
在全球人工智能领域,阿里巴巴最新推出的Qwen3-235B-A22B-Thinking-2507模型无疑是一颗耀眼的新星。这款模型以其卓越的推理能力和开源特性,迅速吸引了业界的广泛关注。它不仅代表了当前开源推理模型的顶尖水平,更预示着人工智能技术在未来发展中的巨大潜力。本文将深入剖析Qwen3-235B-A22B-Thinking-2507的技术原理、功能特性、应用场景以及其对整个AI领域的影响。
Qwen3-235B-A22B-Thinking-2507被誉为全球最强的开源推理模型,其强大的性能得益于其独特的技术架构。该模型基于2350亿参数的稀疏混合专家(MoE)架构,每次激活220亿参数。这种架构设计使得模型在保证计算效率的同时,具备了处理复杂任务的能力。模型内部包含94层Transformer网络和128个专家节点,这些复杂的结构共同支撑起了模型强大的推理能力。值得一提的是,Qwen3-235B-A22B-Thinking-2507原生支持256K上下文处理能力,这使得它在处理长文本和深度推理链时具有显著优势。在实际应用中,这意味着模型可以更好地理解上下文信息,从而做出更准确的判断和预测。
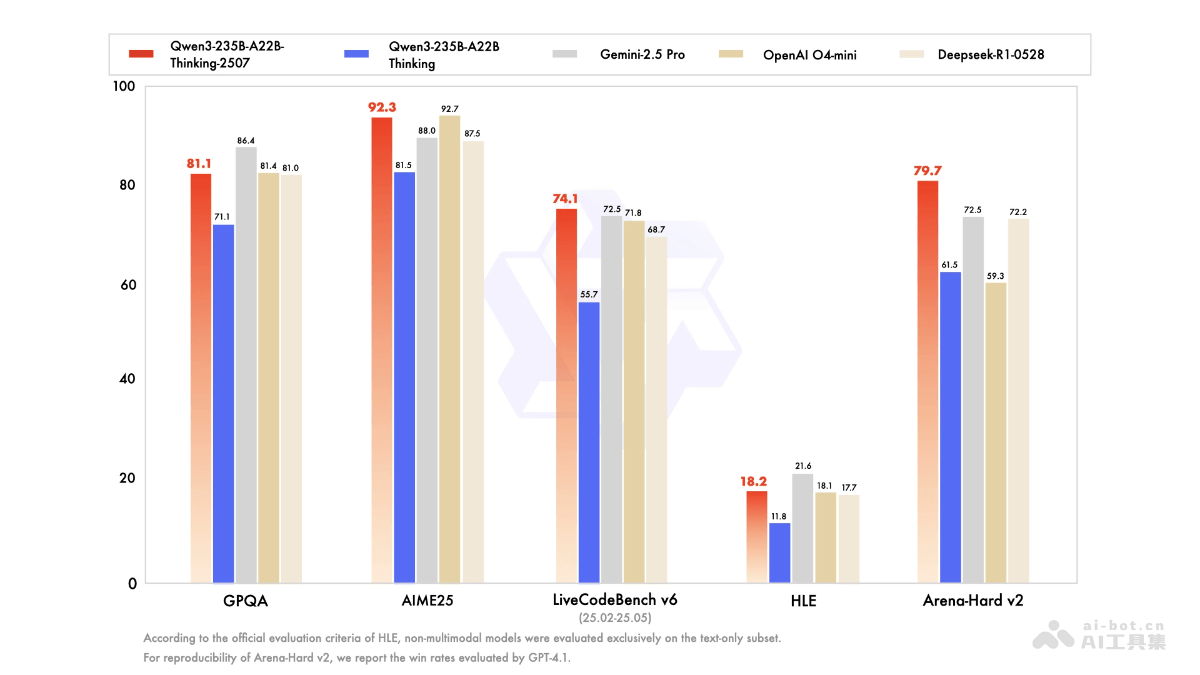
Qwen3-235B-A22B-Thinking-2507在多个基准测试中都取得了令人瞩目的成绩。例如,在AIME25(数学)和LiveCodeBench v6(编程)等基准测试中,该模型刷新了全球开源模型的最佳成绩,甚至超越了一些闭源模型。这些成绩充分证明了Qwen3-235B-A22B-Thinking-2507在逻辑推理、数学、科学分析、编程等核心能力上的卓越表现。除此之外,该模型在知识、创意写作、多语言能力等通用任务上也表现出色,展现了其广泛的应用潜力。更重要的是,Qwen3-235B-A22B-Thinking-2507采用Apache 2.0开源协议,允许免费商用,这无疑将极大地促进其在各个领域的应用和发展。用户可以通过QwenChat、魔搭社区或Hugging Face等平台体验和下载该模型,并根据自身需求进行定制和优化。
Qwen3-235B-A22B-Thinking-2507的功能十分全面,几乎覆盖了人工智能领域的核心应用方向。其在逻辑推理方面的能力尤为突出,能够处理复杂的多步推理问题。这意味着在需要进行深度分析和决策的场景中,Qwen3-235B-A22B-Thinking-2507可以为用户提供强大的支持。在数学运算方面,该模型在AIME25等高难度数学测试中表现出色,展现了其卓越的数学能力。这使得Qwen3-235B-A22B-Thinking-2507在科学研究、工程计算等领域具有广泛的应用前景。此外,该模型还能处理复杂的科学问题,提供准确的分析和解答,为科研人员提供了有力的工具。
在代码生成和优化方面,Qwen3-235B-A22B-Thinking-2507同样表现出色。它不仅能生成高质量的代码,支持多种编程语言,还能帮助开发者优化现有代码,提高代码效率。此外,该模型还提供代码调试建议,帮助开发者快速定位和解决问题。这使得Qwen3-235B-A22B-Thinking-2507成为开发者的得力助手,可以显著提高开发效率和代码质量。值得一提的是,Qwen3-235B-A22B-Thinking-2507原生支持256K的长文本处理能力,能处理超长上下文,适用于复杂的文档分析和长篇对话。这一特性使得该模型在处理法律文件、金融报告等长文本时具有显著优势。
Qwen3-235B-A22B-Thinking-2507还具备深度推理链的能力,可以自动启用多步推理,无需用户手动切换模式,适合需要深度分析的任务。这一特性使得该模型在处理复杂问题时更加高效和便捷。此外,该模型还支持多种语言的对话和文本生成,能满足跨语言交流的需求。这意味着Qwen3-235B-A22B-Thinking-2507可以在国际交流、跨境电商等领域发挥重要作用。不仅如此,Qwen3-235B-A22B-Thinking-2507还能准确理解和执行用户的指令,生成高质量的文本输出,这使得它在人机交互方面具有良好的表现。最后,该模型还支持与外部工具结合使用,扩展模型的功能,为用户提供了更大的灵活性和可定制性。
Qwen3-235B-A22B-Thinking-2507的技术原理是其强大性能的基石。其采用的稀疏混合专家(MoE)架构是关键所在。该架构总参数量为2350亿,但每次推理仅激活220亿参数,包含128个专家节点,每个token动态激活8个专家,从而在计算效率与模型能力之间实现了平衡。MoE架构允许模型根据不同的任务动态选择不同的专家节点,从而更好地适应不同的应用场景。此外,Qwen3-235B-A22B-Thinking-2507基于自回归Transformer结构,拥有94层Transformer层,支持超长序列建模,原生支持256K上下文长度。这使得模型能够处理复杂的长文本任务,更好地理解上下文信息。
Qwen3-235B-A22B-Thinking-2507专为深度推理场景设计,默认强制进入推理模式。这意味着模型在逻辑推理、数学运算、科学分析、编程及学术测评等需要专业知识的领域表现出色。为了进一步提升性能,该模型采用了预训练与后训练双阶段范式。通过大量的预训练数据,模型可以学习到丰富的知识和语言模式;而通过后训练,模型可以更好地适应特定任务,提高性能。在多项基准测试中,如AIME25(数学)、LiveCodeBench(编程)等,Qwen3-235B-A22B-Thinking-2507刷新了全球开源模型的最佳成绩,充分证明了其卓越的性能。MoE架构中的动态激活机制允许模型在推理过程中根据任务复杂性动态选择专家节点,从而更好地适应不同的任务需求。
Qwen3-235B-A22B-Thinking-2507在各个领域都具有广泛的应用前景。在代码生成与优化方面,该模型能生成高质量的代码,帮助开发者优化现有代码,提高开发效率和代码质量。在创意写作方面,Qwen3-235B-A22B-Thinking-2507在创意写作、故事创作、文案撰写等方面表现出色,能提供丰富的创意和详细的构思,为写作者提供有力的支持。在学术写作方面,该模型能辅助撰写学术论文、文献综述等,提供专业的分析和建议,提高学术写作的效率和质量。此外,Qwen3-235B-A22B-Thinking-2507还能帮助设计研究方案,提供科学合理的建议,为科研人员提供有力的支持。
Qwen3-235B-A22B-Thinking-2507的发布,无疑将对人工智能领域产生深远的影响。首先,该模型的开源特性将极大地促进其在各个领域的应用和发展。开发者可以基于Qwen3-235B-A22B-Thinking-2507进行二次开发,构建各种定制化的应用,从而推动人工智能技术的普及。其次,Qwen3-235B-A22B-Thinking-2507的卓越性能将激发更多研究者对人工智能技术的探索和创新。该模型的成功经验将为未来的模型设计和训练提供有益的借鉴。此外,Qwen3-235B-A22B-Thinking-2507的广泛应用将推动人工智能技术在各个行业的渗透,从而提高生产效率和生活质量。例如,在金融领域,该模型可以用于风险评估、欺诈检测等;在医疗领域,该模型可以用于疾病诊断、药物研发等;在教育领域,该模型可以用于智能辅导、个性化学习等。总之,Qwen3-235B-A22B-Thinking-2507的发布是人工智能领域的一个重要里程碑,它将推动人工智能技术走向更加广阔的未来。
当然,我们也应该看到,Qwen3-235B-A22B-Thinking-2507仍然存在一些局限性。例如,该模型的参数量巨大,对计算资源的要求较高,这可能会限制其在一些资源受限的场景中的应用。此外,该模型在处理一些特定领域的任务时,可能需要进行进一步的优化和调整。因此,未来的研究方向可以包括如何降低模型的计算复杂度、提高模型的泛化能力以及增强模型的可解释性等方面。总的来说,Qwen3-235B-A22B-Thinking-2507是一款具有重要意义的人工智能模型,它的发布将为人工智能领域的发展注入新的活力。我们有理由相信,在未来的发展中,Qwen3-235B-A22B-Thinking-2507将发挥更加重要的作用,为人类社会带来更多的福祉。

