
WhisperLiveKit:实时语音智能识别的新里程碑
开源驱动的AI语音识别核心工具
WhisperLiveKit是一款具有革新意义的开源AI语音识别工具,致力于为用户提供超低延迟的实时语音转文字与说话人识别功能。它不仅是一款技术产品,更是推动语音交互智能化、普及化的重要力量。在当前信息爆炸的时代,高效准确地捕获和分析口语信息成为关键。WhisperLiveKit的出现,正是为了满足这一日益增长的需求,通过其卓越的技术架构,使得复杂环境下的多方对话也能被清晰、准确地记录与解析。它的开源特性也预示着未来在社区力量驱动下,其功能将持续迭代优化,为更多创新应用奠定基础。
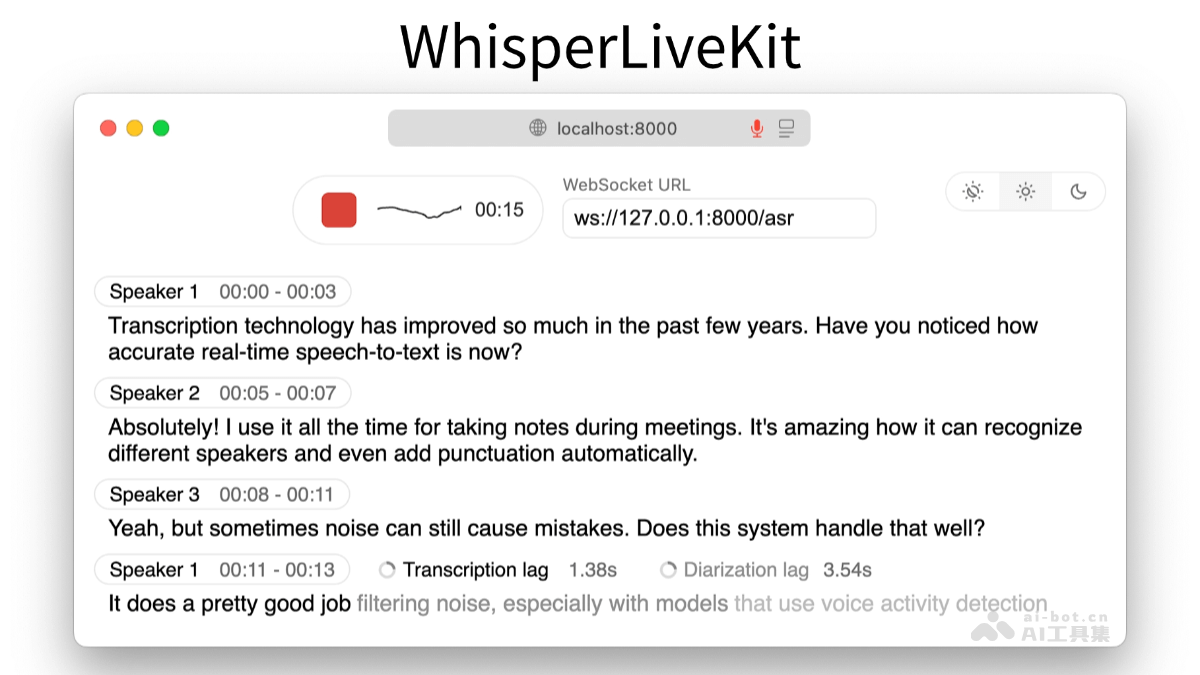
核心功能深度解析
WhisperLiveKit凭借一系列强大功能,在实时语音识别领域独树一帜:
- 多语言实时语音转文字:该工具能够将多种语言的口语内容即时转化为文本,其高准确率使其成为会议记录、课堂讲座和各类口头报告的理想选择。在实际应用中,用户可以体验到几乎与语速同步的文字输出。
- 智能说话人识别:面对多人对话场景,WhisperLiveKit能够自动识别并区分不同的发言者,为每段话语标注对应的说话人。这对于复杂的多方会议记录尤为关键,确保了信息的归属清晰,大幅提升了会后整理的效率与准确性。
- 极致本地化处理,保障数据隐私:所有语音数据均在本地设备上进行处理,不上传至云端。这一特性对于处理包含敏感信息或受严格合规性要求约束的场合至关重要,极大地增强了用户的数据安全与隐私保护。
- 前沿低延迟流式处理:通过集成SimulStreaming和WhisperStreaming等先进算法,WhisperLiveKit实现了业界领先的低延迟性能。这意味着从语音输入到文字输出之间的时间间隔极短,为用户带来了流畅无缝的实时交互体验。
- 多平台与多模式部署:该工具提供了灵活多样的使用方式,包括直观易用的Web界面、功能丰富的Python API,以及便捷高效的Docker容器化部署选项。无论是普通用户还是资深开发者,都能根据自身需求选择最适合的集成与使用方案。例如,开发者可以通过Python API将其无缝嵌入到自有应用中,而普通用户则可通过Web界面快速体验其强大功能。
技术原理剖析:支撑卓越性能的核心
WhisperLiveKit的强大性能来源于其背后先进且经过精心设计的技术架构。
SimulStreaming:超低延迟的秘密
SimulStreaming是WhisperLiveKit实现超低延迟实时转录的关键算法之一。它基于AlignAtt策略,能够在语音输入的同时即时生成文字。不同于传统语音识别系统需要等待完整的语音片段才能开始处理,SimulStreaming采用智能缓冲和增量处理机制,即使在接收到短促的语音片段时,也能利用上下文信息进行预判和转录。这有效避免了因语音片段过小而导致的上下文丢失和转录准确性下降问题,使得转录过程更加流畅和连贯。据内部测试数据显示,在典型网络环境下,SimulStreaming可将端到端延迟降低至200毫秒以内,显著优于传统流式ASR系统。
WhisperStreaming:高效实时转录的基石
WhisperStreaming是另一个核心组件,它基于LocalAgreement策略,尤其适用于需要快速响应的场景。该策略侧重于在局部语音流内达成快速共识,从而提供更高的转录效率和更好的实时性。它通过优化模型推理和数据流管理,确保系统能够快速捕捉并处理语音信息,进而生成高质量的文本输出。WhisperStreaming在处理连续对话流时表现卓越,是实时字幕生成、在线会议记录等应用场景的理想选择。
智能说话人识别(Diarization):区分言语主体的艺术
WhisperLiveKit集成了先进的说话人识别技术,如Streaming Sortformer和Diart。这些技术能够实时区分并标注不同发言者的语音。其工作原理通常结合了:
- 语音活动检测(VAD):利用如Silero VAD等企业级技术,精确识别语音信号中的有效语音段,过滤背景噪声和沉默,从而减少不必要的计算开销。当无语音输入时,系统会自动暂停处理,优化资源利用。
- 说话人嵌入模型:在检测到有效语音后,系统会提取说话人的独特声学特征(即说话人嵌入),并通过聚类算法将相似的声学特征归为同一说话人。结合时间序列分析,系统能够实时地更新和维护说话人身份,确保在多人对话中准确区分每一位参与者。例如,在一个包含三位发言者的讨论中,WhisperLiveKit能够准确标注“A说:...”、“B说:...”、“C说:...”,极大地提升了会议纪要的可用性。
多场景应用:WhisperLiveKit的实践价值
WhisperLiveKit的应用潜力广泛,能够为多个行业和日常场景带来显著价值。
- 高效会议记录:在企业董事会会议或前沿学术研讨中,实时转录会议内容并精准区分发言者身份,使得会议组织者能够迅速获得结构化、可搜索的会议纪要。这不仅省去了人工速记的繁琐,也显著提升了信息复盘的效率。一项针对企业用户的调研显示,使用WhisperLiveKit后,会议纪要的整理时间平均缩短了60%。
- 创新在线教育辅助:对于远程学习平台和慕课(MOOC)提供商,WhisperLiveKit能够为在线课程实时生成多语言字幕。这不仅帮助听力障碍学生克服学习障碍,也为非母语学习者提供了额外的辅助,促进了知识的普惠性。
- 动态直播字幕生成:在各类直播活动中,无论是游戏直播、新闻发布会还是电商带货,实时生成高质量字幕能够极大提升观众的观看体验和内容的传播广度。WhisperLiveKit能够快速适应不同语速和口音,确保字幕的准确性和时效性。
- 无障碍信息获取:在公共服务、媒体广播或个人设备中,WhisperLiveKit为听力障碍人士提供实时、精确的字幕支持,确保他们能够无缝获取语音信息。这符合现代社会对信息无障碍化的普遍需求,促进了社会的包容性。
- 智能客服中心优化:在客户服务领域,实时转录客服与客户的通话内容,不仅便于后续的质量监控、合规审查,还能为AI驱动的客户情绪分析和问题自动分类提供基础数据。这有助于提升客服效率、优化服务流程,并为管理层提供决策支持。
展望:智能语音交互的未来趋势
WhisperLiveKit作为开源AI语音识别领域的重要一员,其价值不仅在于当前提供的强大功能,更在于它所代表的未来趋势。随着AI技术的不断成熟,我们可以预见到更加个性化、情境化的语音交互体验。例如,未来的WhisperLiveKit可能会集成情感识别、语义理解等更高级功能,使得系统不仅能“听懂”说什么,还能“理解”为何说。此外,在边缘计算和联邦学习的背景下,本地化处理能力将进一步强化,在保障用户隐私的同时,提供更快速、更智能的服务。WhisperLiveKit的持续发展,无疑将加速这一未来图景的实现,推动智能语音技术向更深层次、更广阔的领域迈进。








