
SuperCLUE-VLM八月评测揭示多模态AI新格局
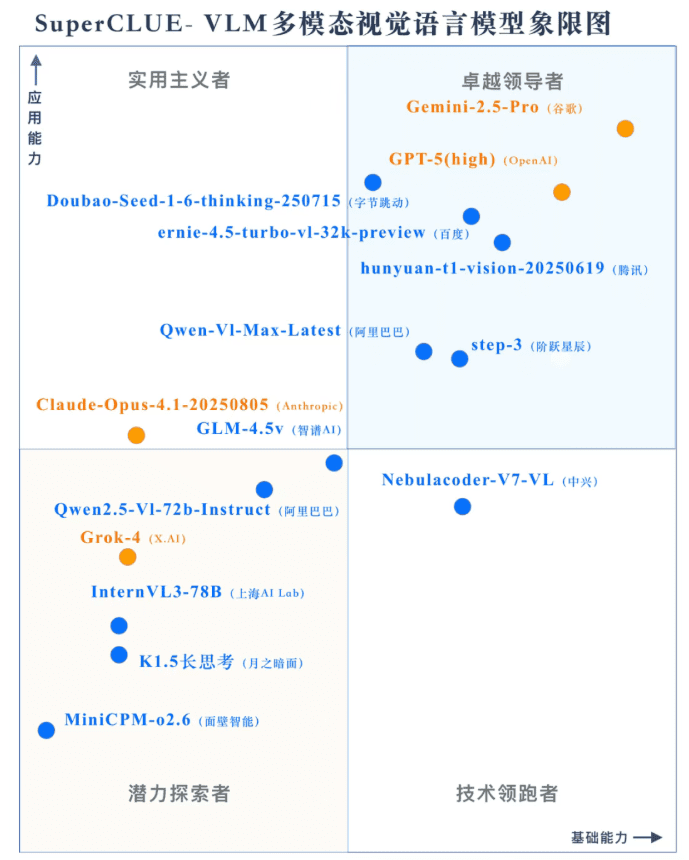
2025年8月28日,中文多模态视觉语言模型(SuperCLUE-VLM)评测基准正式发布了其最新榜单。在本次备受关注的评估中,Google旗下的Gemini-2.5-Pro以总分74.99分的优异成绩位居榜首,再次验证了其在复杂多模态任务处理上的强大实力。紧随其后的是OpenAI的GPT-5(high),以68.59分稳居第二,表明两大科技巨头在人工智能前沿领域的持续领先。
此次SuperCLUE-VLM评测不仅是一次简单的性能排名,更是对当前全球多模态视觉语言模型发展现状的一次全面审视。它为研究人员、开发者及行业用户提供了理解和选择合适模型的关键参考,尤其是在中文语境下的多模态应用场景中,其指导意义不言而喻。
评测体系深度解析:三大核心维度
SuperCLUE-VLM评测基准的构建,充分考虑了中文场景的独特性和复杂性,旨在提供一个客观、公正且全面的评估框架。其评测体系主要围绕以下三大核心维度展开:
1. 基础认知能力
基础认知维度侧重于评估模型对图像内容的识别、理解和描述能力。这包括对图像中的物体、场景、颜色、形状等基本视觉元素的准确识别,以及将这些视觉信息转化为准确的自然语言描述。例如,模型能否正确识别一张图片中的“猫”并描述其动作,或准确识别出特定地标。这是所有视觉语言模型进行更复杂任务的基础,其性能直接影响后续的推理与应用。
2. 视觉推理能力
视觉推理是多模态模型高级能力的核心体现,它要求模型不仅能“看懂”图像,还能在此基础上进行逻辑判断、因果推断和问题解决。此维度测试模型在复杂场景下的分析能力,比如理解图像中多个元素之间的关系,推断出事件的潜在发展,或根据图像信息回答需要推理的问题。例如,给定一张包含多个人的图片,模型能否推断出他们之间的社交关系或正在进行的活动。
3. 视觉应用能力
视觉应用维度则更贴近实际场景需求,评估模型在特定应用任务中的表现。这可能包括图像问答、图像生成描述、视觉定位、文档理解、图表分析等。在实际工作中,模型的实用性往往取决于其在这些具体应用场景中的表现。例如,在医疗领域,模型能否辅助医生分析医学影像;在教育领域,能否根据教学图片生成详细解释。
通过这三大维度的全面考量,SuperCLUE-VLM力求为多模态视觉语言模型的发展提供一个既具深度又具广度的评估标准,从而推动整个AI领域的技术进步和应用创新。
竞争格局:国内外模型群雄逐鹿
本次SuperCLUE-VLM评测汇集了国内外共计15个主流多模态模型,展现了当前AI领域的激烈竞争。参与评测的模型包括但不限于Claude-Opus-4.1、Gemini-2.5-Pro、GPT-5(high)、ERNIE-4.5-Turbo-VL、Doubao-Seed-1.6-thinking、hunyuan-t1-vision以及Qwen-V1-Max-Latest等。
这些模型代表了当前多模态AI技术的最高水平,它们在不同维度上的表现,共同构建了多模态模型技术图景。值得注意的是,不仅国际巨头表现亮眼,国内模型如百度的ERNIE-4.5-Turbo-VL也展现出强劲的市场竞争力,与其他国内模型并驾齐驱,彰显了中国AI技术生态的蓬勃发展。

最终榜单显示,Gemini-2.5-Pro以绝对优势位居榜首,其在处理复杂视觉信息和生成准确描述方面的能力得到了充分验证。GPT-5(high)紧随其后,展现了OpenAI在通用人工智能领域的持续投入和深厚积累。百度文心大模型系列中的ERNIE-4.5-Turbo-VL也取得了不俗成绩,表明其在中文语境下的优化和本地化能力日趋成熟。
Gemini-2.5-Pro登顶背后的技术洞察
Gemini-2.5-Pro的优异表现,反映了其在多模态融合架构、大规模预训练数据以及高效推理算法等方面的领先优势。Google在多模态模型上的长期投入,使其能够有效整合视觉与语言信息,实现更深层次的语义理解和更精确的响应生成。
其模型设计可能采用了更先进的跨模态注意力机制,使得模型在处理视觉和文本输入时能够更好地捕捉它们之间的内在关联,从而在视觉推理和复杂问答任务中展现出卓越性能。此外,针对中文数据集的优化和大规模高质量数据的训练,也可能是其在SuperCLUE-VLM评测中脱颖而出的关键因素。
多模态AI的未来趋势与挑战
SuperCLUE-VLM八月评测榜单的发布,不仅是对当前技术成果的总结,也预示着多模态AI领域未来的发展方向。以下几个趋势值得关注:
- 更强大的通用性:未来的多模态模型将不再局限于特定任务,而是向着更通用的智能体方向发展,能够处理更加多样化和开放性的多模态输入。
- 细粒度理解的提升:模型将能够对图像中的微小细节进行更精准的识别和推理,从而在专业领域(如医疗诊断、工业检测)发挥更大作用。
- 实时交互与低延迟:随着应用场景的扩展,对模型响应速度和实时交互能力的要求将越来越高,需要更高效的模型架构和推理优化技术。
- 道德与安全:多模态AI在生成内容和进行决策时所涉及的伦理、偏见和安全问题将成为研究和应用中不可忽视的挑战,需要建立更完善的评估标准和监管机制。
此次评测结果清晰地展现了多模态视觉语言模型领域的快速演进,以及各大参与者在技术创新上的不懈努力。随着模型能力的持续提升,我们有理由相信多模态AI将在更多领域发挥革命性的作用,深刻改变人机交互和信息处理的方式,开启智能应用的新篇章。








