
近年来,人工智能在内容创作领域的演进速度令人瞩目。特别是三维(3D)内容生成,一直是技术前沿的焦点。腾讯近期发布的HunyuanWorld-Voyager(以下简称Voyager)模型,正是在这一背景下应运而生,它以其独特的“单图生成可探索3D世界”能力,为行业带来了新的想象空间。该模型的核心创新在于,能够从一张普通的静态图片出发,生成一系列具有高度空间一致性的视频帧及深度信息,让用户仿佛能在一个虚拟的三维环境中自由“漫游”。
与传统3D建模技术不同,Voyager并非直接构建一个几何意义上的3D模型,而是通过一系列2D视频帧的巧妙组合,模拟出在三维空间中移动的视觉效果。这些生成的视频帧在空间上保持高度连贯性,这意味着当“摄像机”在虚拟场景中移动时,物体会保持其相对位置,并且视角变化符合真实世界中的透视规律。虽然输出的是带有深度图的视频而非纯粹的3D模型,但这些丰富的深度信息可以进一步转化为3D点云,为后续的3D重建工作提供基础,这无疑为数字内容创作开辟了新的路径。
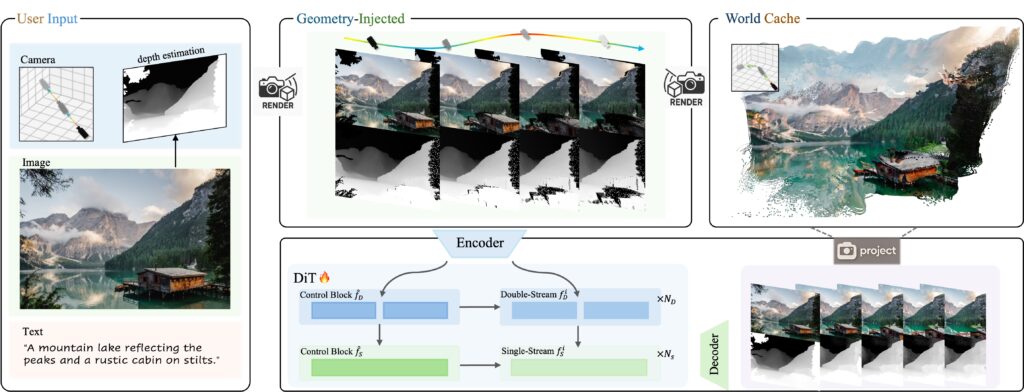
Voyager的运作机制相当精巧。用户只需提供一张输入图像,并定义好摄像机的运动轨迹——无论是向前、向后、向左、向右,还是旋转——系统便能依据这些指令生成相应的视频序列。其内部整合了图像与深度数据处理,并辅以一种内存高效的“世界缓存”机制,以确保在生成视频序列时,能够准确反映用户定义的摄像机移动,从而营造出沉浸式的探索体验。
突破Transformer架构的泛化挑战
当前的许多AI模型,特别是基于Transformer架构的模型,普遍面临一个核心挑战:它们的性能高度依赖于训练数据的模式模仿,这限制了它们在训练数据未涵盖的新颖情境中进行“泛化”的能力。Voyager为了克服这一局限,采取了一种创新的几何反馈循环机制。

大多数AI视频生成器,例如OpenAI的Sora,主要关注生成帧与帧之间的视觉合理性,但往往不刻意追踪或维持精确的空间一致性。Voyager则不然,它不仅被训练识别并复现空间一致性的模式,更在此基础上引入了几何反馈。具体而言,当模型生成每一帧时,它会将其输出转化为3D点,然后将这些点重新投影回2D平面,作为未来帧的参考。这种技术迫使模型将习得的模式与自身先前输出的几何一致性投影进行匹配。尽管这显著提升了空间连贯性,使其远超标准视频生成器,但其本质仍是受几何约束引导的模式匹配,而非真正的3D“理解”。这也是为什么模型能维持数分钟的连贯性,但在进行360度全方位旋转时可能出现挑战的原因——模式匹配中的微小误差会在多帧累积后,超出几何约束所能维持的连贯范围。
从技术报告来看,Voyager系统由两大核心部分协同工作。首先,它同步生成彩色视频和深度信息,确保两者完美匹配,例如,视频中出现的树木在深度数据中会精准显示其距离。其次,它利用腾讯所谓的“世界缓存”——一个由先前生成帧创建的不断增长的3D点集合。在生成新帧时,这个点云会从新的摄像机角度重新投影回2D,形成部分图像,显示基于先前帧应该可见的内容。模型随后将这些投影作为一致性检查,确保新帧与已生成的内容保持对齐。
行业竞争与Voyager的独特优势
AI“世界生成”模型领域竞争激烈,谷歌的Genie 3和Dynamics Lab的Mirage 2是其中的佼佼者。谷歌Genie 3专注于从文本提示生成实时互动世界,主要用于训练AI智能体,目前尚未公开。Mirage 2则提供基于浏览器的世界生成服务,允许用户上传图像并转化为可玩环境。相较而言,Voyager的定位更侧重于视频制作和3D重建工作流,其RGB-深度输出能力是其显著特色。
Voyager的推出,是腾讯更宏大“混元”生态系统的一部分。该生态系统已包括HunyuanWorld 1.0、用于文本到3D生成的Hunyuan3D-2,以及早前发布的视频合成模型HunyuanVideo。这些模型的协同发展,展现了腾讯在AIGC(AI Generated Content)领域的全面布局。
自动化训练管道与算力要求
为了训练Voyager,研究人员开发了一套自动化软件,能够自动分析现有视频,处理摄像机运动,并为每一帧计算深度信息。这种方法避免了人工标注数千小时视频素材的繁重工作。训练数据集包含了超过10万个视频剪辑,这些剪辑既有真实世界录像,也包括了从虚幻引擎渲染的计算机生成场景。这种混合数据训练,让模型能够学习到真实世界与虚拟环境中摄像机运动和场景构建的复杂模式,从而提升其生成效果的真实感和多样性。
然而,运行Voyager对计算资源提出了极高要求。即使是生成540p分辨率的内容,也至少需要60GB的GPU内存,而腾讯官方建议使用80GB以获得更优结果。尽管腾讯已在Hugging Face上开放了模型权重,并提供了支持单GPU和多GPU设置的代码,但如此庞大的算力需求,无疑会限制其在普通消费者层面的普及。同时,该模型还伴随着严格的许可限制,例如禁止在欧盟、英国和韩国使用,并且对于每月活跃用户超过1亿的商业部署需要单独授权,这些都对其全球范围内的应用与推广构成了挑战。
性能基准与未来展望
在由斯坦福大学研究人员开发的WorldScore基准测试中,Voyager据称取得了77.62的最高总分,超越了WonderWorld的72.69和CogVideoX-I2V的62.15。它在物体控制、风格一致性和主观质量方面表现突出,尽管在摄像机控制方面略逊于WonderWorld。这些基准测试结果,从一定程度上证明了Voyager在生成质量和空间连贯性方面的领先地位。
对于需要更快处理速度的开发者,该系统支持使用xDiT框架进行多GPU并行推理。在八个GPU上运行,处理速度比单GPU设置快6.69倍,这在一定程度上缓解了算力瓶颈,为专业应用场景提供了解决方案。
尽管Voyager在生成长时间、高度连贯的“世界”方面仍存在挑战,且对算力要求严苛,但我们正目睹着人工智能在互动式、生成式艺术形式领域迈出的早期而关键的步伐。Voyager所展现的从单一图像构建可探索虚拟场景的能力,预示着电影制作、虚拟现实体验、建筑可视化乃至数字孪生等多个领域,都可能迎来颠覆性的变革。未来,随着算法效率的提升和硬件成本的降低,这类技术有望更加普及,为内容创作者和消费者带来前所未有的沉浸式体验。

