
颠覆性里程碑:GUAVA如何重塑单张照片3D化身生成范式
在数字孪生与元宇宙概念日益深入人心的今天,高精度、高效率的3D化身生成技术已成为核心驱动力。长期以来,行业面临着复杂的多视角数据采集、漫长模型训练周期以及高昂制作成本的严峻挑战。然而,清华大学与粤港澳大湾区数字经济研究院(IDEA研究院)的联合团队,凭借其突破性成果——GUAVA框架,彻底改写了这一格局,将3D化身生成推向了前所未有的实时、便捷新高度,并成功入选ICCV2025。
GUAVA最令人瞩目的创新在于其惊人的效率。它能够在短短0.1秒内,仅凭一张普通照片,即可实时生成一个高质量、细节丰富的上半身3D化身模型。这一速度并非简单的性能提升,而是技术路径的根本性变革。传统方法往往需要从多角度拍摄的视频序列,结合复杂的摄影测量或神经辐射场(NeRF)技术进行耗时数小时乃至数天的重建与优化,且通常需要针对每个独立个体进行定制化模型训练。GUAVA的出现,将专业级3D建模从高度专业化、资源密集型的流程,转化为普通用户触手可及的日常操作,极大地降低了技术门槛。
核心技术解密:3D高斯模型与EHM的精妙融合
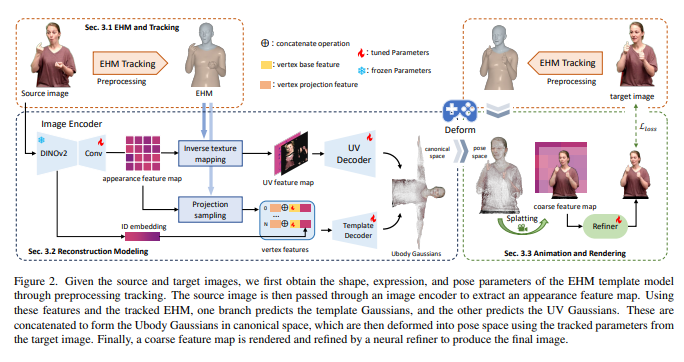
GUAVA框架之所以能实现如此飞跃,其核心在于巧妙引入了全新的3D高斯模型(3D Gaussian Splatting)与EHM(Expressive Human Model)表达式人体模型的融合。传统的网格(Mesh)模型在表示复杂几何形状和细节方面存在局限,而新兴的神经辐射场虽然能生成高质量渲染,但训练和渲染速度往往较慢。GUAVA创新性地利用3D高斯模型,将场景表示为一系列可学习的三维高斯核,每个高斯核都携带了位置、尺度、旋转和不透明度等信息,实现了渲染质量与效率的完美平衡。
与EHM表达式人体模型的结合,是GUAVA能够捕捉细微表情和复杂手势的关键。EHM提供了一个高精度、可控制的人体几何与运动先验,使得GUAVA在仅有单张2D图像的情况下,依然能够推断出丰富的3D结构和姿态信息。这种数据驱动与几何先验的深度融合,不仅解决了单视角深度估计的固有模糊性问题,也确保了最终生成的3D化身在表情、肢体动作上具备高度的逼真度和自然度。例如,通过分析照片中人物的微笑弧度或手部姿态,GUAVA能够准确地将这些二维信息映射到三维空间中,重建出具有相同表情和姿势的虚拟形象。

性能卓越:实时交互的坚实基石
研究团队对GUAVA进行了详尽的对比实验,结果显示其在多个关键指标上均显著超越现有主流2D和3D化身生成方案。在渲染质量方面,GUAVA生成的图像细节丰富,光照与阴影处理自然;在重建精度上,其对人体轮廓和特征点的捕捉精确性达到行业领先水平。更为关键的是,该框架实现了惊人的每秒约50帧渲染速度。这一数字远超多数同类方法普遍的几帧/秒表现,为高互动性、低延迟的实时应用场景奠定了坚实的技术基础。
想象一下,在虚拟现实(VR)会议中,用户可以毫无延迟地看到彼此生动逼真的3D化身,无论是表情变化还是手势交流都如同面对面般自然;在增强现实(AR)应用中,定制的3D虚拟形象能够即时叠加到现实环境中,提供沉浸式的互动体验。GUAVA的实时渲染能力,使得这些曾经的设想正快速变为现实。这不仅仅是技术参数的提升,更是开启全新交互模式的钥匙。
广阔应用前景:重塑数字互动边界
GUAVA技术的广泛应用潜力令人振奋,几乎涵盖所有需要虚拟形象展示的数字化领域。
- 电影与动画制作: 导演和制作团队能够快速为演员创建高质量数字替身,大幅缩短角色建模和动画预演时间,同时降低制作成本。例如,在面对危险场景或需要大量群演的镜头时,可以高效生成逼真的数字克隆。
- 游戏开发: 玩家可以通过一张自拍照,在数秒内拥有高度个性化的游戏角色,极大提升沉浸感和角色代入感。游戏开发者也能更灵活地创建NPC(非玩家角色),丰富游戏世界的多样性。
- 远程办公与虚拟会议: 在元宇宙办公或虚拟协作平台中,GUAVA可生成更生动、更具表现力的3D化身,使远程交流如同线下般真实,增强团队凝聚力和沟通效率。
- 社交媒体与虚拟社交: 用户可以轻松创建自己的虚拟形象,在各类虚拟社交平台进行互动,或应用于个性化AR滤镜、虚拟直播等。这为新兴的虚拟偶像和KOL(关键意见领袖)生态提供了强大的技术支撑。
- 数字营销与电商: 品牌可以利用3D化身进行虚拟产品试穿、虚拟客服,提升用户体验和互动效率。例如,消费者可以上传自拍,在虚拟环境中看到商品穿戴在自己3D化身上的效果。
- 文化遗产保护与数字永生: 通过将历史人物或普通人的照片转化为3D化身,实现数字化的永久保存和互动式展示,为后代提供更直观的文化体验。
开源精神与行业赋能
值得称道的是,清华IDEA团队选择将GUAVA的完整源代码向全球开发者社区开放。这种开放包容的学术精神,不仅为全世界的研究人员提供了宝贵的创新基础,也极大地促进了技术生态的繁荣。开源意味着无数的开发者、研究机构和创业公司可以基于GUAVA进行二次开发、功能扩展和创新应用。这种协同创新模式将加速3D化身技术的演进,催生出更多前所未有的商业机会和用户体验。例如,开发者可以尝试将GUAVA与语音识别、自然语言处理技术结合,创造出更智能、更具情感表达能力的虚拟助手。
技术融合的典范与未来展望
GUAVA项目的成功,是深度学习、计算机视觉、3D建模与图形学等多个前沿领域跨学科深度融合的集中体现。它不仅展示了清华大学在人工智能领域深厚的研究实力,也为未来多模态AI技术的发展提供了新的思路。
随着数字经济与元宇宙的蓬勃发展,市场对高精度、高效率3D虚拟内容的需求呈现爆炸式增长。GUAVA框架恰逢其时,它不仅为现有应用场景提供了强大的技术支撑,更以其卓越的性能和易用性,为整个行业设立了新的技术标杆。未来,我们可以预见GUAVA将进一步向全身3D化身、多风格化生成、动态表情与动作捕捉的更高层次发展。同时,与边缘计算、5G通信等技术的结合,将使其在移动设备和轻量级应用中发挥更大潜力。GUAVA的横空出世,无疑标志着3D化身生成技术进入一个全新纪元,为构建一个更加沉浸、互联的数字世界提供了强大的原动力。








