
Google推出的Gemma 3 270M模型,以其小巧的体积和显著的运行效率,正在重新定义人工智能的部署范式。这款仅拥有2.7亿参数的微型AI模型,旨在将强大的智能能力从庞大的云服务器下放到日常的本地设备,例如智能手机和网页浏览器。这一战略性举措不仅彰显了Google在AI领域的前瞻性视野,更预示着一个更加私密、响应迅速且无处不在的智能未来。
AI发展趋势的演变:从云端到边缘
在过去的几年里,人工智能领域的主流趋势是构建规模日益庞大的模型。这些模型动辄拥有数十亿乃至上万亿的参数,需要海量的计算资源,通常通过大型数据中心内的GPU集群以云服务的形式提供。虽然这些巨型模型在处理复杂任务和实现高精度方面表现出色,但也带来了诸多挑战:高昂的计算成本、巨大的能源消耗、对网络连接的依赖以及日益增长的数据隐私担忧。用户的数据往往需要在设备和云端之间传输,这不仅增加了延迟,也为潜在的隐私泄露留下了空间。
正是在这样的背景下,边缘计算和设备端AI的重要性日益凸显。将AI模型直接部署在用户设备上,能够实现数据在本地处理,无需上传至云端,从而极大地增强了用户隐私保护。同时,本地处理消除了网络延迟,使得AI应用的响应更为即时。此外,对于某些对实时性要求极高的应用场景,如自动驾驶、工业自动化或实时翻译等,本地AI更是不可或缺。Gemma 270M的出现,正是Google对这一趋势的积极响应,它代表着AI技术民主化和普惠化的重要一步。
技术揭秘:Gemma 270M的核心优势与创新设计
Gemma 270M之所以能实现如此小的体积和高效能,得益于Google在模型设计和优化方面的深厚积累。在生成式AI领域,模型的“参数”可以理解为训练过程中学习到的变量,它们决定了模型如何根据输入生成输出。通常而言,参数越多,模型的性能越强。然而,Gemma 270M以其2.7亿的参数量,在性能上却能超越同级别的轻量级模型,这本身就是一项显著的工程成就。

该模型并非简单地将大型模型“缩小”,而是针对资源受限的设备进行了专门优化。Google可能采用了包括模型蒸馏、量化技术、剪枝以及更高效的网络架构设计等多种手段,以在大幅削减参数的同时,最大限度地保留模型的知识和推理能力。这种精巧的设计使得Gemma 270M能够在计算能力有限的设备上平稳运行,开启了AI应用的新篇章。
实测表现与广泛应用潜力
Gemma 270M的强大并非纸上谈兵。Google在实际测试中展示了其令人印象深刻的效率。例如,在Pixel 9 Pro手机上,这款模型能够在Tensor G4芯片上运行25次对话,而仅消耗设备0.75%的电池电量。这意味着用户可以在不显著影响设备续航的情况下,长时间享受本地AI服务。这一测试结果远超此前的Gemma模型,使其成为目前效率最高的Gemma系列成员,为移动AI应用的大规模普及奠定了基础。
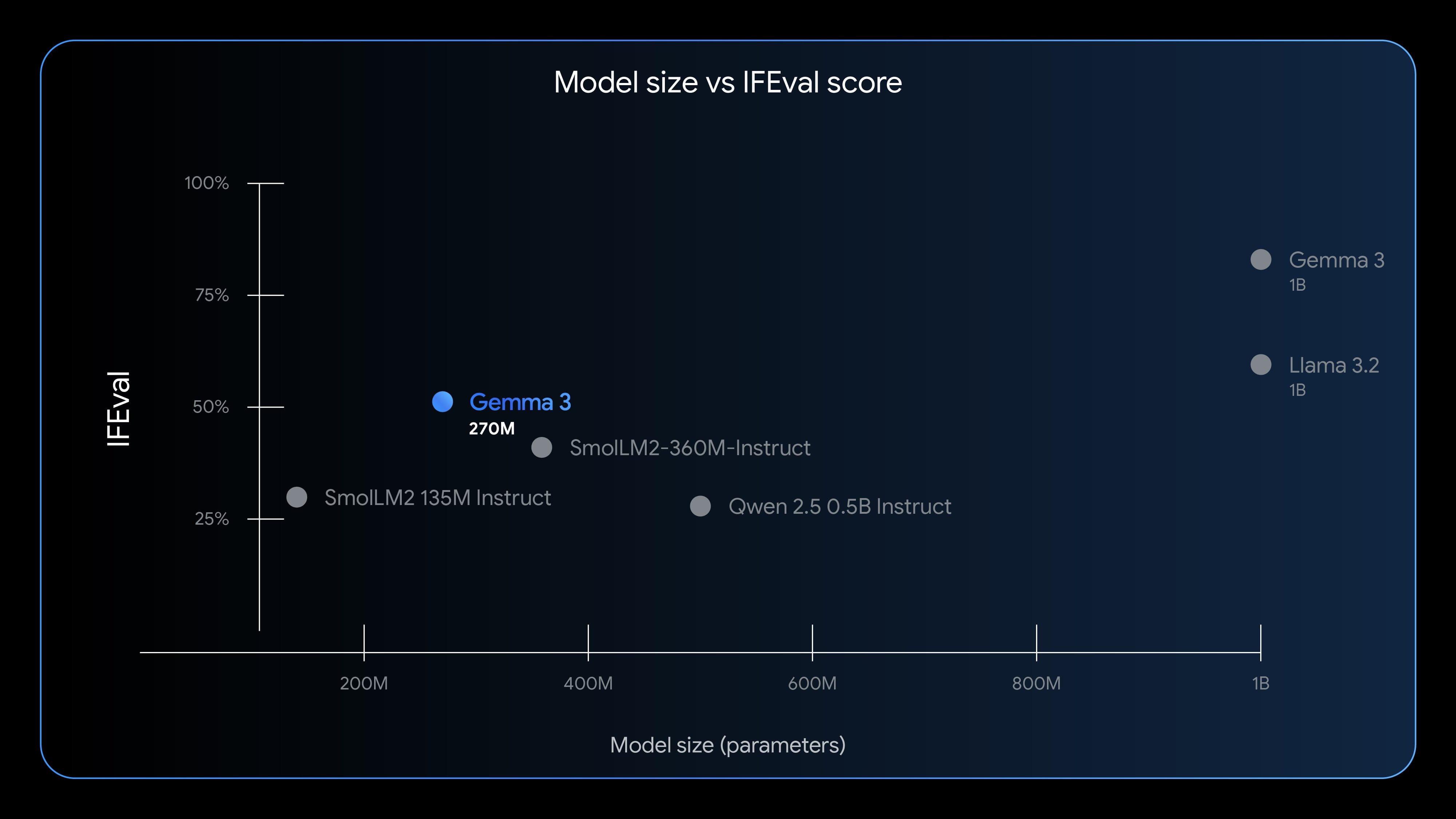
为了衡量Gemma 270M的实际性能,Google采用了IFEval基准测试。IFEval专注于评估模型遵循指令的能力,这是衡量AI实用性的一个关键指标。Gemma 270M在此测试中取得了51.2%的得分,这一成绩高于许多参数量更大的同类轻量级模型,充分证明了其在执行指令方面的卓越表现。尽管与Llama 3.2等参数量达数十亿的巨型模型相比仍有差距,但其“以小博大”的能力,已足够令人惊叹。
Gemma 270M在实际应用中具有巨大的潜力。Google预期,该模型将广泛应用于文本分类和数据分析等任务。在文本分类方面,它可以用于设备端的垃圾邮件过滤、用户评论情感分析、新闻文章主题归类,甚至是个性化推荐系统的本地内容筛选。在数据分析领域,Gemma 270M能够处理小型数据集的模式识别、异常检测,或对本地用户行为数据进行初步洞察,从而提供更智能的设备管理和个性化服务。此外,其低延迟特性也使其非常适合于设备端语音助手、实时翻译、智能家居控制以及轻量级内容生成(如邮件草稿、短消息建议)等场景,极大地提升了用户体验。
“开放”与“开源”之辩:理解Gemma的许可模式
Google将Gemma模型系列定义为“开放”模型,这与传统的“开源”概念有所区别,但实际上在大多数方面提供了相似的灵活性。“开放”意味着开发者可以免费下载Gemma 270M模型,并且模型的权重是公开可用的。此外,该模型没有独立的商业许可协议,开发者可以自由修改、发布和部署基于Gemma 270M的衍生工具。
然而,与完全的开源不同,所有使用Gemma模型的开发者都必须遵守其使用条款。这些条款明确禁止将模型用于生成有害内容或故意侵犯隐私。开发者也有责任详细说明模型的修改内容,并在所有衍生版本中提供一份使用条款副本,这些衍生版本将继承Google的自定义许可。这种“半开放”的模式允许Google在推动AI技术普及的同时,保持对模型安全、伦理和负责任使用的控制。对于开发者而言,这意味着在享受模型带来的便利和灵活性的同时,也需要注意遵守相关的规范,共同维护健康的AI生态。
开发者视角:快速微调的价值与生态系统支持
对于开发者而言,Gemma 270M的一个核心吸引力在于其快速且低成本的微调能力。由于模型参数量较小,微调过程所需的时间和计算资源都大幅减少。这使得开发者能够更容易地针对特定应用场景和用户需求对模型进行定制化,无论是优化特定领域的语言理解,还是改进特定任务的执行精度,都可以在更短的时间内完成,显著降低了开发成本和技术门槛。
Google为Gemma 270M构建了完善的开发者生态系统。该模型已在Hugging Face和Kaggle等主流AI开发平台上发布,提供了预训练版本和指令微调版本,方便开发者根据自身需求选择。Hugging Face作为一个领先的机器学习社区,为模型的下载、测试和共享提供了便捷的渠道;Kaggle则以其数据科学竞赛和数据集资源,为开发者提供了丰富的实验和学习环境。此外,Google自己的Vertex AI平台也支持Gemma 270M的测试和部署,使其能够无缝集成到Google Cloud的现有服务中,为企业级应用提供了强大的支持。
Google还通过实际案例展示了Gemma 270M的潜力,例如基于Transformer.js构建的完全浏览器内的故事生成器。这一演示不仅直观地展示了模型在本地设备上的运行能力,也激励了更多开发者探索无需云端服务器、完全在浏览器中运行的创新AI应用,进一步拓展了设备端AI的可能性。
未来展望:Gemma 270M如何驱动边缘AI的革新与挑战
Gemma 270M的发布,无疑将深刻影响未来的科技格局,尤其是在边缘AI领域。这款微型模型有望成为智能手机、物联网设备、可穿戴设备乃至汽车AI系统中的核心组件,实现更深层次的个性化和智能化。设想一下,未来的智能手表可以离线执行复杂的健康数据分析;智能音箱可以在没有网络连接的情况下理解并响应用户指令;手机上的图像识别和自然语言处理功能将变得更加即时和私密。
这种趋势也将催生新的商业模式和应用场景。此前因云端AI的成本、延迟或隐私问题而无法实现的应用,现在有了成为现实的可能。例如,在偏远地区或网络条件不佳的环境下,本地AI将发挥关键作用。在医疗健康领域,个人健康数据可以在设备端进行初步处理和分析,更好地保护用户隐私,同时提供定制化的健康建议。
当然,Gemma 270M和边缘AI的发展也面临挑战。尽管该模型在效率上取得了巨大突破,但与大型云端模型相比,其在处理极其复杂或需要海量知识的任务时,仍可能存在性能上限。此外,设备端的计算资源和电池续航依然是重要的约束因素,需要硬件制造商(如Google的Tensor芯片)和软件开发者持续优化。模型的持续更新、维护和安全性也是需要重点关注的领域,以确保AI模型在本地环境中始终保持最佳状态。
综上所述,Gemma 270M不仅仅是一个参数更小的AI模型,它代表着人工智能部署理念的一次重大转变。通过赋能本地设备,Google正在推动AI走向一个更私密、更高效、更具韧性的未来。随着技术的不断演进和开发者生态的日益壮大,我们有理由相信,以Gemma 270M为代表的微型AI模型,将成为下一代智能应用的核心驱动力,深刻改变我们与科技互动的方式。








