
NVIDIA Nemotron Nano 2:9B级高效推理模型的深度解析与应用展望
近年来,随着人工智能技术的飞速发展,大语言模型(LLMs)在各个领域展现出惊人的潜力。然而,高性能LLMs往往伴随着巨大的计算资源消耗,尤其是在推理阶段,这对边缘设备和资源受限的环境构成了挑战。为解决这一痛点,NVIDIA推出了其最新的高效推理模型——NVIDIA Nemotron Nano 2,一款参数量为9B的创新之作。该模型不仅在推理速度上实现了显著突破,更在多功能性、长上下文处理以及“思考预算”控制方面带来了诸多亮点,预示着AI推理技术迈入了一个新纪元。
混合架构创新:Mamba-Transformer的融合之力
NVIDIA Nemotron Nano 2的核心在于其开创性的混合Mamba-Transformer架构。传统Transformer模型在处理长序列时,自注意力机制的计算复杂度呈平方级增长,限制了其在实际应用中的效率。而Nemotron Nano 2巧妙地用Mamba-2层替代了Transformer中的大部分自注意力层。Mamba架构以其线性时间复杂度和高效的内存利用率而闻名,特别擅长处理长序列并加速生成长推理链。这种“Mamba主导,Transformer补充”的设计策略,使得模型在保持Transformer的灵活性和强大表达能力的同时,显著提升了推理速度和吞吐量。
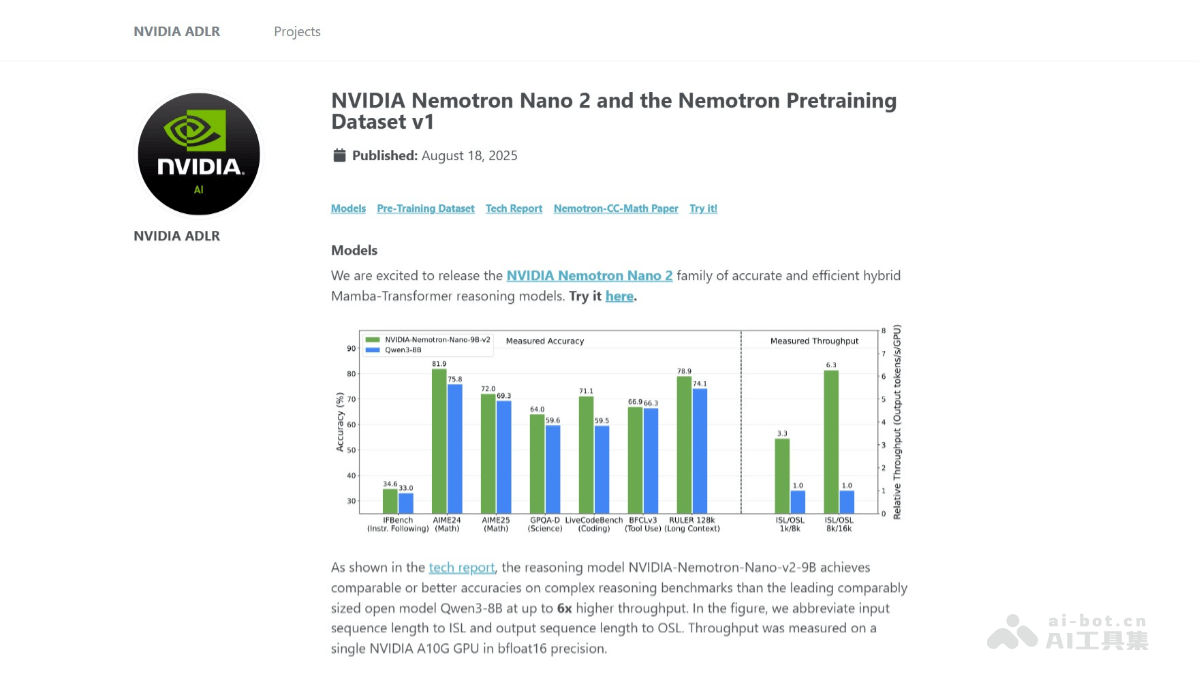
具体而言,Mamba-2层负责处理序列中的局部依赖和长程记忆,而保留的少量Transformer自注意力层则确保模型能够捕捉全局上下文信息,从而在复杂的语言理解和生成任务中保持高准确率。这种混合架构的优势在于,它能在保证模型性能不下降的前提下,实现比同级别模型更高的运行效率。根据NVIDIA的测试数据,Nemotron Nano 2的推理吞吐量相较于Qwen3-8B模型高出多达6倍,且在多项基准测试中保持了相当甚至更优的准确率,这无疑是模型设计上的一大飞跃。
卓越的训练策略与长上下文能力
模型的强大性能并非一蹴而就,NVIDIA Nemotron Nano 2的背后是精心设计的预训练和后训练优化策略。模型在20万亿个token的庞大数据集上进行了预训练,这为模型奠定了扎实的多语言和多领域知识基础。预训练过程中采用了FP8精度和Warmup-Stable-Decay学习率调度,确保了训练的稳定性和效率。更值得一提的是,通过持续预训练的长上下文扩展阶段,Nemotron Nano 2成功实现了对128k上下文长度的全面支持。
这意味着模型能够处理极其冗长和复杂的文本,而不会出现性能下降。例如,在分析长篇文档、代码库或学术论文时,Nemotron Nano 2能够一次性摄入海量信息,进行深入的关联分析和推理,这对于需要全局视角和深度理解的应用场景至关重要。一个NVIDIA A10G GPU即可支持128k上下文长度的推理,这极大地降低了高性能长文本处理的门槛,使得更多开发者和研究者能够利用这一能力。
预训练后的模型通过一系列后训练优化进一步提升其性能和实用性。这包括:
- 监督微调(SFT):针对特定任务的数据集进行微调,显著提升模型在指令遵循、问答、摘要等任务上的表现。
- 策略优化:通过优化学习策略,增强模型的指令遵循能力,使其更好地理解和执行用户指令。
- 偏好对齐:通过人类反馈强化学习(RLHF)等技术,使模型的输出更符合人类的偏好和价值观,提升用户体验。
- 模型压缩:NVIDIA通过先进的剪枝和知识蒸馏技术,将原始的12B参数基础模型高效压缩至9B参数,同时几乎未损失性能。这种压缩使得模型可以在更少的硬件资源上运行,例如在单个NVIDIA A10G GPU上进行128k token的上下文推理,显著降低了部署成本和能耗,这对于边缘AI部署和大规模云端推理都具有重要意义。
“思考预算”:智能推理的全新范式
NVIDIA Nemotron Nano 2引入了名为**“思考预算控制”的创新功能,这标志着AI推理进入了一个更加精细化和用户可控的阶段。在传统的LLM推理过程中,模型会生成一个完整的答案,而其内部的推理过程对用户来说往往是“黑箱”。Nemotron Nano 2的独特之处在于,它能在生成最终答案之前,先生成一个推理过程(reasoning trace)**。用户可以根据自身需求,明确指定模型在生成推理过程上花费多少计算资源,即“思考”的token数量。
这项功能提供了前所未有的灵活性。例如,在需要详细解释和步骤展示的教育场景中,用户可以要求模型生成详细的推理过程,帮助学习者理解解决方案的来龙去脉。而在某些对响应速度有严格要求的场景,或者用户仅需最终结果时,可以选择跳过中间推理步骤,直接获取最终答案,从而缩短响应时间并节省计算资源。这种基于截断训练实现的推理预算控制,使得Nemotron Nano 2成为一个更加智能、高效且用户友好的推理引擎,能够适应多样化的应用需求。
多语言与多领域能力:构建通用智能基石
Nemotron Nano 2的预训练数据集包含了多种语言和来自多个领域的数据,这赋予了模型强大的多语言和多领域推理能力。无论是在处理中文、英文或其他主要语言的文本时,模型都能展现出卓越的理解和生成能力。其涵盖的领域包括数学、代码、学术论文、科学、技术、工程、数学(STEM)等,这使得Nemotron Nano 2能够胜任广泛的应用场景,例如:
- 教育领域:模型能够帮助学生解决复杂的数学和科学问题,通过逐步推理的方式解释复杂的公式和物理定律,显著提升学生的理解和学习效率。对于教师而言,模型可以辅助生成教学案例和习题解析。
- 学术研究:研究人员可以利用Nemotron Nano 2生成详细的推理过程和数据分析报告,辅助论文撰写、实验设计以及文献综述。长上下文支持使得模型能够处理大型数据集和多篇研究论文,进行跨文本的知识整合与发现。
- 软件开发:开发者能够利用模型生成高质量的代码片段、进行代码重构建议、编写测试用例,从而加快开发进度,提高代码质量。在Bug调试时,模型甚至可以辅助分析错误日志,提供潜在的解决方案。
- 编程教育:对于编程初学者,Nemotron Nano 2可以提供清晰的代码示例和详细的解释,帮助他们更好地理解编程语言的语法、算法逻辑和数据结构,降低学习门槛。
- 客户服务:作为高效的多语言聊天机器人,Nemotron Nano 2能够提供准确且快速的客户支持,处理复杂的查询、提供产品信息、解决常见问题,显著提升客户满意度和运营效率。
展望:AI推理的未来图景
NVIDIA Nemotron Nano 2的推出,不仅仅是发布了一款高性能AI模型,更是为整个AI推理生态系统带来了深远的影响。其混合架构的创新、对长上下文的卓越支持、以及独特的“思考预算”功能,共同构建了一个更加高效、灵活且可控的AI推理框架。这款模型降低了部署高性能AI应用的门槛,使得更多开发者能够将其整合到各种产品和服务中,无论是云端大规模部署还是边缘设备的智能升级。
未来,随着Nemotron Nano 2及其后续版本的不断迭代,我们有理由相信,AI模型将变得更加智能、更具适应性。它们将不再是简单的“回答机器”,而是能够像人类一样进行逐步思考、解释决策过程、并根据具体场景调整“思考”深度的智能伙伴。这将极大地推动AI在各个行业中的深度融合与创新应用,从教育辅导到科学发现,从代码生成到智能客服,Nemotron Nano 2的潜力无限,它正在为下一代AI应用奠定坚实的基础。








