
这是一个值得铭记的时刻!DeepSeek 项目在全球最大代码托管平台 GitHub 上的 Star 量,竟然超越了 OpenAI!
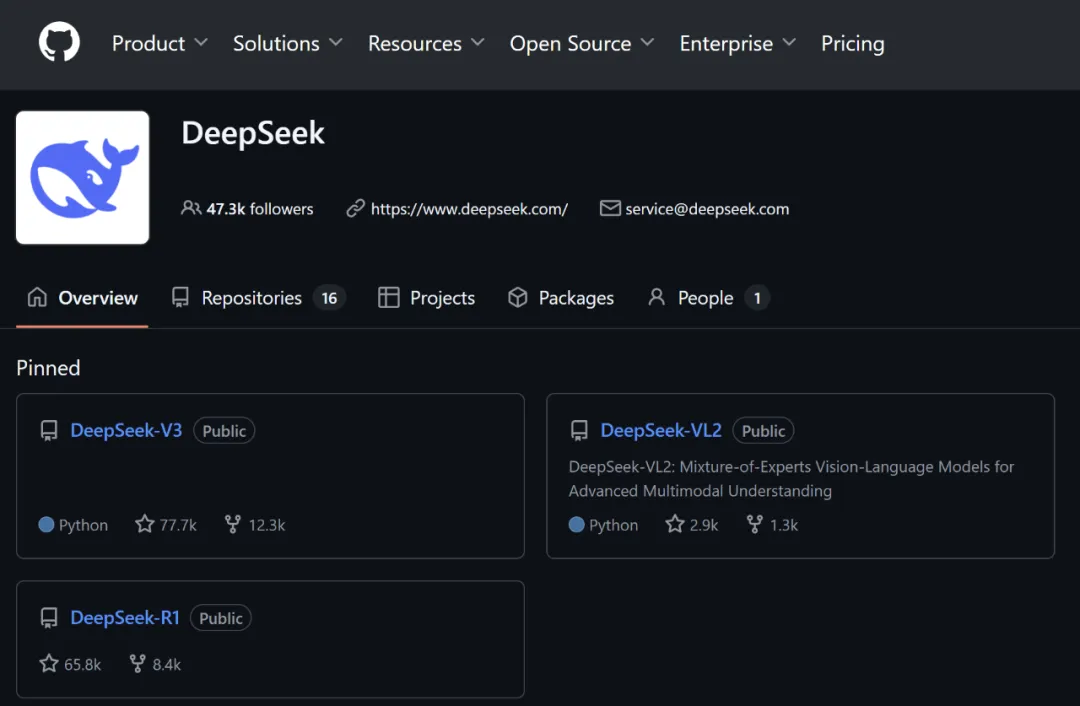
截至本周五下午两点,DeepSeek 旗下热度最高的项目 DeepSeek-V3 大模型 Star 量已达 7.77 万,超越了同平台中 OpenAI 最热门项目。
要知道,OpenAI 作为 AI 领域的领头羊,一直备受瞩目。DeepSeek 能够在短短两个月内超越 OpenAI,这无疑是开源 AI 领域的一个里程碑事件,也预示着开源 AI 正在崛起。
DeepSeek-V3:开源AI的性能标杆
DeepSeek 之所以能够获得如此高的关注度,与其强大的技术实力密不可分。
去年 12 月 26 日,DeepSeek AI 开源了其最新混合专家(MoE)大语言模型 DeepSeek-V3,它立即成为通用语言模型的性能标杆,受到了全球 AI 社区热议。
DeepSeek-V3 模型引入了动态注意力机制(Dynamic Attention Mechanism),通过实时调整注意力权重优化文本生成质量。其 MoE 架构共包含 6710 亿参数,但每 Token 仅激活 370 亿参数,大幅降低了计算成本,训练成本仅为同类闭源模型的 1/20。

据技术报告介绍,DeepSeek-V3 的预训练过程只花费 266.4 万 H800 GPU Hours,再加上上下文扩展与后训练的训练共为 278.8 H800 GPU Hours(训练成本 557.6 万美元)。相较之下,Llama 3 的训练预算约为 3930 万 H100 GPU Hours。
DeepSeek-R1:重塑开源AI的训练范式
如果说 DeepSeek-V3 是开源 AI 的性能标杆,那么 DeepSeek-R1 则是开源 AI 的训练范式。
在 1 月 23 日,DeepSeek 以 V3 为基础使用强化学习(Reinforcement Learning)驱动重构训练范式,提出了 DeepSeek-R1,彻底改变了开源 AI 世界。
DeepSeek R1 性能完全对标 OpenAI o1,与 DeepSeek V3 相比性能有大幅提升,其论文指出纯强化学习可以赋予 LLM 强推理能力,而无需大量监督微调,震动了 AI 业界。
从技术角度来看,DeepSeek 展示了国内科研团队的创新能力,并在 Scaling Laws 之后揭开了大模型发展的新范式,大幅降低了 AI 对算力的依赖,并用自我进化的方式平衡了数据优势。
R1 还支持将推理能力迁移至更小模型,为边缘计算和即时应用开辟了大量的可能性。
开源的力量:DeepSeek的成功之道
DeepSeek 的成功,离不开其拥抱开源的策略。
由于 OpenAI 自 GPT-3 起并未开源其基础 AI 大模型,目前 OpenAI 的热门开源项目包括 openai-cookbook,即使用 OpenAI API 完成常见任务的示例代码和指南;以及 Whisper,这是一个 2022 年 9 月开源的通用语音识别模型。
相比之下,DeepSeek 选择了开源其核心技术,这不仅吸引了全球 AI 社区的关注,也为开发者提供了更多的机会。
DeepSeek V3 和 R1 的推出仿佛为全球大模型社区打了一针强心剂,在 AI 研究领域,围绕 R1 核心强化学习方法 GRPO 的进一步研究已经出现。
DeepSeek 开源的策略也为应用创造了大量机会。目前虽然 DeepSeek App 官方报告正在受到高频次网络攻击,但仅在国内就有阿里云、华为云、腾讯云、百度智能云、360 数字安全、云轴科技等多个平台宣布上线了 DeepSeek 大模型,方便各路开发者调用。
在海外,英伟达、亚马逊和微软云服务也宣布接入了 DeepSeek R1。
开源AI的未来:星辰大海,无限可能
DeepSeek 系列模型被公认为是目前最先进的大语言模型之一,随着技术开源的推动,我们或许将见证生成式 AI 更快的发展。
DeepSeek GitHub 星数超越 OpenAI,这不仅仅是一个数字的超越,更代表着开源 AI 的崛起。
我们相信,在开源社区的共同努力下,AI 技术将能够更快地发展,更好地服务于人类。
让我们一起期待开源 AI 的未来,相信它将带给我们更多的惊喜和可能!








