
具身智能的崛起:AI如何从屏幕走向真实生活
当前,人工智能已渗透到我们生活的方方面面,但其主流形态仍以屏幕内的“对话框”为主。用户通过文字或语音输入指令,AI则迅速生成回应。尽管这种交互模式效率显著,却也引发了一个深层次的疑问:AI的边界是否就止步于此?真正的智能,难道不应是能够与我们共同感知世界、理解我们当下情境的“伙伴”吗?
这种对更高层次AI交互的渴望,正推动着具身智能(Embodied AI)的快速发展。具身智能旨在让AI具备物理身体或通过硬件连接现实世界,从而获取并处理多模态信息,实现更深层次的环境感知和交互。在这一变革浪潮中,一款名为Looki L1的创新型多模态AI硬件,正以前瞻性的视角,将我们对未来AI的想象付诸实践。

超越传统:Looki L1如何定义“AI生活日志”
Looki L1的设计理念,是让AI彻底摆脱传统设备的束缚,无缝融入用户的日常。它并非传统的运动相机或简单的智能挂坠,而是一种全新的“AI生活日志相机”,旨在成为用户生活中的无形记录者和智能理解者。
该设备的极简主义设计是其核心特点之一。无屏幕的机身,仅保留两个物理按键用于激活“故事模式”(Story Mode)、拍照、录像和录音功能。其正面集成的触摸板则实现了与AI的直观对话,操作逻辑类似于微信语音发送,大幅降低了用户学习成本。仅30克的轻巧机身,使得用户几乎可以忽略其存在,从而专注于当下。
Looki L1的核心在于其“故事模式”。一旦开启,设备便会自动捕捉视频和音频,并实时将这些多模态数据输入AI模型。这意味着,用户所处的一切——无论是繁忙的街道、友人的欢声笑语,还是用户自身的表情变化——都将转化为AI理解情境的“提示词”。这种被动而连续的记录方式,使得AI能够真正意义上“体验”用户的生活,从旁观者变为参与者。
AI驱动的个性化记忆重构
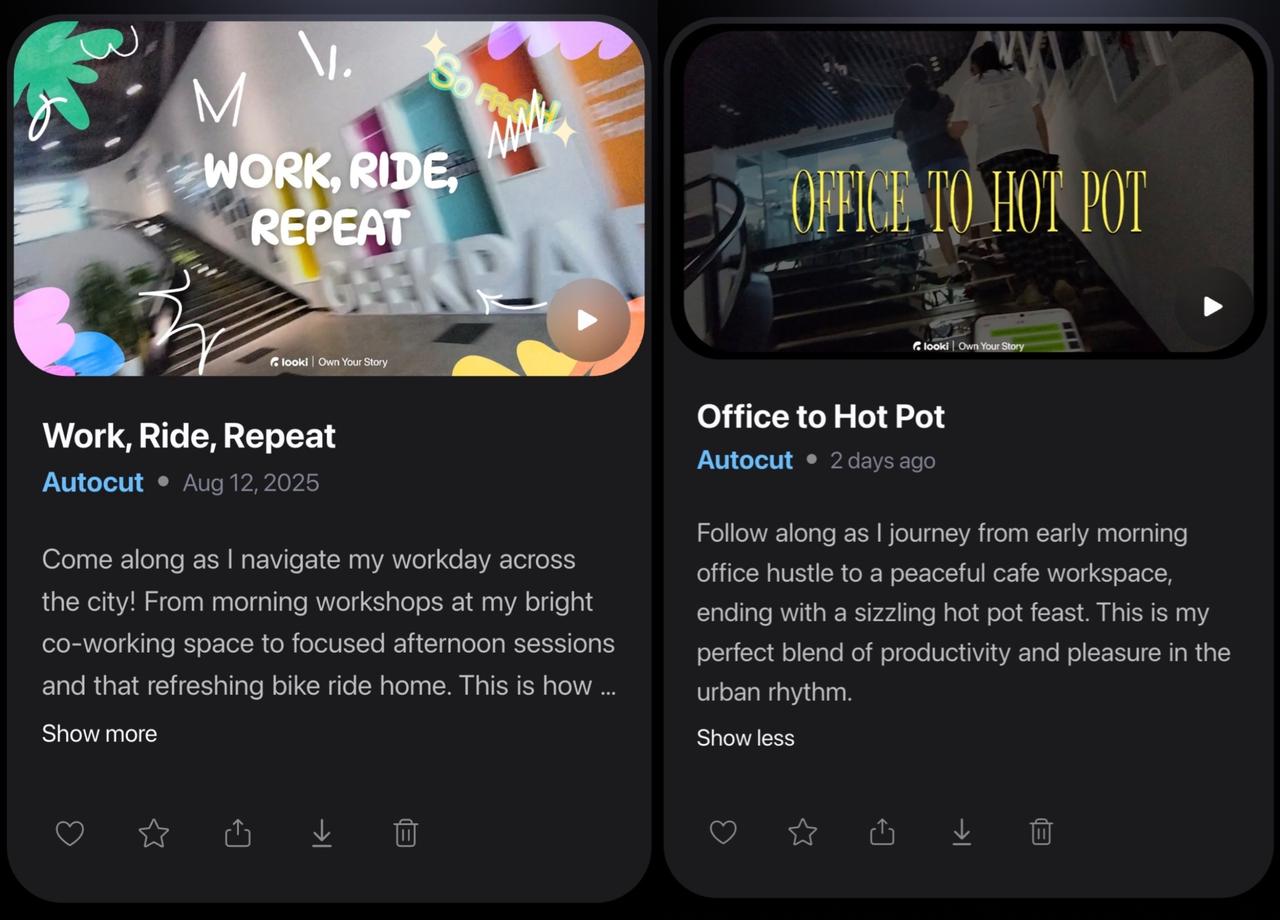
传统上,我们拍摄的大量照片和视频往往沉睡在硬盘中,整理工作耗时耗力。Looki L1通过其独特的多模态AI能力,彻底革新了这一痛点。其“Moments”功能能够自动理解视频中的人物、场景和情感,将海量素材智能整理成一个个有主题的事件,并从中提炼出“高光片段”。这种自动化、智能化的记忆重构,将碎片化的瞬间编织成富有叙事性的生活档案,无需人工介入,极大地节约了用户的时间和精力。

此外,Looki L1还能生成具有专业质感的Vlog。AI会自主梳理出一条故事线,分析并确定主题,并根据主题智能配乐,同时为不同画面添加精准的配文或关键词。这种“导演级”的自动化生成,赋予了用户对日常生活的全新视角。对于不善于后期剪辑或缺乏时间的普通用户而言,Looki L1提供了一个近乎完美的解决方案,让每个人都能轻松拥有自己的生活纪录片。

“AI向内”:重新审视自我与生活
Looki L1最深远的影响,或许在于它促使用户进行更多的“向内审视”。传统的社交媒体倾向于展示“高光时刻”,鼓励一种“表演式分享”。然而,Looki L1的设计哲学却恰恰相反:它不追求极致的画质(采用Sony IMX681 CMOS,1080p分辨率),而是优先保证12小时续航和30克的轻便,以捕捉生活的连续性和日常细节。
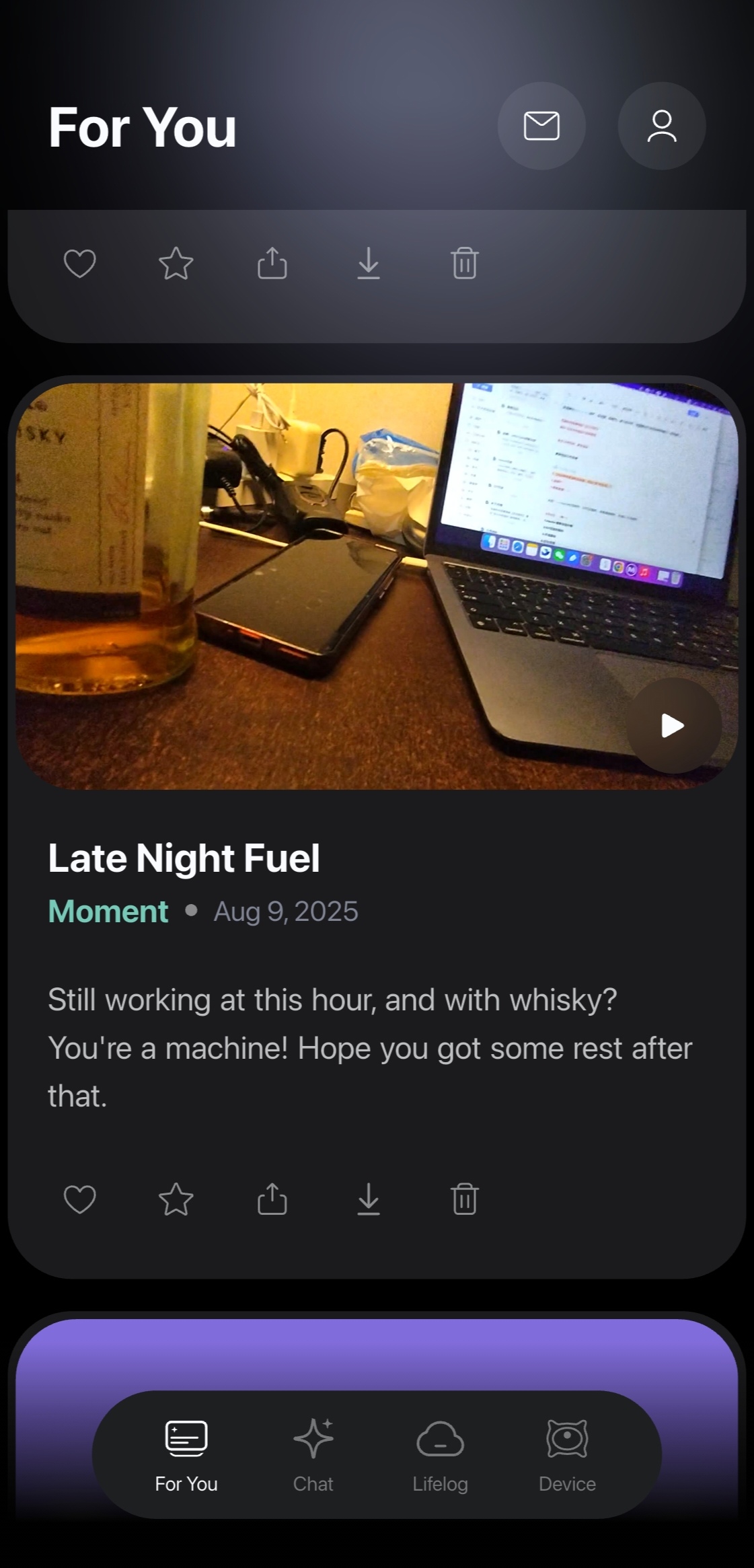
当用户回看Looki AI生成的Moment或Vlog时,常常能发现那些被自己忽视但情感饱满的生活片段。AI基于场景、音频和视频等多维度信息,精准地捕捉并解读这些瞬间,并辅以恰当的描述。这种体验让用户仿佛重新经历了一段时光,从中发现了自己曾被遗忘的快乐、思考或情感,从而加深了对自我的理解。这种“反潮流”的产品机制,旨在引导用户从宏大叙事或八卦消息中抽离,重新聚焦于自己的生活,从日常中发掘惊喜与意义。

多模态AI硬件的战略价值与未来展望
“记录一生”的愿景并非新生事物。早在上世纪90年代,计算机先驱戈登·贝尔便尝试通过佩戴相机记录生活,但最终因缺乏有效的素材整理工具而告失败。如今,多模态AI技术的成熟为这一愿景提供了新的实现路径。Looki L1的突破性在于,它利用多模态AI理解视觉、声音和语义信息,将碎片化的素材转化为可用的“记忆流”。
例如,用户可以通过Looki AI的聊天功能,询问“我昨天喝了什么咖啡?”AI便能迅速分析录像素材,不仅告知咖啡店和口味,还能描述当时的氛围,并列出相关照片。这充分展现了多模态AI在提供个性化、情境化信息方面的独特优势。

这一案例深刻印证了一个行业共识:大模型若要真正发挥作用,必须具备对物理世界的感知能力,即需要与硬件深度融合。当前,“随身AI硬件”已成为创投领域的热点,其核心价值在于为AI提供丰富的“上下文”(context)。传统的AI模型往往缺乏个性化的上下文,导致其答案可能正确却缺乏针对性。
Looki L1通过其硬件设计,能够捕捉用户所处的物理环境信息,从而为接入的ChatGPT和Gemini等大模型提供前所未有的个性化上下文。这种情境化的数据输入,使得AI能够更深入地理解用户的生活,提供远超网页版大模型的定制化服务。可以说,Looki L1所捕捉的现实世界,正在成为其AI模型的鲜活“提示词”。
从长远来看,Looki L1不仅是一款产品,更是“个人AI硬件”发展路径上的一个重要里程碑。近期OpenAI收购前苹果设计总监Jony Ive公司的举动,以及其2026年推出AI硬件的计划,都指向了与Looki L1相似的未来交互愿景。这预示着,AI的终点并非一个简单的对话框,而是与我们共存、共感知、共成长的真实世界。随着具身智能技术的不断演进,我们有理由相信,未来的AI将更加主动、更加个性化,真正成为人类拓展感知与理解能力的智能延伸。








