
人工智能领域正经历着前所未有的变革,尤其是大模型技术的飞速发展。然而,传统基于Transformer架构的大模型在处理超长序列数据时,普遍面临计算复杂度和内存消耗的严峻挑战。中国科学院自动化研究所近期推出的SpikingBrain-1.0(瞬悉 1.0)类脑脉冲大模型,为这一难题提供了创新的解决方案,标志着类脑智能研究取得了突破性进展。
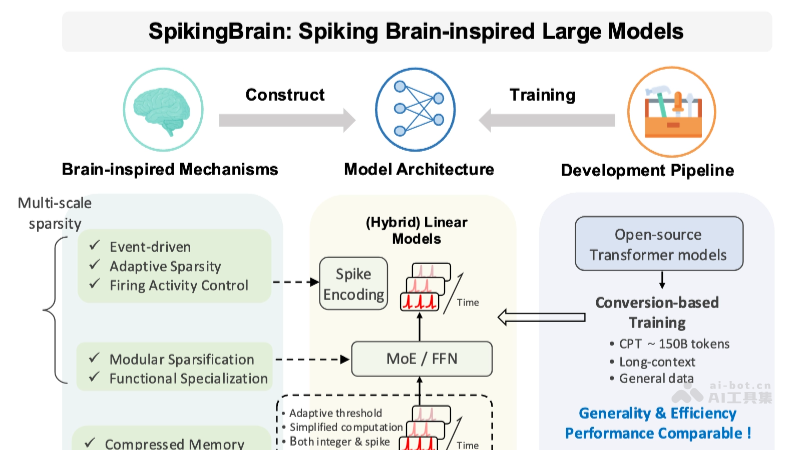
SpikingBrain-1.0的核心在于其独特的类脑脉冲神经网络(SNN)设计和非Transformer架构。与传统的连续值激活神经网络不同,SNN通过模拟生物神经元的脉冲信号传递机制,以事件驱动的方式处理信息。这种机制不仅能显著降低能耗,更在处理时间序列数据方面展现出天然的优势。研究表明,生物大脑在处理信息时,其能效比远超现有的人工智能系统,SNN正是受此启发而诞生。
SpikingBrain-1.0的创新技术路径
传统的Transformer模型,尽管在众多任务中表现出色,但其自注意力机制的二次复杂度(O(N^2))使其在处理动辄数十万甚至上百万token的超长序列时,计算成本和内存需求呈指数级增长。这使得Transformer在长文本理解、长语音识别等任务中往往力不从心,或需借助复杂的近似方法。
SpikingBrain-1.0则巧妙地避开了这一瓶颈,其新型非Transformer架构通过更高效的连接方式和信息传递机制,使得模型在超长序列处理上展现出显著的性能提升。这种“内生复杂性”的设计理念,使得模型能够通过神经元之间的动态交互和自适应调整,在处理复杂信息时保持高效率和低能耗。具体而言,它可能采用了如循环连接、稀疏连接或门控机制等,以更接近生物大脑的方式进行信息处理和记忆。
卓越性能与核心优势
SpikingBrain-1.0的问世,带来了多项令人瞩目的核心优势:
- 超长序列处理能力:这是SpikingBrain-1.0最突出的特点。它能够高效处理远超传统模型极限的超长序列数据,例如数小时的语音记录、数十万字的长篇文档或长期时间序列数据。这意味着在处理复杂语境、理解长篇报告和预测长期趋势方面,该模型具备独特的竞争力。
- 极低数据量高效训练:在现实世界中,高质量的标注数据往往稀缺且昂贵。SpikingBrain-1.0在极低数据量下也能进行高效训练,这大大降低了模型训练的门槛和成本。这一特性使其在数据受限的垂直领域,如小语种翻译、专业医疗文本分析等,具有巨大的应用潜力。
- 推理效率数量级提升:SNN的事件驱动特性使得模型在推理阶段仅在必要时才激活神经元,从而显著降低了计算量和能耗。SpikingBrain-1.0在推理效率上的数量级提升,使其非常适合大规模部署和对实时性要求极高的应用场景,例如智能客服的即时响应、自动驾驶的实时决策等。
- 国产自主可控生态构建:值得一提的是,SpikingBrain-1.0的全流程训练和推理均在国产GPU算力平台上完成。这不仅验证了国产硬件的强大性能,更为我国构建自主可控的类脑大模型生态系统奠定了坚实基础,有效规避了潜在的技术壁垒和供应链风险。
技术原理的深度解析
SpikingBrain-1.0之所以能实现这些突破,离不开其深厚的技术根基:
- 类脑脉冲神经网络(SNN):SNN是其核心。它通过模拟生物神经元膜电位累积和脉冲发放的机制,将信息编码为时间序列上的稀疏脉冲。这种编码方式使得SNN能够更自然地处理时序信息,并具有更高的能量效率。例如,当处理一段语音时,SNN不是像传统神经网络那样连续处理波形,而是响应语音中关键的声学事件,以脉冲形式传递信息。
- 新型非Transformer架构:该架构放弃了Transformer固有的全连接自注意力机制,转而采用一种更具生物合理性的连接模式。这可能包括稀疏注意力、局部连接、或者基于事件触发的动态连接权重等,从而在保持对长距离依赖建模能力的同时,显著降低了计算复杂度和内存占用。
- 内生复杂性:这是指模型并非通过简单堆叠层数来增加能力,而是通过神经元之间精巧的动态交互和自适应调整机制,自发涌现出复杂的处理能力。这种设计使得模型在面对新环境和新任务时,能够表现出更强的鲁棒性和泛化能力。
- 国产GPU算力:在国产GPU平台上完成训练和推理,不仅是技术上的验证,更是战略上的布局。这确保了从底层硬件到上层模型的全面自主可控,为国家人工智能产业的安全发展提供了有力保障。
广阔的应用前景与案例分析
SpikingBrain-1.0的这些技术优势,使其在多个领域展现出巨大的应用潜力,有望解决当前AI应用中的诸多痛点:
- 自然语言处理(NLP):在智能客服场景中,SpikingBrain-1.0可以高效理解和处理用户提供的长篇咨询或历史对话记录,准确捕捉用户意图,提供更精准的回答。例如,在保险理赔咨询中,它能综合分析数千字的保单条款、事故报告和用户陈述,快速识别关键信息。
- 语音处理:在智能语音助手和会议系统领域,SpikingBrain-1.0能够准确识别长时间的语音指令或会议对话内容,即使在复杂的语境下也能保持高识别率。它能有效处理口音、语速变化以及多说话人场景下的语音信息,提升交互体验。
- 金融科技:在风险评估和市场预测环节,SpikingBrain-1.0能够分析数年甚至数十年的金融数据,包括交易记录、新闻舆情、宏观经济指标等超长序列信息,为投资决策提供更深入、更全面的支持。例如,通过分析企业多年财报和市场情绪数据,更准确预测股价波动。
- 智能交通:交通流量预测是智能交通管理的核心。SpikingBrain-1.0可以分析长周期的交通流量、天气、事件等数据,实现对未来交通状况的精准预测,优化交通信号灯控制,缓解城市拥堵。
- 医疗健康:在疾病诊断过程中,SpikingBrain-1.0能够整合患者长期的电子病历、基因组数据、生理监测数据等多模态信息,辅助医生进行早期疾病诊断、个性化治疗方案制定以及预后评估。例如,分析患者多年的体检报告和用药记录,发现潜在的健康风险。
SpikingBrain-1.0的推出,无疑为人工智能领域注入了新的活力,尤其是在解决超长序列处理这一普遍难题上提供了突破性思路。其类脑架构和高效特性,不仅提升了AI系统的实用性,也为构建更加节能、智能、自主可控的未来AI生态奠定了坚实的基础。随着技术的不断演进和完善,我们有理由相信,类脑脉冲大模型将在更多应用场景中发挥关键作用,推动人工智能迈向更高的发展阶段。

