。

OpenAI积极开发Sora2,以应对谷歌Veo3的竞争,显示出其在该领域的雄心。虽然Sora2尚未公开发布,但未来几周内可能有更多消息。谷歌Veo3已向大学生免费开放,并可通过Google Cloud体验,这表明生成式AI视频技术正在加速普及。Sora2的推出,有望进一步提升AI生成视频的质量和创造力,为用户带来更震撼的视觉体验。
OpenAI与Oracle:Stargate项目扩展
OpenAI与Oracle达成新协议,将Stargate项目在美国的数据中心容量扩大至4.5吉瓦,整体容量超过5吉瓦。这标志着OpenAI在2029年前实现10吉瓦目标的重要一步。大规模的AI模型需要强大的计算能力支持,而数据中心是提供计算能力的关键基础设施。
Stargate项目容量扩大至超过5吉瓦,目标是到2029年实现10吉瓦,这表明OpenAI对未来AI发展的信心和投入。OpenAI与Oracle等多家科技公司联合推动项目,预计将创造超10万个工作岗位,为当地经济发展做出贡献。该项目获得了超过190亿美元的资金支持,吸引了多国投资者参与,显示出其在全球范围内的影响力。
Google Photos:AI功能提升创作
Google Photos推出了多项基于AI的新功能,包括将静态照片转化为动态视频以及将照片转换为不同艺术风格的创意工具。这些功能旨在提升用户的创作体验,并通过实验性方式不断优化产品。随着智能手机的普及,人们拍摄的照片越来越多,如何更好地管理和利用这些照片成为了一个重要问题。

照片转视频功能利用Veo2模型,让用户轻松将静态照片变成6秒动态视频,为照片赋予了新的生命力。Remix功能由Imagen AI驱动,可将普通照片转换成动漫、漫画等艺术风格,让用户可以轻松创作出个性化的作品。Google在Photos应用中新增了‘创建’标签页,整合多种创意工具,提供一站式创作体验,进一步提升了用户的创作效率。
YouTube Shorts:AI特效助力短视频
YouTube宣布为Shorts创作者开放一系列革命性的生成式AI功能,包括图片转视频和AI特效。这些工具能够将静态照片转化为动态视频,并提供多种创意选项,显著降低了创作门槛,同时提升了内容的吸引力。短视频已经成为人们分享生活、表达创意的重要方式,而创作高质量的短视频往往需要一定的技能和时间。
图片转视频功能让静态照片在6秒内获得生命力,提升短视频创作效率。AI特效可将涂鸦、自拍等简单素材转化为精美艺术作品,激发创作者灵感。新一代Veo3视频生成器将同步生成音频,提供更完整的创作解决方案,为用户带来更便捷、更高效的创作体验。
Aeneas模型:解读古代文本的新路径
谷歌推出的Aeneas模型为古代铭文的解读提供了全新的方法,通过人工智能技术加速了历史学家对铭文的恢复、鉴定和年代定位工作,同时还能扩展到其他古代语言和材料,极大地提升了历史研究的效率和深度。

Aeneas模型由谷歌DeepMind推出,旨在帮助历史学家理解古代文本。该模型能够分析古代文本的相似性,填补文本空白,减轻历史研究者的负担。Aeneas将文本转化为 “历史指纹”,帮助历史学家在更广泛的背景下解读铭文,为历史研究带来了新的视角和方法。
GitHub Spark:AI开发新时代
GitHub Spark通过自然语言处理技术,让开发者和非开发者都能快速构建个性化Web应用,显著降低了编程门槛,并为微应用开发提供了全新可能。传统的Web应用开发需要专业的编程知识和技能,这使得很多人无法参与到Web应用的开发中来。
GitHub Spark允许用户通过自然语言描述需求,快速生成完整的Web应用,降低了编程门槛。该平台提供全托管运行环境,支持一键部署和PWA适配,简化了开发流程。GitHub Spark支持多模型选择,与GitHub生态深度整合,提升开发效率,为用户带来了更便捷、更高效的开发体验。
华为M-Pencil Pro:手写笔新体验
华为发布了全新一代手写笔HUAWEI M-Pencil Pro,定价699元,具备16384级压感、侧旋功能和多种笔尖选择,同时支持AI功能快捷入口和星闪精确查找功能,为创作者带来更便捷和真实的创作体验。
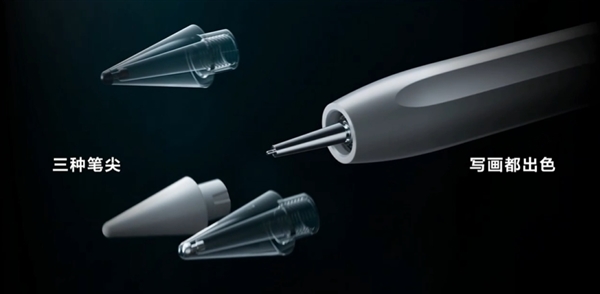
HUAWEI M-Pencil Pro拥有16384级压感,精准感应力度变化,提升创作真实感。笔尾智慧键采用鸿蒙星环设计的呼吸灯,可一键唤起小艺智能助手,提升操作便捷性。星闪精确查找功能支持50米范围内的精确定位,解决手写笔丢失问题,为用户带来了更便捷、更舒适的使用体验。
总而言之,今天AI领域的进展涵盖了多个方面,从同声传译到多模态搜索,再到AI设计和语音合成等。这些技术不仅提升了AI的能力,也为开发者和用户带来了更多的可能性。随着AI技术的不断发展,我们有理由期待未来AI将为我们带来更多的惊喜。

