
在科技日新月异的今天,人工智能(AI)正以前所未有的速度渗透到我们生活的方方面面。从软件开发到医疗健康,再到内容创作,AI的身影无处不在。本文将聚焦于近期AI领域的几大热点新闻,深入探讨这些技术突破可能带来的影响和变革。
谷歌Gemini 2.5 Flash-Lite稳定版:速度与成本的完美结合
谷歌最新发布的Gemini 2.5 Flash-Lite稳定版,无疑是AI领域的一颗耀眼新星。这款模型以其卓越的速度和经济性,在众多AI模型中脱颖而出。更令人印象深刻的是,它支持高达100万token的上下文处理能力,这为处理复杂任务提供了强大的支持。Gemini 2.5 Flash-Lite不仅在性能上超越了前代版本,还在定价策略上极具竞争力,每百万输入token仅需0.10美元,输出为0.40美元,音频输入价格更是降低了40%。
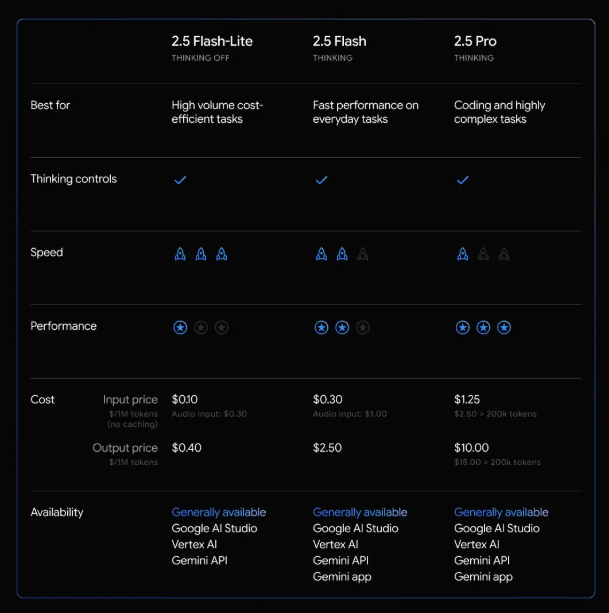
对于开发者而言,Gemini 2.5 Flash-Lite的推出无疑是一个福音。他们可以通过指定模型名gemini-2.5-flash-lite来使用这个新版本,从而享受到更快的速度和更低的成本。然而,需要注意的是,原有的预览版别名将于8月25日移除,开发者需要及时更新。
腾讯混元ASR语音识别大模型:赋能高效语音输入
在语音识别领域,腾讯混元自主研发的ASR语音识别大模型也取得了显著进展。该模型已接入ima平台,为用户提供更高效的语音输入体验。腾讯混元ASR大模型具备强大的语义理解能力,尤其是在中英文混杂的场景中,表现尤为出色。它还支持多种应用场景,如知识库问答和笔记创作,极大地提升了用户的工作效率。
腾讯混元ASR大模型采用了基于双编码器的流式ASR架构,这使得它在语义理解方面有了质的飞跃。此外,该模型还支持多语言及方言识别,未来还将持续优化,以满足用户多样化的需求。可以预见,随着技术的不断进步,语音输入将成为人们日常生活中越来越重要的一部分。
通义千问Qwen3-Coder:开启AI编程新篇章
阿里云开源的最新AI编程大模型Qwen3-Coder,无疑为智能编程技术带来了新的突破。这款模型在代码生成和Agent能力上均达到了顶尖水平,为开发者提供了强大的工具。Qwen3-Coder拥有强大的MoE架构和长上下文处理能力,适用于大规模代码库和动态数据处理。
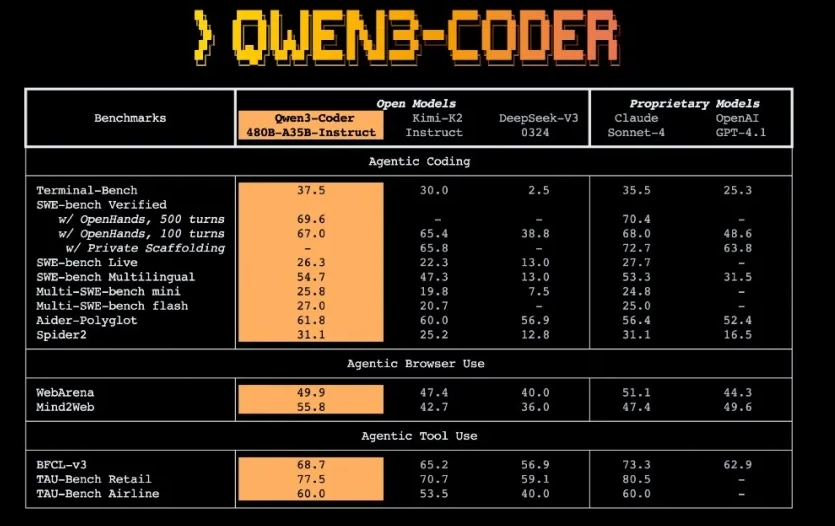
Qwen3-Coder采用了先进的MoE架构,参数量高达480B,支持256K上下文长度。在预训练阶段,它通过多维度扩展策略提升代码能力,7.5T的训练数据中,70%为代码。此外,阿里云还开源了Qwen Code增强解析器和工具支持,进一步提升了开发者的使用体验。Qwen3-Coder的开源,将极大地促进AI编程技术的发展,为开发者带来更多的可能性。
360智能眼镜和AI录音笔:周鸿祎的AI新布局
360公司董事长周鸿祎透露,公司即将推出AI录音笔和智能眼镜。AI录音笔能够智能分析场景并总结要点,而智能眼镜则需要显示功能,以创造新的应用场景,如提词器和翻译工具,从而提升沟通效率。周鸿祎的这一举动,无疑是360在AI领域的一次重要布局。
AI录音笔具备智能分析不同场景的能力,能够精准总结要点,这对于记者、律师等需要记录大量信息的职业人士来说,无疑是一个福音。而智能眼镜配备显示功能后,可以充当提词器和翻译工具,极大地提升沟通效率。可以预见,随着AI技术的不断发展,智能硬件将会在我们的生活中扮演越来越重要的角色。
夸克健康大模型:首个通过主任医师评测的AI模型
夸克健康大模型成功通过主任医师笔试评测,这充分展现了其在医学领域的强大推理能力。该模型已集成至AI搜索中,为用户提供更专业的医疗健康信息。夸克健康大模型通过构建“慢思考能力”和高质量数据训练体系,提升了复杂医疗问题的处理能力。同时,它还拥有专业医师团队的支持,确保了模型输出的专业性和准确性。
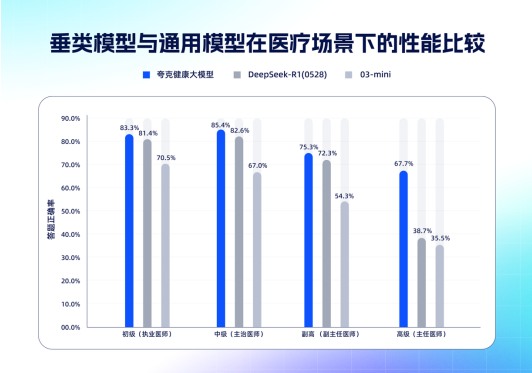
夸克健康大模型通过主任医师笔试评测,这无疑是对其专业性的最好认可。它通过构建“慢思考能力”,提升了复杂医疗问题的分阶段推导能力。此外,夸克还拥有千人规模的专业医师标注团队,确保模型输出内容的专业性。夸克健康大模型的推出,将为用户提供更可靠、更专业的医疗健康信息,助力人们更好地管理自己的健康。
Hedra Live Avatars:开启人机交互新纪元
Hedra Live Avatars的推出,标志着AI视频生成技术的重大突破。它以超低成本、超低延迟和高度灵活性为核心优势,为内容创作、教育、客户服务和游戏等领域带来了全新的可能性。Hedra Live Avatars每分钟仅需0.05美元,大幅降低了高质量视频AI代理的准入门槛。同时,它还拥有低于100毫秒的响应时间,确保实时交互的流畅性和沉浸感。此外,Hedra Live Avatars还兼容主流大语言模型和文本转语音技术,支持个性化交互体验。
Hedra Live Avatars的推出,无疑将极大地推动人机交互技术的发展。它以超低成本、超低延迟和高度灵活性为核心优势,为各行各业带来了全新的可能性。可以预见,随着技术的不断进步,AI视频生成技术将会在我们的生活中扮演越来越重要的角色。
谷歌Gemini2.5:革新图像处理方式
谷歌推出的Gemini2.5 AI模型,其创新功能“对话式图像分割”,能够通过自然语言提示分析和突出显示图像内容。这项技术超越了传统的图像分割技术,支持关系查询、基于逻辑的指令以及抽象概念的理解。Gemini2.5在图像编辑、工作场所安全和保险行业等领域有着广泛的应用前景,并为开发者提供了便捷的API接口。

Gemini2.5能够理解并响应更复杂、更具语义的自然语言指令,这使得图像处理变得更加智能化。它还支持多语言提示,并可提供其他语言的物体标签。开发者可以通过Gemini API直接访问该功能,并获得JSON格式的结果。
Meta AU-Nets:革新文本处理方式
Meta推出的AU-Net模型,通过自回归的U-Net结构,实现了对文本的灵活处理。它能够从原始字节开始学习,并动态组合成多层次的序列表示,为大语言模型的发展提供了新的思路。AU-Net架构通过自回归方式,动态组合字节形成多层次的序列表示。它采用收缩和扩张路径,确保宏观语义信息和局部细节的有效融合。自回归生成机制提高了推理效率,确保文本生成的连贯性与准确性。
苹果AI团队:面临战略调整
苹果AI团队因开源计划受阻引发内部不满,高级副总裁费德里吉认为市场已有足够开源模型,且苹果模型在设备端性能不足。同时,苹果推迟Siri更新并考虑与第三方大模型合作,这凸显了其在AI发展上的战略调整。苹果AI团队开源计划被高层否决,这反映了苹果在AI发展上的保守态度。苹果坚持设备优先策略,这在一定程度上限制了AI技术的发展潜力。未来,苹果或将转向与OpenAI、谷歌等第三方大模型合作,以提升Siri的功能。
Fogsight AI:一键生成教学动画
Fogsight是一款基于大型语言模型的AI动画引擎,能够将抽象概念转化为直观、易懂的动画。它通过输入关键词或短语,自动生成包含双语旁白和电影级视觉效果的动画短片,适用于课堂教学、在线课程和科普内容创作。
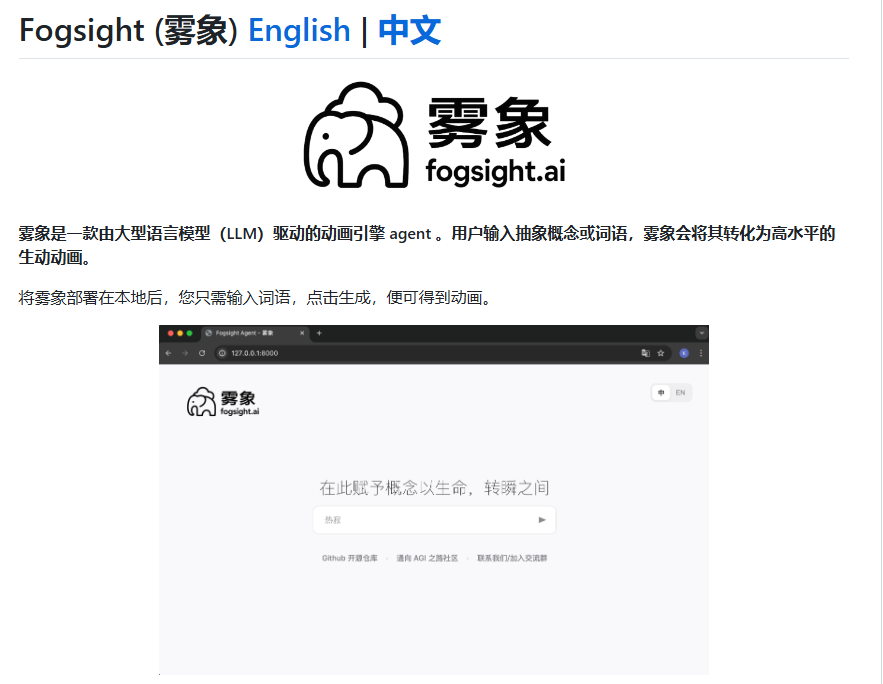
用户只需输入关键词,即可生成30秒至90秒的叙事完整动画。Fogsight动画具备电影级视觉效果,能够有效提升学习兴趣。此外,它还支持多轮对话调整动画内容,满足个性化需求。Fogsight的推出,将极大地改变教育演示的方式,让抽象概念变得更容易理解。

