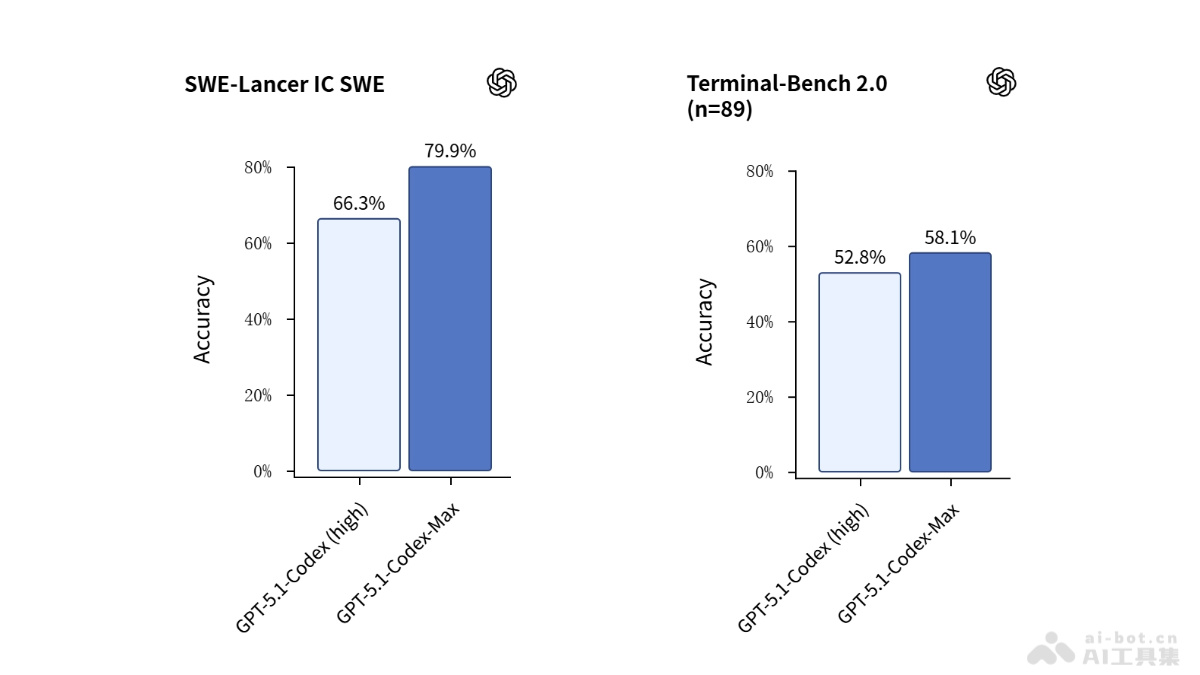
2025年10月,新加坡滨海湾金沙会展中心成为全球金融创新的风向标。Token2049 Singapore 2025这一亚洲最具代表性的行业峰会,吸引了来自160多个国家的25,000多名参会者、300余位演讲嘉宾和500多家参展机构。在这场汇聚金融机构、科技公司、Web3项目及风险管理企业的盛会中,"数字资产通证化(Digital Asset Tokenization,DAT)"无疑是最受瞩目的关键词之一,标志着全球金融体系正在经历一场深刻的数字化转型。
DAT:从概念到基础设施的跨越
数字资产通证化的核心在于将传统资产的权属或份额转化为数字凭证,从而实现更高效的分割、转让与结算。这一过程不仅仅是技术层面的创新,更是对传统金融运作模式的根本性重构。无论是写字楼、基金还是债券,通过DAT技术都可以被"拆分"成更灵活的投资单位,使更多投资者能够参与原本门槛较高的资产类别。
与往年不同,2025年的讨论焦点已从概念验证转向"从试点到基础设施"的实践路径。摩根大通、瑞银、渣打、新加坡交易所等金融巨头纷纷展示其RWA(真实世界资产)项目进展,推动通证化资产在跨境结算、流动性管理及二级市场交易中的实际应用。这一趋势清晰地表明:DAT正在从实验阶段迈入金融体系可监管、可运营的制度化阶段。

全球监管框架:通证化规模化的关键基石
监管共识是通证化能否实现规模化的决定性因素。在本届大会上,新加坡金融管理局(MAS)重申了其对稳定币与通证化资产的监管框架,并宣布将扩大"金融市场基础设施沙盒",以支持资产通证化及跨境结算创新。这一举措为亚洲金融中心在数字资产领域保持领先地位奠定了制度基础。
与此同时,欧洲和阿联酋的代表也指出,MiCA(市场加密资产)等监管体系将进一步为机构探索提供清晰的合规路径。这种全球性的监管协调正在形成,标志着"稳定币合规化"与"通证化可监管化"正在双向并进,共同构筑起全球数字金融的新底座。

制度化进程中的隐忧:身份、合规与跨境治理挑战
尽管DAT的前景广阔,但在其制度化进程中,身份验证、风险管理与合规穿透成为不可回避的挑战:
合规差异:不同司法辖区对通证化资产法律属性的界定存在显著差异,跨境业务尤其复杂,法律适用与权利保护需明确界定。
身份与客户尽职调查的复杂性:DAT交易对身份验证要求更高,要求更高的身份穿透与关系厘清能力,同时需要有效防范洗钱与恐怖融资风险。
伪造与欺诈风险:虚假材料、身份冒用或高级伪造技术,可能对资产安全构成严重威胁。
监管碎片化:跨境流动中的法律适用与监管协同性问题,增加了合规成本与运营难度。
正如多位行业专家所指出:"如果说通证化为资产赋予了新的生命,那么合规与身份验证就是它能否健康成长的基石。"
AI技术:构建数字信任的护城河
面对上述挑战,行业普遍认为AI与合规科技将成为通证化生态的关键底座:
强化身份识别能力:AI驱动的身份验证、行为模式检测与关联分析,显著提升了客户尽职调查的效率与精准度,使金融机构能够在海量交易中快速识别潜在风险。
防伪与真伪鉴别:3D活体检测、文件真伪识别与深度伪造检测技术的应用,有效降低了身份欺诈与材料伪造的风险,为数字资产交易提供了安全保障。
风险识别与实时建模:结合大数据的实时风控模型可帮助机构快速识别异常交易与可疑资金流向,实现风险的提前预警与干预。
合规流程自动化:AI技术能够辅助金融机构在多地复杂法规下保持透明、合规运营,大幅降低合规成本的同时提高监管效率。

ADVANCE.AI:以AI重塑全球数字信任
作为全球领先的人工智能与金融科技企业,ADVANCE.AI在本次Token2049上展示了其在数字身份验证、KYC/KYB解决方案、合规管理、风险控制及信用信息服务领域的创新成果。目前已与银行、金融服务、金融科技、跨境支付、交易平台、零售和电商等多个行业客户建立深度合作,业务遍及全球六大洲,覆盖200多个国家和地区。
在本次活动中,ADVANCE.AI洞察到行业发展的新变化:"过去几年,行业关注的是链上效率;而现在,全球市场更关注'链上身份'与'信任基建'。未来,竞争的核心将是身份验证的可信度与跨境合规的可持续性。而AI将成为未来Web3生态的关键驱动力,帮助企业在创新与监管之间找到平衡,让信任成为数字金融的核心生产力。"

未来展望:Web3的"合规+信任+智能"新阶段
Token2049不仅是一场关于Web3与金融科技的盛会,更是一场关于全球信任体系重构的对话。随着Web3从去中心化叙事走向制度化、智能化,身份安全与合规科技正成为连接金融与技术的关键枢纽。
在这一转型过程中,以下几个趋势尤为值得关注:
监管科技与金融科技的深度融合:随着监管框架的成熟,合规科技将从成本中心转变为价值创造中心,为金融机构提供竞争优势。
跨境合规标准化:随着MiCA等全球性监管框架的推广,跨境合规将逐渐标准化,降低机构进入国际市场的门槛。
AI驱动的动态风险管理:基于AI的实时风险评估将成为标准配置,使金融机构能够更精准地管理通证化资产的各类风险。
身份互操作性突破:不同身份验证系统之间的互操作性将得到显著提升,实现"一次验证,全球通行"的便捷体验。
通证化资产的多元化应用:从房地产、艺术品到碳信用,通证化资产的应用场景将持续扩展,创造新的价值捕获机制。

结语
数字资产通证化(DAT)正在重塑全球金融格局,从概念验证迈入制度化阶段。在这一进程中,监管框架的完善、AI技术的应用以及信任体系的构建将成为关键驱动力。随着摩根大通、瑞银等金融机构加速布局,DAT正成为连接传统金融与Web3生态的重要桥梁。
未来,能够以AI和数据智能为底座,构建可信身份、强化风险防控、实现跨境合规的机构,将逐步成为数字金融新周期的信任引擎。Web3的发展将不再仅限于去中心化技术,而是进入"合规+信任+智能"并重的新阶段,为全球金融体系带来更加高效、透明和包容的创新。