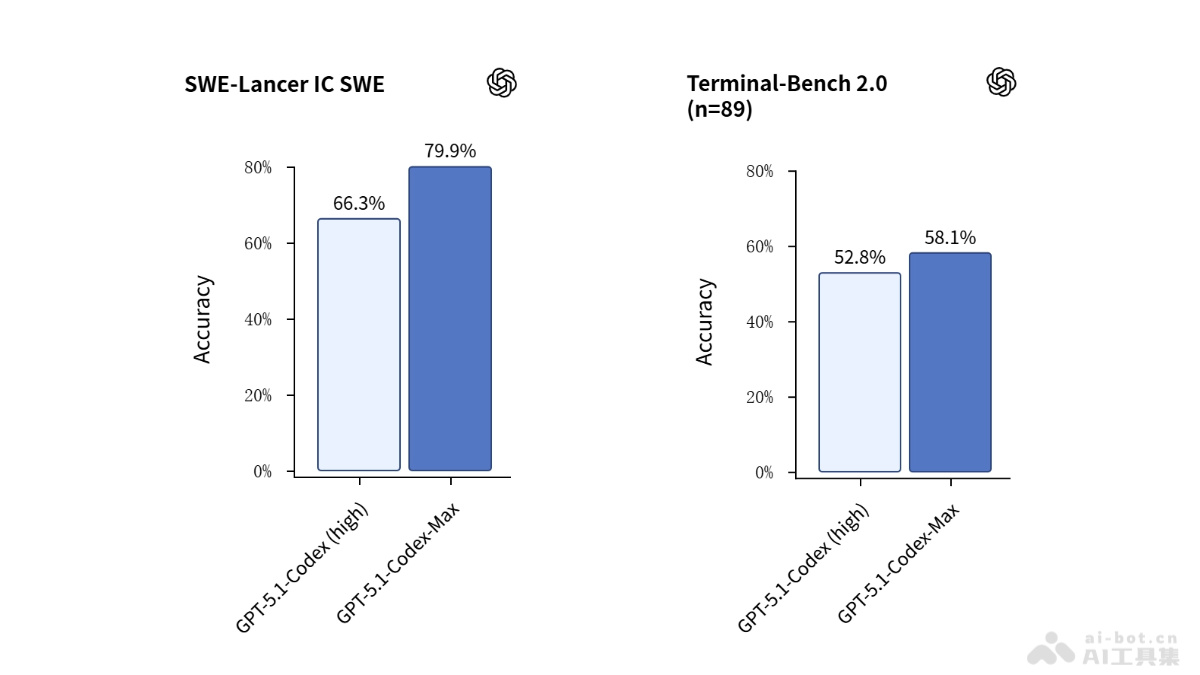
科技巨头谷歌近日被传计划在印度洋的圣诞岛建设大型AI数据中心,引发广泛关注。然而,谷歌随后否认了这一说法,澄清该项目实际上专注于海底基础设施,而非军事或AI相关设施。
争议起源:AI数据中心传闻
11月7日,路透社报道称谷歌计划在圣诞岛建设大型AI数据中心,这是谷歌与澳大利亚军方云计算协议的一部分。该报道将这一设施定位为先进的AI基础设施,位于军事战略家认为对监测中国海军活动至关重要的位置。
圣诞岛是印度洋上澳大利亚的一块领地,面积52平方英里,以其独特的生态系统和每年壮观的红蟹迁徙而闻名。这个偏远岛屿的战略位置使其成为通信和监测的理想地点。
谷歌官方回应
针对路透社的报道,谷歌迅速作出回应,明确否认了在圣诞岛建设AI数据中心的计划。
"我们并没有在圣诞岛建设'大型人工智能数据中心',"谷歌发言人告诉Ars Technica,"这是澳大利亚连接工作的延续,旨在提供海底电缆基础设施,我们期待很快分享更多细节。"
尽管谷歌否认了相关指控,路透社并未撤回其报道,并表示已审查了谷歌在圣诞岛建设数据中心的文件。双方各执一词,使得这一事件更加引人关注。
谷歌的真实计划:海底电缆网络
谷歌公开确认的是,2024年11月,公司宣布了澳大利亚连接计划(Australia Connect),该计划专注于海底电缆基础设施,以改善印度洋-太平洋地区的数字连接。
这一努力的核心是Bosun海底电缆,将连接澳大利亚达尔文与圣诞岛,并延伸至新加坡。根据谷歌的公告,Bosun命名来源于圣诞岛的标志性鸟类白尾热带鸟(White-tailed Tropicbird)和航海术语中船只的甲板水手(bosun)。

圣诞岛以其每年超过1亿只红蟹迁徙而闻名,这一自然奇观吸引了全球自然爱好者和科学家的目光。
此外,谷歌还将建设一条额外的互联电缆,连接墨尔本、珀斯和圣诞岛,在整个地区创建新的数字通道。
谷歌还与Vocus等合作伙伴合作,提供连接达尔文至阳光海岸的陆地光纤对,这将把Bosun电缆与美国、澳大利亚和斐济相连的Tabua海底电缆系统连接起来。
圣诞岛:红蟹的世界
除了其在通信方面的潜在战略位置外,圣诞岛还以其每年壮观的红蟹迁徙而闻名。每年,超过1亿只红蟹会穿越岛屿前往海洋产卵。

圣诞岛的红蟹迁徙规模宏大,每年吸引无数游客和自然爱好者前来观赏这一自然奇观。
人工智能无疑是当今的热门话题,但甲壳类动物也在行动。圣诞岛年度红蟹迁徙是一种如此奇妙的自然现象,据称大卫·爱登堡爵士在1990年参观该地时曾将其描述为他 greatest TV moments 之一。
每年,数百万只红蟹从森林中涌出,穿越道路、溪流、岩石和海滩到达海洋,每只雌蟹可产下多达10万枚卵。幸存下来的小螃蟹需要大约9天时间返回内陆高原的安全地带。
环境考量与螃蟹保护
虽然谷歌正在寻求为其海底电缆建设获得环保批准,但时机对圣诞岛最著名的居民来说可能很微妙。根据澳大利亚国家公园(Parks Australia)的数据,圣诞岛2025年的年度红蟹迁徙已经开始,预计在11月15-16日左右进行主要产卵活动。
在迁徙高峰期,随着螃蟹在森林和海洋之间移动,道路部分区域会随时关闭,岛屿还建造了特殊的螃蟹桥梁以保护迁徙的螃蟹群。
澳大利亚国家公园指出,虽然迁徙每年都会发生,但大多数年份里很少有幼蟹能从海洋安全返回森林,因为它们经常被鱼、鳐鱼和鲸鲨捕食。只有每十年发生一两次的成功迁徙(当大量幼蟹实际存活时)对于维持岛屿的红蟹种群至关重要。
谷歌的海底电缆基础设施如何与1亿只行进的甲壳类动物共存还有待观察,但据报道已采取环境预防措施。从年度迁徙事件的规模来看,很明显这是螃蟹的世界,我们只是生活在其中。
战略意义与地缘政治
圣诞岛位于印度洋中心,距离澳大利亚大陆约2600公里,距离印尼爪哇岛约500公里。这一战略位置使其成为通信和监测的理想地点,特别是在印太地区地缘政治紧张的背景下。

圣诞岛的地理位置使其在印度洋-太平洋地区具有重要的战略价值。
谷歌在该地区的海底电缆投资不仅具有商业意义,也可能对区域数字基础设施产生深远影响。随着全球对数字连接需求的不断增长,海底电缆已成为国家间技术竞争的关键领域。
科技与自然的平衡
谷歌在圣诞岛的项目引发了一个重要问题:科技发展与环境保护如何取得平衡?在这个由螃蟹主导的岛屿上,人类的大型基础设施建设需要特别谨慎地规划。
澳大利亚国家公园已经建立了完善的螃蟹迁徙保护措施,包括临时道路关闭、螃蟹专用通道等。谷歌的项目需要与这些保护措施相协调,确保不会对岛屿脆弱的生态系统造成不可逆转的损害。
未来展望
无论谷歌在圣诞岛的确切计划是什么,这个事件都凸显了科技发展与环境保护之间日益复杂的关系。随着科技公司寻求在全球偏远地区扩展其基础设施,如何平衡商业利益与生态保护将成为一个重要议题。
圣诞岛的红蟹迁徙提醒我们,地球上的许多地方仍然遵循着自然的节律,人类活动需要尊重这些自然规律。在这个由螃蟹主导的小岛上,科技巨头或许需要学会谦卑,承认在某些时候,自然才是真正的主宰者。
结论
谷歌圣诞岛项目的真相仍有待进一步澄清,但可以确定的是,这个被螃蟹"占领"的印度洋小岛将继续吸引全球的关注。无论是海底电缆还是AI数据中心,科技发展都需要在尊重自然的前提下进行。正如圣诞岛的螃蟹所展示的,地球上的许多地方仍然遵循着它们自己的规则,人类只是暂时的访客。