
在 AI 技术日新月异的今天,AI 代码生成能力一直是业界关注的焦点。近日,OpenAI 再次出手,开源了全新的代码能力测试基准——SWE-Lancer。这个基准测试不同于以往的“单题考核”,而是直接用真实项目任务来评估 AI 的代码能力,堪称“百万美元级”的代码测试。
那么,SWE-Lancer 究竟有何特别之处?它对 AI 代码能力的发展又意味着什么?让我们一起来揭开它的神秘面纱。
SWE-Lancer:更贴近真实开发的 AI 代码能力测试
SWE-Lancer 的最大特点在于其“真实性”。它直接采用了来自 Upwork 平台的 1400 多个自由职业者任务,每个任务平均需要自由职业者 21 天以上才能完成。这些任务加起来价值 100 万美元,涵盖了软件开发的各个方面。
与传统的代码能力测试相比,SWE-Lancer 具有以下几个显著优势:
- 端到端测试: SWE-Lancer 采用端到端测试的方式,模拟真实用户操作整个系统,评估 AI 在完整工作流程中的表现。
- 真实项目任务: SWE-Lancer 的任务来自真实项目,涵盖了各种技术栈和问题类型,更能反映 AI 在实际开发中的能力。
- 全面评估: SWE-Lancer 不仅测试 AI 的代码生成能力,还评估其在软件工程管理方面的能力,如问题分析、方案选择等。
- 引入用户工具模块: SWE-Lancer测试中让AI能在本地运行应用,像真人一样操作软件。
SWE-Lancer 数据集:真实、多样、有挑战性
SWE-Lancer 数据集包含了 1488 个真实项目任务,分为两大类:
- 独立开发任务(764 个,价值 41 万美元): 这类任务要求 AI 独立完成代码编写、bug 修复等开发工作。测试时,AI 会获得问题的详细描述、重现步骤、问题发生前的代码以及预期达到的效果。
- 管理任务(724 个,价值 58 万美元): 这类任务要求 AI 充当项目经理的角色,从多个提案中选择最佳解决方案。例如,当需要为 iOS 应用添加图片粘贴功能时,AI 需要判断哪个实现方案更合适。
这些任务涵盖了应用逻辑、服务器端、UI/UX、系统质量和可靠性等多个方面,对 AI 的代码能力提出了全面的挑战。
SWE-Lancer 测试结果:Claude 3.5 Sonnet 暂时领先,AI 仍有进步空间
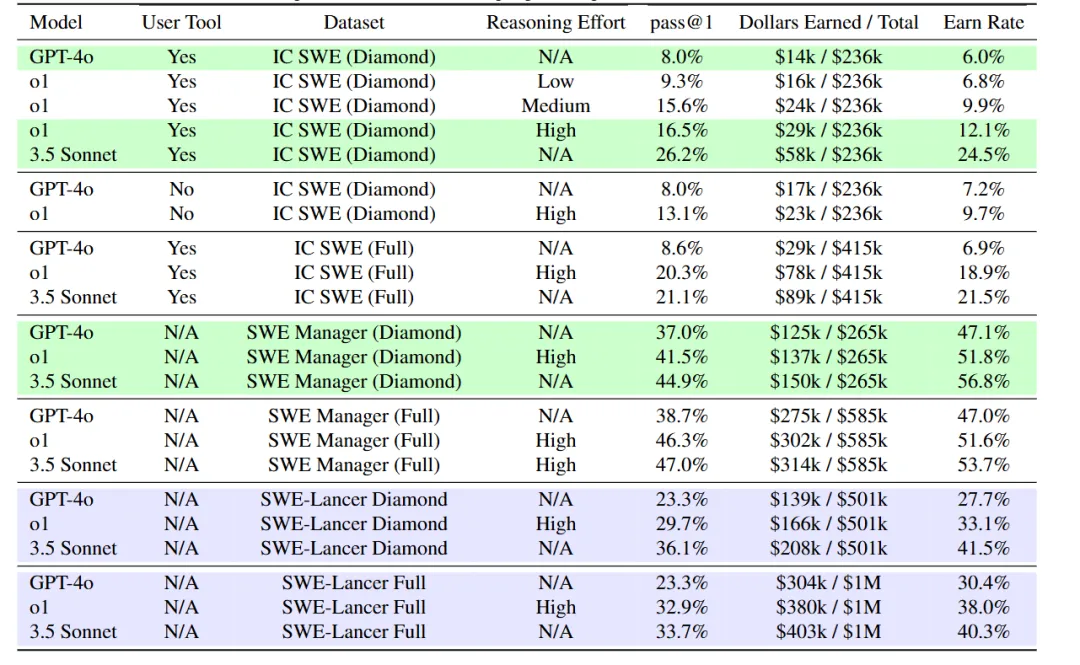
OpenAI 使用 SWE-Lancer 对多个大语言模型进行了测试,结果显示:
- Claude 3.5 Sonnet 表现最佳: 在所有测试模型中,Claude 3.5 Sonnet 表现最好,完成了 26.2% 的开发任务和 44.9% 的软件工程管理任务,总价值约为 40 万美元。
- GPT-4o 和 o1 表现一般: GPT-4o 在开发任务上仅完成了 8%,o1 完成了 20.3%;在管理任务上,GPT-4o 完成了 37%,o1 完成了 46.3%。
- 任务难度影响结果: 任务难度越大,模型完成的正确率越低。价值超过 1000 美元的任务,正确率普遍不到 30%。
从测试结果来看,目前的大语言模型在代码能力方面仍有很大的进步空间。虽然 Claude 3.5 Sonnet 暂时领先,但距离完全胜任真实软件开发工作还有很长的路要走。
SWE-Lancer 的意义:推动 AI 代码能力发展
SWE-Lancer 的发布,对 AI 代码能力的发展具有重要意义:
- 提供更真实的评估标准: SWE-Lancer 采用真实项目任务进行测试,更贴近实际开发场景,能够更准确地评估 AI 的代码能力。
- 促进 AI 模型改进: SWE-Lancer 的测试结果可以帮助开发者发现当前 AI 模型的不足之处,从而有针对性地进行改进。
- 推动 AI 在软件开发领域的应用: SWE-Lancer 为 AI 在软件开发领域的应用提供了参考,有助于推动 AI 程序员的早日“上岗”。
- 为开发者提供了一个比较专业客观且有价值的参考
AI 程序员的未来:机遇与挑战并存
SWE-Lancer 的发布,让我们看到了 AI 程序员的潜力,同时也看到了其面临的挑战。
- 机遇: AI 代码生成技术的发展,有望提高软件开发效率,降低开发成本,让开发者能够更专注于创新性的工作。
- 挑战: 目前的 AI 模型在处理复杂问题、理解上下文、进行系统级思考等方面仍存在不足,距离完全取代人类程序员还有很长的路要走。
未来,随着 AI 技术的不断进步,我们有理由相信,AI 程序员将在软件开发领域发挥越来越重要的作用。
结语
OpenAI 发布的 SWE-Lancer 基准测试,为 AI 代码能力评估提供了一个更真实、更全面的标准。虽然目前的大语言模型在 SWE-Lancer 测试中表现还有待提高,但这并不妨碍我们对 AI 程序员的未来充满期待。
让我们拭目以待,看 AI 代码生成技术将如何改变软件开发的面貌,为我们带来更多的惊喜!








