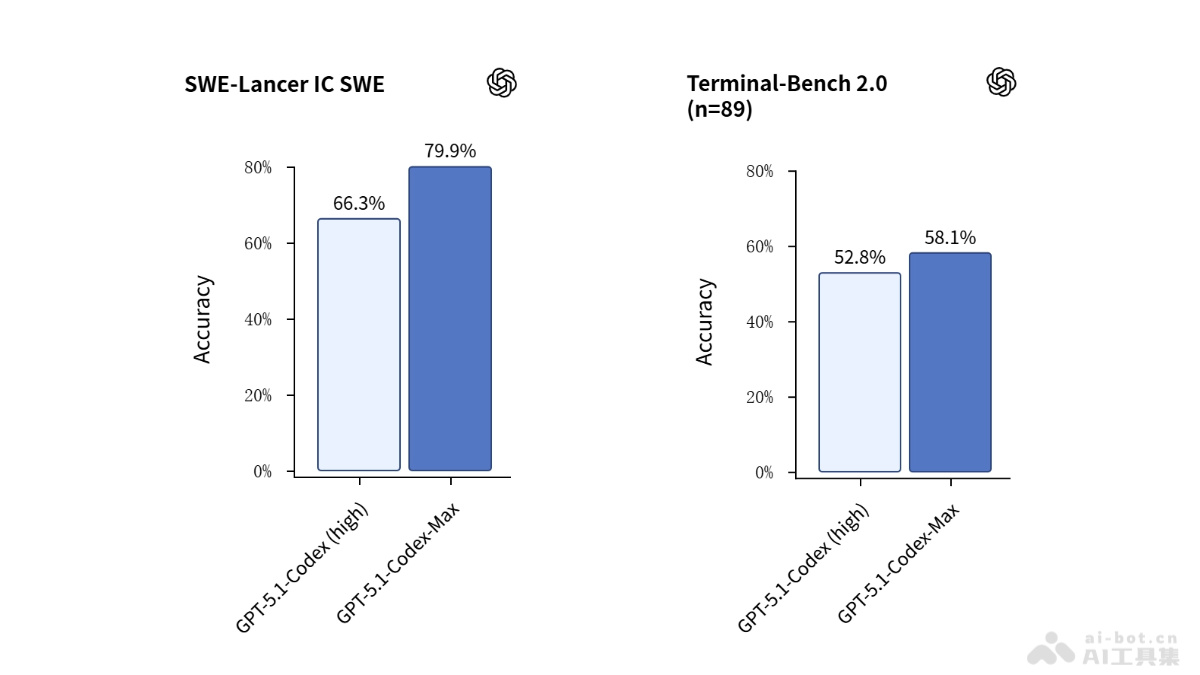
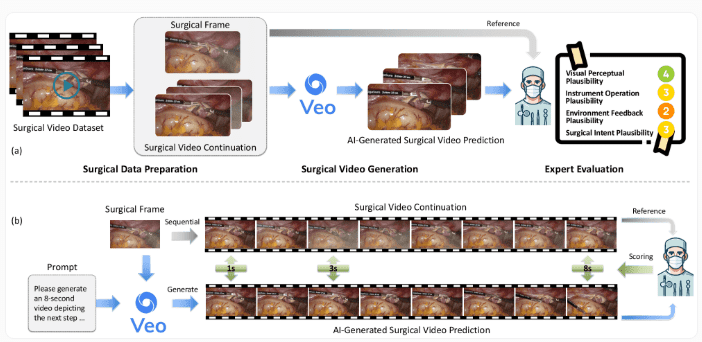
在航天领域竞争日益激烈的今天,Stoke Space公司正以激进的方式挑战行业传统,专注于解决火箭复用这一核心问题。这家成立于2019年的初创企业,虽然规模不大,但其雄心和创新能力却足以撼动整个航天产业格局。本文将深入探讨Stoke Space的技术路线、商业模式及其对航天产业的深远影响。
为什么火箭复用如此重要?
航天发射长期以来一直被视为高成本、低频率的活动。传统火箭大多为一次性使用,每次发射都需要制造全新的火箭,这导致发射成本居高不下,严重限制了太空探索和商业应用的规模。SpaceX通过猎鹰9号火箭的部分复用率先打破了这一局面,但Stoke Space认为,只有实现火箭的完全快速复用,才能真正"移动航天领域的指针"。
"世界真的需要第151家火箭公司吗?"Stoke Space的创始人们经常被问到这个问题。他们的回答是肯定的——但前提是这家公司能够真正解决航天领域的核心瓶颈问题。在众多火箭公司中,Stoke Space选择了一条与众不同的道路,专注于火箭复用的终极目标。
Stoke Space的技术创新

Stoke Space的技术路线体现了大胆的创新思维。与SpaceX的垂直着陆回收不同,Stoke Space采用了一种独特的"水平着陆"方案,这一选择背后有着深刻的技术考量。
液氧甲烷发动机的突破
Stoke Space的"海神"发动机采用了液氧甲烷作为推进剂,这一选择并非偶然。液氧甲烷不仅具有比传统煤油更高的比冲,更重要的是,它燃烧后产生的二氧化碳和水可以在太空中转化为甲烷和氧气,为未来的在轨资源利用提供可能。
"海神"发动机采用了独特的"全流量分级燃烧循环"设计,这种设计能够实现更高的燃烧效率和更稳定的推力输出。与传统发动机相比,"海神"的推力可调节范围更广,能够更好地适应火箭在不同阶段的飞行需求。
火箭回收的独特方案
Stoke Space的火箭回收系统是其技术创新的核心。与SpaceX的垂直着陆不同,Stoke Space的火箭在大气层内采用水平飞行姿态,最终像飞机一样在跑道上着陆。这一方案虽然技术挑战更大,但潜在优势也十分明显:
- 更高的回收可靠性:水平着陆避免了垂直着陆时可能出现的翻转问题
- 更快的周转时间:无需复杂的翻转和重新组装流程
- 更低的维护成本:类似飞机的维护流程,可以利用现有的航空基础设施
智能化控制系统
Stoke Space的火箭配备了先进的智能化控制系统,能够实时分析飞行数据并做出调整。这一系统采用了机器学习算法,能够从每次飞行中学习并优化后续任务。这种"智能火箭"的理念代表了航天技术的未来发展方向。
商业模式与市场策略
Stoke Space的商业战略与其技术创新相辅相成。公司明确表示,不会参与小型卫星发射市场的竞争,而是专注于大型有效载荷的发射服务。
目标市场定位
Stoke Space瞄准的是高价值的政府合同和商业卫星发射市场。这一选择基于对市场需求的深入分析:随着卫星星座和深空探测任务的增多,对大型运载工具的需求将持续增长。
成本优势
通过实现火箭的完全快速复用,Stoke Space承诺将发射成本降低到行业平均水平的十分之一以下。这一大胆的预测如果实现,将彻底改变航天经济的计算方式。
合作伙伴关系
Stoke Space积极与航空航天领域的传统企业建立合作关系,如与波音、洛克希德·马丁等公司的合作。这种"新旧结合"的策略既保证了技术的创新性,又确保了工程实践的可靠性。
行业影响与竞争格局
Stoke Space的出现和崛起正在重塑航天产业的竞争格局。虽然SpaceX目前仍是火箭复用领域的领导者,但Stoke Space的技术路线提供了另一种可行的解决方案。
与SpaceX的比较
Stoke Space与SpaceX代表了两种不同的技术哲学:SpaceX采用渐进式创新,逐步改进现有技术;而Stoke Space则追求颠覆性创新,从零开始设计全新的复用系统。这两种路线各有优劣,最终可能在不同应用场景中找到各自的市场定位。
对传统航天企业的冲击
传统航天企业如ULA、Arianespace等正面临着前所未有的挑战。Stoke Space等新兴企业不仅带来了技术创新,还带来了更加灵活的商业模式和更快的决策机制,这些优势在快速变化的航天市场中尤为明显。
投资与融资趋势
航天领域的投资正在从传统的大型企业向创新型初创公司转移。Stoke Space的成功融资案例表明,投资者越来越看好那些能够解决行业核心痛点的创新企业。
挑战与风险
尽管Stoke Space的技术路线充满前景,但公司仍面临着诸多挑战和风险。
技术挑战
火箭复用涉及的技术难题极为复杂,从材料科学到控制系统,从热防护到推进技术,每一个环节都需要突破。Stoke Space的"海神"发动机和水平着陆方案都是未经大规模验证的创新技术,存在较高的技术风险。
市场接受度
新的航天技术往往需要时间获得市场的认可。Stoke Space需要证明其技术路线的可靠性和经济性,才能赢得客户的信任。特别是在政府合同领域,决策过程往往更加保守,创新技术的推广面临更多障碍。
资金压力
航天研发是资本密集型行业,Stoke Space需要持续大量的资金支持。虽然公司已经完成了多轮融资,但实现商业化的道路仍然漫长,资金压力始终存在。
未来展望
Stoke Space的长期目标是建立一个可持续的航天运输系统,不仅能够降低发射成本,还能够支持更复杂的太空任务。公司的愿景是让太空探索和开发成为人类活动的常态,而非常态。
短期目标
在接下来的几年中,Stoke Space计划完成"海神"发动机的全面测试,并进行首次亚轨道飞行测试。这些里程碑事件将是公司技术路线验证的关键步骤。
中期规划
2027-2030年间,Stoke Space计划实现首次轨道飞行并完成火箭回收演示。这一阶段将证明其技术路线的可行性,并为商业化奠定基础。
长期愿景
长期来看,Stoke Space希望实现火箭的快速复用,将发射间隔缩短至几天甚至几小时。这一目标如果实现,将彻底改变太空经济的计算方式,为大规模太空开发铺平道路。
结论
Stoke Space代表了航天创新的新方向——专注于解决核心问题,而非追求短期市场机会。通过大胆的技术创新和清晰的市场定位,这家初创企业正在挑战航天产业的传统格局。虽然前路充满挑战,但Stoke Space的愿景和技术路线确实有可能"移动航天领域的指针",推动人类进入太空探索的新时代。
在众多火箭公司中,Stoke Space的独特之处在于其专注和坚持。面对"世界是否需要第151家火箭公司"的质疑,公司的回答是肯定的——但前提是这家公司能够真正解决航天领域的核心问题。Stoke Space正在用行动证明,它正是这样一家公司。