
AI技术浪潮:深度解析十大前沿进展如何重塑智能未来
当前,人工智能技术正以前所未有的速度向前发展,不断突破边界,渗透到我们生活的方方面面。从多模态内容的智能生成,到电商与汽车领域的深度融合,再到开发者工具的革新,本周的AI领域呈现出百花齐放的态势。这些前沿进展不仅预示着技术潜力的持续释放,更在逐步构建一个更加智能、高效的未来世界。
1. 阿里开源Qwen-Image-Edit:中文图像编辑的新标杆
阿里巴巴通义千问团队重磅推出Qwen-Image-Edit图像编辑模型,其卓越的中文渲染能力和精细化文本编辑控制,在AI图像生成与编辑领域树立了新的行业标准。相较于现有模型,Qwen-Image-Edit在处理中文文本时展现出明显优势,解决了长期困扰多模态AI的中文排版与语义一致性难题。该模型采用双重编码机制,能够精确捕捉图像的语义内容与视觉外观特征,确保在编辑过程中不仅能准确理解用户意图,还能保持图像的整体美学和谐。
其开源策略为全球AI开发者社区注入了新的活力,使得更多研究者和开发者能够基于此进行创新应用。在广告创意、个性化内容制作、数字艺术创作等领域,Qwen-Image-Edit的应用前景广阔,将极大提升中文内容的视觉表现力和编辑效率。

2. 淘宝“AI万能搜”:重塑电商购物体验
淘宝近日启动“AI万能搜”功能灰度测试,旨在利用先进的大模型技术彻底革新用户的电商搜索与购物决策流程。这项创新功能超越了传统关键词搜索的局限,能够通过自然语言理解用户深层次的购物需求,进而提供包括购物攻略、商品口碑评测、个性化送礼清单及优惠信息咨询等多维度服务。它的核心价值在于,将复杂的购物链路简化为直观的对话式交互,让用户能够像与专业导购交流一样获取信息。该功能尤其聚焦于四大核心场景:穿搭指南、送礼清单、选购攻略和问口碑,全面覆盖了消费者在购物过程中面临的主要决策痛点。更值得一提的是,AI万能搜还会透明地展示其思考逻辑,包括如何获取信息、分析需求并最终形成建议,极大地增强了用户对AI推荐的信任感和可解释性。这项技术不仅将提升购物效率,也将促使电商平台更加注重内容与服务的融合,推动整个行业的智能化转型。

3. 小红书DynamicFace:人脸生成技术的新突破
小红书AIGC团队发布了DynamicFace人脸生成技术,标志着在图像和视频人脸融合任务上取得了显著进展。该技术专注于实现高质量与高度一致性的人脸置换效果,同时强调生成过程的可控性。这意味着用户或开发者能够对生成的人脸属性、表情、姿态等进行精确调整,从而满足多样化的创意需求。DynamicFace通过优化底层算法,确保在融合新面孔时,能够自然地融入目标图像或视频的语境,避免常见的合成痕迹。
其应用潜力巨大,不仅在小红书的社交娱乐场景中,如虚拟形象定制、视频换脸特效等,能够为用户带来更丰富的互动体验,在影视制作、虚拟数字人、游戏角色创建等专业领域也具有广阔的应用前景。然而,随着人脸生成技术的日益成熟,如何平衡技术创新与数据安全、伦理责任,将是DynamicFace乃至整个AI生成领域持续面临的重要课题。
4. Gemini API升级:URL Context 开辟内容变现新途径
Google Gemini API的最新升级,引入了URL Context功能,为开发者和内容创作者带来了革命性的变革。该功能允许开发者直接在API请求中嵌入网页链接,模型将自动访问、解析并理解链接中的内容,从而大幅简化了传统的内容获取与处理流程。这一进步使得构建基于实时网页信息、提供深度洞察的AI应用变得更加高效便捷。
更具战略意义的是,URL Context功能为内容提供商开辟了新的商业模式。通过将高质量的网页内容作为AI模型的输入源,并根据内容的tokens消耗进行计费,有望催生出类似AdSense的联盟机制。这意味着内容创作者可能通过其内容的“被AI消费”而获得收益,从而激励更多优质、原创内容的生产。然而,开发者在使用时也需权衡内容的提取成本与实际效益,以确保商业模式的可持续性。
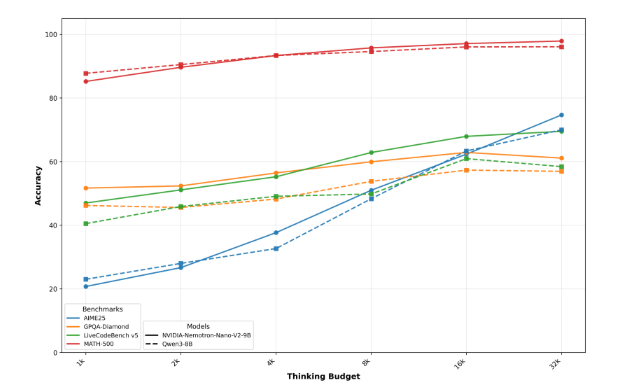
5. Nvidia Nemotron-Nano-9B-v2:小型开放模型的强大表现
英伟达(Nvidia)持续在AI硬件与软件领域发力,最新发布的新型小型语言模型Nemotron-Nano-9B-v2,以其90亿参数量和在多个基准测试中的出色表现,再次证明了其在边缘计算和资源受限环境下的强大潜力。这款模型经过专门优化,能够在单个Nvidia A10 GPU上高效运行,极大地降低了高性能AI模型的部署门槛。Nemotron-Nano-9B-v2不仅支持多语言任务,还能高效生成代码,使其成为开发者工具箱中的一个多功能利器。
其亮点在于支持“智能推理开关”,为用户提供了更大的灵活性,可以根据具体应用场景精确控制模型的推理行为,优化资源利用。作为一款开放模型,Nemotron-Nano-9B-v2允许商业用途和衍生模型的创建,这对于推动AI技术的普及化和加速行业创新具有重要意义。它预示着未来AI模型将更加注重轻量化、高效能与可定制化,以适应更广泛的应用需求。
6. 马斯克Grok Imagine 0.1:构建“宇宙最强想象力放大器”
埃隆·马斯克旗下的xAI公司发布了其图像生成功能Grok Imagine的0.1测试版,并雄心勃勃地宣称其目标是打造“宇宙最强想象力放大器”。Grok Imagine旨在直接挑战DALL-E、Midjourney等主流AI图像生成工具的市场地位,但其核心愿景不仅仅是生成图像,更在于通过AI技术帮助用户拓展创意思维和想象的边界。虽然马斯克公开承认当前版本仍处于早期阶段,仍有诸多改进空间,但这并未影响其对未来发展的坚定信心。
作为一项新兴的图像生成服务,Grok Imagine的出现预示着AI创意工具市场的竞争将更加激烈。其“想象力放大器”的定位,表明xAI试图超越单纯的技术实现,将AI视为人类创造力的延伸和赋能工具。随着版本的迭代,Grok Imagine有望在用户体验、创意自由度以及生成图像质量方面带来新的突破,推动AI辅助艺术创作进入一个全新的发展阶段。

7. Vercel v0 iOS版:AI驱动移动开发新纪元
Vercel近期推出了其AI驱动的开发工具v0的iOS版本,为移动开发者带来了前所未有的构建体验。v0的核心理念是通过自然语言提示,快速生成全栈Web应用的代码,从而显著提升开发效率。其在React和Next.js框架中的卓越表现已广受赞誉,而此次将这一能力扩展到iOS平台,无疑将对移动应用开发领域产生深远影响。
传统的移动应用开发往往涉及复杂的编码和跨平台兼容性挑战,而v0 iOS版的目标正是简化这一过程。开发者只需通过简单的文字描述,即可让AI自动生成代码骨架和组件,大大缩短了从概念到实现的周期。这不仅降低了移动开发的门槛,使得更多非专业人士也能参与到应用构建中来,同时也为专业开发者提供了强大的生产力工具,让他们能够将更多精力投入到核心业务逻辑和用户体验的创新上。Vercel v0 iOS版的发布,标志着AI辅助开发正从Web端向移动端全面延伸,预示着一个更加智能、高效的开发新纪元的到来。

8. 理想汽车MindGPT 3.1:智能体模型赋能车载AI
理想汽车发布了其自研的MindGPT 3.1智能体模型,这是在车载人工智能领域的一次重要跃升。新版本显著增强了AI助手的实时处理和多任务协调能力,使得车载系统能够更智能、更流畅地响应用户的指令和需求。尤其在数学计算和代码编程等复杂任务维度上,MindGPT 3.1的表现全面超越了前代版本,展现了理想汽车在AI大模型技术栈上的深厚实力。
MindGPT 3.1的“边想边搜”功能是其核心亮点之一,它将智能体能力深度融入大模型架构,使得AI助手在处理请求时,不仅能快速给出答案,还能在必要时进行实时信息检索和整合,提供更全面、准确的服务。更令人印象深刻的是,其每秒最高可达200个tokens的输出速度,相较于前代提升了近5倍,极大地优化了用户交互体验。代码能力的增强,例如实现贪吃蛇游戏和弹球控制等经典编程案例,也预示着车载AI未来在娱乐、教育甚至辅助驾驶领域的更多可能性。理想汽车通过MindGPT 3.1的迭代,正在构建一个更加智能、个性化的移动出行生态系统。
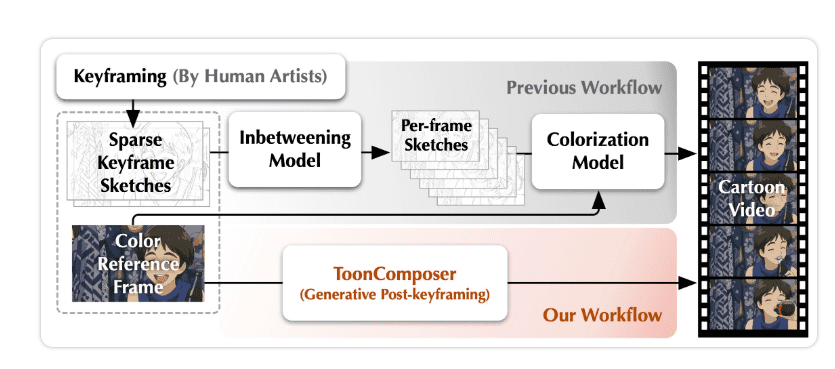
9. ToonComposer:AI技术简化动漫制作流程
ToonComposer是一项基于生成式AI技术的创新工具,旨在彻底改变传统的动漫制作流程。这项技术的核心在于其极高的效率和智能化水平:用户仅需提供一张草图和一帧彩色图像作为输入,ToonComposer就能够自动生成完整的卡通视频。据测算,这项技术可将人工工作时间节省高达70%,极大地解放了动画师的生产力,使其能够将更多精力集中在创意构思而非繁琐的中间环节。
该系统不仅具备自动化生成能力,还提供了精细化的“关键帧控制”和“区域控制”功能。通过关键帧控制,创作者可以设定动画的关键姿态和时间点,确保叙事的连贯性;而区域控制则允许用户在草图上自由标记特定区域,AI会智能地根据指令填充或修改这些区域的细节,从而实现更精准的创作意图。ToonComposer的出现,有望大幅降低动漫制作的门槛和成本,使得独立创作者和小型工作室也能制作出高质量的动画内容,推动动漫产业的多元化发展。
10. ElevenLabs:视频到音乐生成与AI学生包
ElevenLabs作为AI音频领域的领军企业,近期推出了两项重磅更新:全新的视频到音乐生成流程和面向学生的AI学生包。这些举措不仅进一步拓展了其多模态AI能力,也彰显了其赋能内容创作者和教育领域的决心。
“视频到音乐生成流程”是一项创新功能,它能够根据视频内容自动分析其情感基调、节奏变化和叙事结构,进而生成定制化的背景音乐或配乐。这一技术突破极大地简化了视频后期制作中配乐环节的复杂性,使创作者能够更高效地为视频匹配情绪和氛围,提升作品的整体感染力。而“AI学生包”则通过提供免费积分和折扣工具,降低了学生群体接触和使用先进AI音频技术的门槛,旨在培养未来的AI创新人才。ElevenLabs通过这两项更新,不仅巩固了其在AI音频技术领域的领先地位,更通过技术与教育的融合,为AI音频生态的持续升级与普及奠定了坚实基础。
展望:AI驱动的未来格局
纵观本周AI领域的一系列前沿进展,我们不难发现几个核心趋势:首先是多模态AI的深入发展,如Qwen-Image-Edit和DynamicFace在图像与文本、图像与视频融合上的突破;其次是AI在特定行业应用中的垂直化与智能化,如淘宝AI万能搜革新电商、理想汽车MindGPT赋能车载系统;再者是开发者生态的持续繁荣与工具的革新,如Gemini API的URL Context和Vercel v0 iOS版,极大提升了开发效率和内容变现潜力。同时,Nvidia的轻量级模型和ElevenLabs的普惠策略,也显示出AI技术正向着更易用、更普惠的方向发展。
这些创新共同描绘了一个由AI深度驱动的未来图景,技术将不再是冰冷的工具,而是能够理解、协作、甚至激发人类创造力的伙伴。随着这些前沿技术的不断成熟与普及,我们有理由相信,人工智能将在更多领域展现出其颠覆性力量,引领社会迈向一个前所未有的智能新阶段。








