
近来,国产AI大模型 DeepSeek 的名字可谓是炙手可热,不仅在科技圈内备受关注,甚至连平时不怎么接触 AI 技术的普通大众,也开始在茶余饭后谈论起 DeepSeek 及其创始人梁文峰。这种现象级的影响力,着实令人惊叹。DeepSeek 究竟有何魔力,能够引发如此广泛的关注?它又将对 AI 行业产生怎样的影响?
DeepSeek 的母公司深度求索,背后有着量化私募巨头幻方基金的鼎力支持。这使得 DeepSeek 在资金方面拥有雄厚的实力,能够专注于 AI 技术的研发,不以短期盈利为目标,而是着眼于 AI 领域的长远发展。自 2024 年以来,DeepSeek 陆续发布了多款 AI 大模型,并以开源的方式回馈社区,这种开放的态度赢得了业界的广泛赞誉。
2024 年 5 月,DeepSeek 发布了 DeepSeek-V2,该模型在中文综合能力方面表现出色,堪称开源模型中的佼佼者,能够与 GPT-4-Turbo、文心 4.0 等闭源模型相媲美。在英文综合能力方面,DeepSeek-V2 也达到了与 LLaMA3-70B 相当的水平,甚至超越了 Mixtral8x22B 等 MoE 开源模型。更令人称道的是,DeepSeek-V2 的 API 价格仅为 GPT-4o 的 2.7%,直接引发了国内大模型的价格战,加速了 AI 技术的普及。
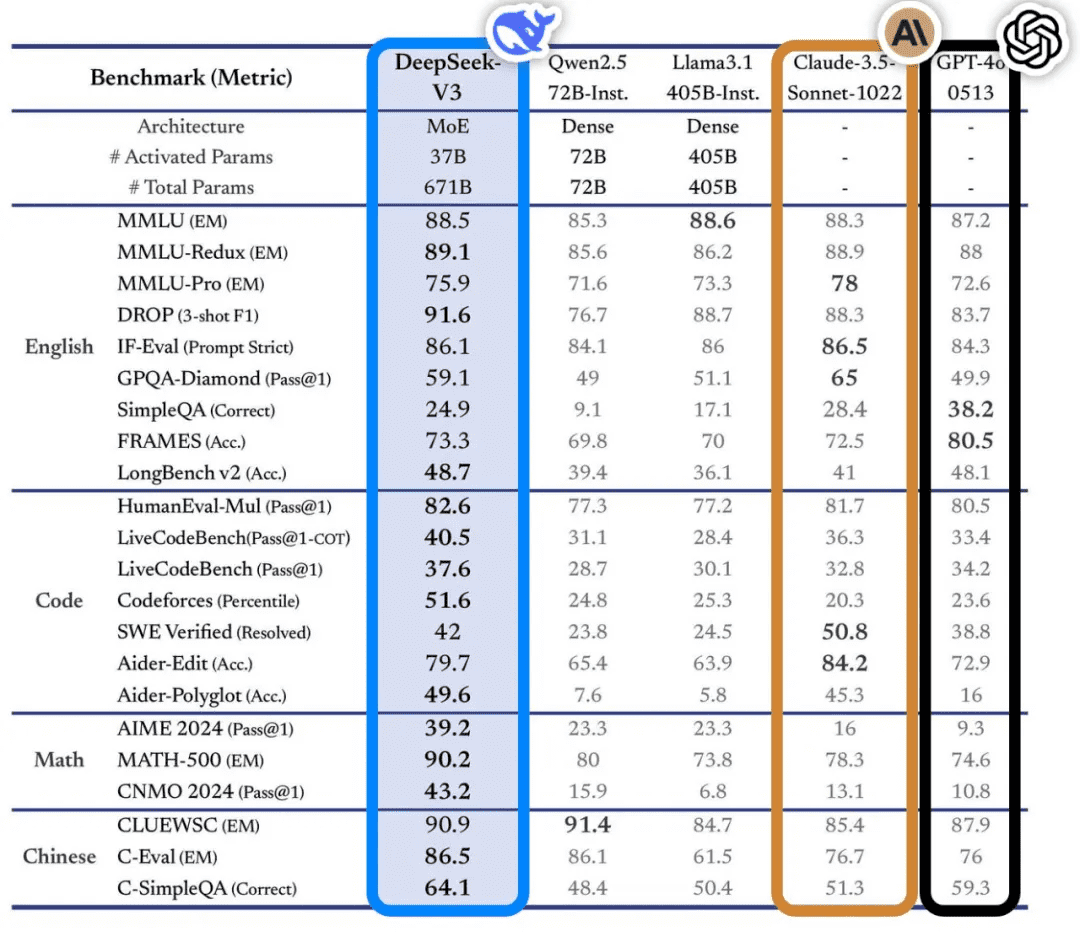
2024 年 12 月,DeepSeek-V3 发布,同样选择了开源。该模型在知识类任务、长文本理解、编程和数学运算等领域表现出色,性能直逼 GPT-4o 和 Claude-3.5-Sonnet 等国际顶尖的闭源模型。更令人惊讶的是,DeepSeek-V3 的训练成本仅为 557.6 万美元,远低于其他大型科技公司的投入,再次证明了 DeepSeek 在技术研发方面的强大实力。
2025 年 1 月,DeepSeek 推出了全新的推理模型 DeepSeek-R1,并继续坚持开源。DeepSeek-R1 的效果堪比 OpenAI o1,而 API 价格仅为 OpenAI o1 的 3.7%,再次震惊海外,进一步巩固了中国 AI 技术在国际上的领先地位。

2025 年 1 月 27 日,DeepSeek 同时登顶苹果中美两区 App 免费榜,超越了长期霸榜的 GPT,引发了投资者对 OpenAI 的担忧,英伟达的股票也随之出现下跌。DeepSeek 的成功,标志着国产 AI 技术正在崛起,对国际 AI 市场格局产生了深远的影响。

然而,DeepSeek 的崛起也引来了一些非议。2025 年 1 月 28 日,DeepSeek 官网显示,其线上服务受到了大规模的恶意攻击,攻击者的 IP 地址均来自美国。此外,美国军方以“安全问题”为由禁止士兵安装使用 DeepSeek,意大利也以同样的理由将其从 Appstore 和谷歌商店下架。这些事件表明,DeepSeek 的发展受到了来自海外的阻力。
尽管如此,DeepSeek 仍然获得了业界的广泛认可。微软、英伟达、亚马逊等云计算平台纷纷接入 DeepSeek,为用户提供更加便捷的 AI 服务。同时,OpenAI 也感受到了来自 DeepSeek 的压力,开始积极寻求新的融资,并推出了 OpenAI o3-mini 系列模型,试图在推理模型领域保持领先地位。

OpenAI 研究科学家 Noam Brown 表示,o3-mini 在多项评估中表现优于 o1,旨在彻底改变成本与智能之间的关系,不断提升模型智能,并降低获得相同智能水平的成本。OpenAI 首次向免费用户开放推理模型的使用权限,用户可以在 ChatGPT 消息输入框下方选择「Reason」按钮即可使用。
o3-mini 集成了搜索功能,能够实时获取最新答案并附带相关网页链接,方便用户进行深度调研。此外,o3-mini 还支持函数调用、结构化输出和开发者消息等高级功能,并支持流式传输。测试显示,o3-mini 的平均响应时间为 7.7 秒,较 o1-mini 的 10.16 秒快了 24%。
尽管 OpenAI 在推理模型领域取得了新的进展,但 o3-mini 在处理一些简单问题时仍然存在不足。例如,它无法正确回答“9.11 和 9.9 哪个大?”、“strawberry 里面有多少个 r?”等问题。相比之下,DeepSeek-R1 以及其他推理模型都可以轻松解决这些问题。
由于近期 DeepSeek 官网流量激增,且受到了大规模的攻击,导致官网访问不稳定。为了让用户更好地体验 DeepSeek 的魅力,IMYAI 网站提供了 DeepSeek 的免费使用服务,用户可以在该网站上无限制地使用 DeepSeek,体验国产 AI 大模型的强大功能。
那么,如何才能更好地使用 DeepSeek-R1 呢?首先需要明确的是,DeepSeek-R1 是一款推理模型,擅长解决数学、代码、逻辑类的问题,不适合用于撰写论文、作文或小说等长文任务。在提问时,需要提供足够的上下文背景资料,并使用自然语言进行交流,避免使用过于结构化的提示词。此外,还需要明确目标,让 AI 能够更好地理解用户的需求。
总而言之,在使用 DeepSeek-R1 时,要将其视为一个能力强大的员工,明确告知其目标,并提供足够的信息,让其能够充分发挥自身的推理能力,从而更好地完成任务。
与其他的推理模型相比,DeepSeek-R1 的文案功底非常出色,能够模仿不同的文笔风格。例如,让 DeepSeek-R1 模仿滕王阁序的风格写一篇蛇年春节的文章,其生成的文案堪称惊艳。

DeepSeek-R1 生成的《癸巳迎春序》文采斐然,令人叹为观止。相比之下,其他的推理模型,如 OpenAI o1、o3-mini、智谱清言-GLM-Zero、月之暗面-kimi-K1、阿里通义千问-QwQ、Gemini-2.0-flash-thinking-exp 等,在文案生成方面都与 DeepSeek-R1 存在一定的差距。
然而,DeepSeek 的未来处境也面临着诸多挑战。作为一家初创 AI 公司,DeepSeek 面临着人才流失的风险,国内外的科技巨头可能会以更高的薪资挖角 DeepSeek 的核心人才。此外,DeepSeek 还面临着来自海外的压力,可能会受到持续的 DDoS 攻击、蒸馏指控、制裁调查等。同时,DeepSeek 还需要应对来自同行的竞争,以及各种黑粉的抹黑。
尽管面临着诸多挑战,DeepSeek 仍然是中国 AI 行业的希望。我们期待 DeepSeek 能够早日度过难关,为中国 AI 技术的发展做出更大的贡献。
路漫漫其修远兮,吾将上下而求索,DeepSeek 加油!








