
快手Klear-Reasoner:解构高性能AI推理模型的创新路径
近年来,人工智能领域在生成式模型与推理能力上取得了长足进步,其中,对复杂数学逻辑与编程任务的处理能力成为衡量模型智能水平的关键指标。在这一背景下,快手推出的Klear-Reasoner模型,以其卓越的数学和代码推理表现,在开源社区中引发了广泛关注。这款基于Qwen3-8B-Base的推理模型,不仅展示了国内科技企业在基础大模型研发上的深厚实力,更通过一系列前沿训练策略,为我们理解高性能AI推理的构建路径提供了宝贵洞察。Klear-Reasoner的核心创新之处在于其独特的GPPO算法,这一突破性技术有效地解决了传统强化学习方法中探索能力受限和负样本收敛缓慢的痼疾,使其在AIME和LiveCodeBench等权威基准测试中,达到了8B级别模型的领先水平。其训练细节与全流程的公开,无疑为全球研究者复现与进一步发展推理模型奠定了坚实基础。
Klear-Reasoner的核心功能剖析
Klear-Reasoner模型在多个维度展现出其强大的推理能力,这些功能不仅覆盖了当前AI领域的热点,也预示着未来智能应用的发展方向。其主要功能包括:
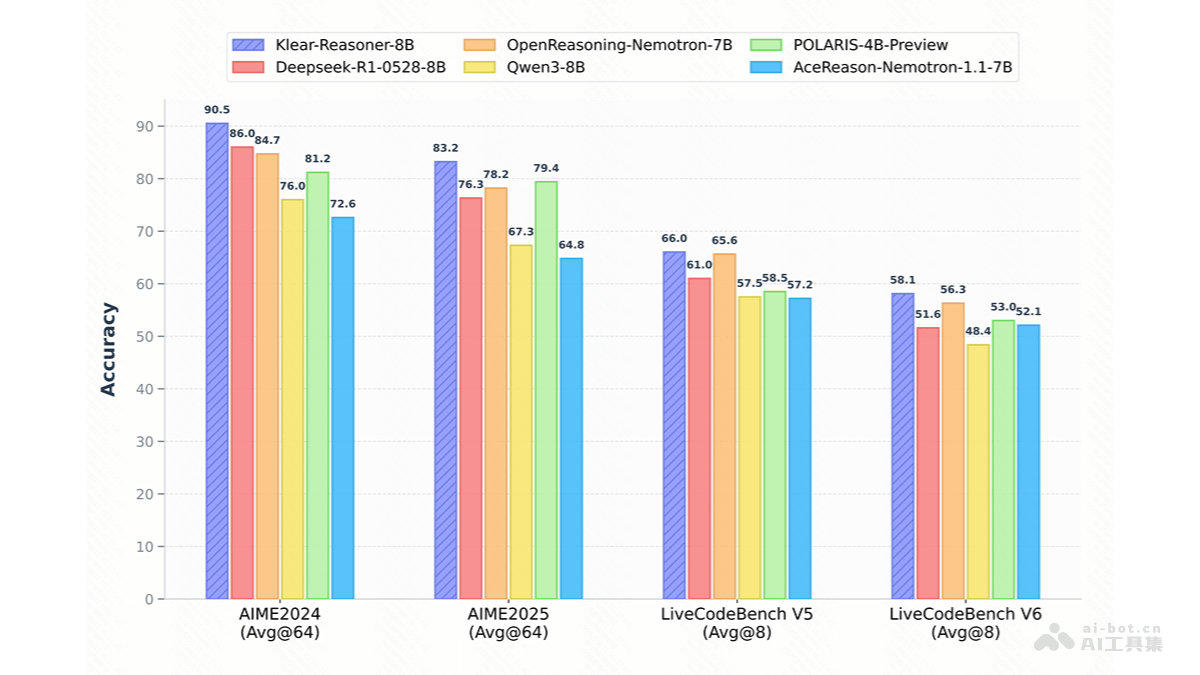
高阶数学推理:模型在处理复杂数学问题上表现出令人惊叹的能力。这不仅仅是简单的数值计算,而是涉及到代数、几何、组合数学等多个分支的高难度数学竞赛题目,要求模型能够理解问题、构建逻辑链条并推导出正确解法。例如,在国际数学奥林匹克竞赛(AIME)级别的题目中,Klear-Reasoner能够展现出超越传统AI工具的分析深度与准确性,这对于提升智能教育系统的辅导质量,甚至辅助科研人员解决特定数学难题都具有重要意义。
高效代码生成与推理:在软件开发领域,Klear-Reasoner能够生成高质量、符合逻辑的代码片段,极大地提升了开发效率。模型通过了LiveCodeBench V5和V6的严格评测,分别达到了66.0%和58.1%的准确率。这意味着它不仅能理解编程需求,还能根据需求生成功能完整、语法正确的代码。更进一步,它还能对现有代码进行推理、分析潜在错误或优化方案,从而在自动化代码审查、错误调试等环节发挥关键作用。
长思维链推理(Long CoT Reasoning):许多现实世界的问题并非一步可解,而是需要多步的逻辑推导和决策。Klear-Reasoner通过长思维链监督微调(long CoT SFT)和强化学习(RL)的结合,显著提升了模型在处理复杂、多步骤推理任务中的表现。这种能力使得模型能够模拟人类的逐步思考过程,拆解大问题为小问题,逐一击破,最终形成完整且正确的解决方案。例如,在复杂的项目管理、科研路径规划中,它能提供结构化的思维辅助。
数据质量优化策略:在模型训练过程中,Kovar-Reasoner对训练数据进行了精细化筛选与管理。它优先选择来自少数高质量的数据源,以确保模型能够学习到准确无误的推理模式,避免了低质量数据可能引入的噪声和偏见。值得注意的是,为了增强模型的探索能力,尤其是在面对高难度任务时,Klear-Reasoner有策略地保留了部分错误样本。这种反直觉的策略有助于模型理解错误的多样性,从而在实际应用中更具鲁棒性和泛化性。
技术深层原理:驱动Klear-Reasoner性能的创新引擎
Klear-Reasoner之所以能在数学和代码推理领域取得突破性进展,离不开其背后精妙的技术设计与优化。
1. 长思维链监督微调(Long CoT SFT):构建高质量推理基石
Klear-Reasoner在训练初期采用了长思维链监督微调技术,这是一种旨在让模型学习如何“思考”的策略。核心在于使用高质量、包含详细推理步骤的数据集来指导模型。不同于传统的问答对,CoT数据会展示问题、解决过程(一步步的推理链)以及最终答案。通过这种方式,模型不仅学会了给出答案,更重要的是学会了如何推导出答案。在Klear-Reasoner的实践中,团队格外强调数据质量,优先选用权威、准确的数据源,如高质量的数学解题集和经过严格测试的代码库。尽管如此,研究发现,完全排除所有错误样本并不总是最佳选择。尤其是在处理极具挑战性的任务时,适度保留少量“错误”样本,可以促使模型在训练过程中进行更广泛的探索,从而提升其对新颖或复杂问题的处理韧性。这如同人类学习中“试错”的重要性,能帮助模型建立更全面的世界观。
2. 强化学习(RL)与软奖励机制:精炼推理策略
在完成CoT SFT阶段后,模型通过强化学习进一步提升其推理能力。强化学习允许模型在与环境的交互中学习最优策略,通过“试错”来最大化奖励。在Klear-Reasoner中,尤其是在代码任务的训练上,引入了软奖励机制。传统的“硬奖励”机制通常是二元的:如果代码完全通过所有测试用例则获得高分,否则为零分。这种机制在复杂任务中容易导致奖励稀疏,即模型很难在早期获得任何正向反馈,从而学习效率低下。软奖励机制则根据测试用例的通过率来给予奖励,例如,如果代码通过了50%的测试用例,就能获得相应的分数。这种更细粒度的奖励信号,显著缓解了奖励稀疏问题,增加了训练信号的密度,并有效降低了梯度估计的方差,使得模型的学习过程更为稳定、高效。此外,在RL阶段,团队还会对数据进行严格筛选,过滤掉那些测试用例本身存在问题的样本,进一步确保训练数据的纯净性与有效性。
3. GPPO(Gradient-Preserving Clipping Policy Optimization)算法:突破探索与收敛的困境
GPPO算法是Klear-Reasoner最具创新性的技术之一,它旨在解决传统策略优化算法(如PPO和GRPO)在处理高熵或负样本时面临的挑战。在PPO和GRPO中,clip操作虽然能够限制策略更新的幅度,防止更新过大导致模型崩溃,但也可能丢弃高熵token(即模型对预测结果不确定性较高的token)的梯度信息。这种信息丢失限制了模型的探索能力,特别是在复杂任务中,模型难以尝试更多样化的解决方案。同时,对于负样本(模型预测错误的情况),clip操作也可能导致其收敛速度缓慢,因为纠正错误的梯度信号被过度限制。
GPPO算法通过引入stop gradient操作,巧妙地将clip操作与梯度反向传播机制解耦。这意味着,对于所有token,其梯度信息都能被完整地保留。具体来说:
- 保留高熵token梯度:对于那些模型不太确定、具有高熵的token,GPPO会保留其完整的梯度,但会通过一个约束机制将其限制在合理的更新范围内。这使得模型在探索新行为或解决不确定性问题时,能够获得更丰富的梯度信号,从而更有效地进行探索。
- 加速负样本收敛:对于模型预测错误的负样本,GPPO同样保留其梯度,并对其施加特定幅度的限制。这确保了纠正错误的信号能够以足够但不过激的强度传递给模型,从而显著加快了错误修正的速度,提高了模型在纠正偏差方面的效率和鲁棒性。
通过GPPO算法,Klear-Reasoner在保持训练稳定性的同时,显著增强了模型的探索能力和对错误样本的修正效率,这对于模型在复杂推理任务中达到卓越性能至关重要。
Klear-Reasoner的多元化应用场景与未来展望
Klear-Reasoner作为一款强大的推理模型,其应用潜力远超传统AI工具,有望在多个行业引发变革。
教育领域:Klear-Reasoner能够充当智能数学家教,为学生提供个性化的解题指导。它不仅能给出最终答案,更能详细展示每一步的推理过程,帮助学生深入理解数学概念和解题技巧。这种交互式、个性化的学习体验,将显著提升学生的学习效率和对数学的兴趣,甚至能辅助教师进行更精准的学情分析和教学设计。
软件开发:在日趋复杂的软件工程中,Klear-Reasoner可以成为开发者的强大助手。它能够根据自然语言描述自动生成高质量的代码片段,加速功能模块的开发。更重要的是,它还能进行智能代码审查,识别潜在的bug、安全漏洞或性能瓶颈,并提供优化建议,从而提高代码的整体质量和开发团队的效率。这种自动化辅助开发模式,将释放开发者从重复性工作中解脱出来,专注于创新。
金融科技:金融行业对数据分析和风险评估有着极高的要求。Klear-Reasoner能够处理海量的金融数据,通过其强大的逻辑推理能力,进行精准的风险评估、市场预测和投资策略分析。例如,它可以辅助分析复杂的交易模式,识别欺诈行为,或者根据经济指标预测市场趋势,为金融机构提供更具洞察力的决策支持,助力其在复杂多变的市场环境中占据先机。
科研与数据分析:在科学研究和数据分析领域,Klear-Reasoner可以处理复杂的科学计算任务和海量实验数据。它能够帮助研究人员构建并验证假设,从数据中提取深层模式和规律,并提供逻辑推理和模型解释,加速科学发现的进程。例如,在生物信息学中,它可以辅助分析基因序列数据;在物理学中,它可以帮助解释实验结果,从而显著提升科研效率。
智能客服:面对日益增长的用户需求,传统的智能客服往往难以处理复杂的、需要多步推理的问题。Klear-Reasoner能够快速准确地理解用户意图,并提供清晰、逻辑严谨的解决方案。它不仅能回答常见问题,还能处理需要深层推理的疑难杂症,通过提供透明的推理过程,增强用户的信任感,显著提升用户体验和问题解决效率。
结语展望
Klear-Reasoner的发布不仅是快手在AI大模型领域的一次重要探索,更是对开源社区的一大贡献。它展示了通过精细化的数据管理、创新的训练算法和多模态的学习策略,构建具备卓越推理能力的AI模型的可能性。随着Klear-Reasoner及其后续迭代的不断发展,我们有理由相信,AI将在更广阔的领域扮演关键角色,推动生产力进步,并赋能人类探索未知、解决复杂问题的能力。其开源特性也意味着更多的开发者和研究者将能在此基础上进行创新,共同推动人工智能技术的边界。








