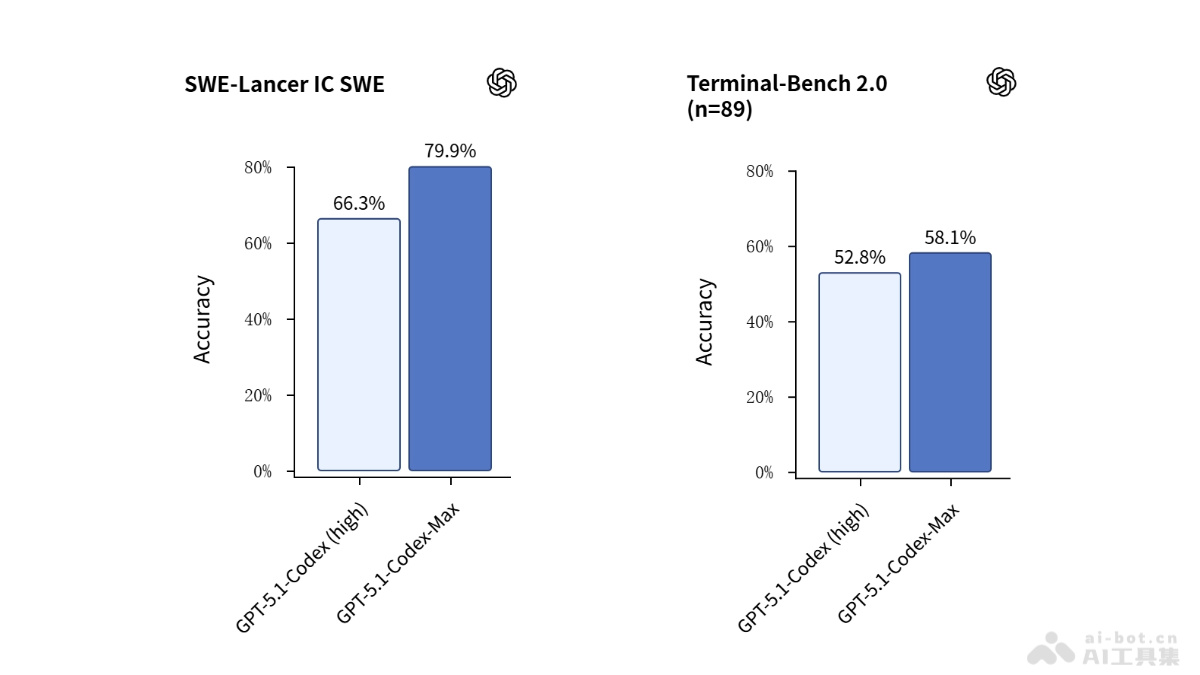
在AI技术日新月异的今天,开发者社区的动态往往预示着行业未来的发展方向。DeepLearning.AI近期举办的AI Dev x NYC 2025大会作为一场售罄的盛会,不仅汇聚了全球顶尖AI开发者,更展现了一个充满活力、技术深度与乐观精神的AI生态。本文将深入剖析这场大会的核心发现,揭示AI开发者群体的技术态度、关注焦点以及对行业未来的展望。
技术前沿:AI代理与上下文工程的新突破
本次大会的技术讨论呈现出明显的聚焦趋势,其中AI代理(Agentic AI)、上下文工程(Context Engineering)和AI治理成为最受关注的话题。这些领域代表了当前AI应用开发的最新方向,也是解决实际业务挑战的关键所在。
在AI代理方面,与会者深入探讨了如何构建能够自主决策和执行任务的智能系统。多位成功实施AI代理案例的团队分享了他们的经验,强调了从简单到复杂逐步构建的重要性。一位来自金融科技公司的开发者表示:"我们的AI代理经历了从单一任务处理到多步骤自主决策的演进过程,关键在于建立清晰的反馈机制和持续优化策略。"
上下文工程则成为提升AI应用效能的核心技术。多位专家指出,随着大语言模型(LLM)能力的不断提升,如何有效管理和利用上下文信息成为决定AI应用性能的关键因素。一位来自领先科技公司的工程师分享道:"我们开发的上下文管理系统使AI应用的准确率提升了37%,这主要归功于我们设计的多层次上下文过滤和动态调整机制。"
乐观主义:开发者社区的坚定信心
尽管外界对AI技术的价值和前景存在诸多质疑,但AI Dev x NYC 2025大会传递出的最强烈信号是开发者社区普遍的乐观态度。这种乐观并非盲目自信,而是基于对技术实际进展的深刻理解和实践经验。
商业价值实现的矛盾现象
大会期间,一个引人深思的现象被多次提及:一方面,许多企业尚未实现AI项目的显著投资回报(ROI),MIT的一项研究甚至指出95%的AI试点项目未能达到预期目标;另一方面,成功实施AI应用的企业正迅速获得显著回报,且成功案例数量呈快速增长趋势。
这种看似矛盾的现象实际上揭示了AI应用正处于从早期采用向规模化过渡的关键阶段。正如一位与会专家所言:"AI技术的商业价值实现遵循典型的S曲线模式——当前我们正处于曲线的拐点附近,虽然整体采用率仍然不高,但领先企业已经开始获得指数级回报。"
技术深度交流的价值
与许多充斥着营销口号的科技会议不同,AI Dev x NYC以其技术深度而备受赞誉。多位参展商表示,这是他们参加过的最有价值的会议,因为与会者具备真正的技术理解力,能够深入讨论前沿技术的细节和挑战。
从代理工作流的可观测性,到AI编码的上下文工程微妙之处,再到强化学习(LLM训练)健身房将持续多久的辩论,每一次讨论都展现了参会者深厚的技术功底。这种深度的技术交流不仅促进了知识共享,更加速了创新思想的碰撞与融合。
治理与伦理:AI发展的人文关怀
在技术讨论之外,AI治理和伦理问题也成为大会的重要议题。特别是在Nick Thompson主持的一场关于AI治理的小组讨论中,与会者就AI发展与社会责任展开了深入交流。
一个特别引人注目的时刻是当讨论触及移民政策对AI发展的影响时。笔者指出,美国近期对移民的敌对言论是阻碍AI发展最严重的因素之一,这一观点获得了现场听众的热烈掌声。这一反应反映了AI开发者群体对开放、多元和包容环境的珍视,以及对人才流动重要性的深刻认识。
AI治理不仅关乎技术规范,更涉及社会价值观和人文关怀。多位与会者强调,AI技术的发展必须以促进人类福祉为前提,这要求开发者在追求技术创新的同时,也要充分考虑其社会影响和伦理 implications。
社区建设:连接与合作的强大力量
AI Dev x NYC大会不仅是一个技术交流平台,更是一个促进社区建设和人脉拓展的绝佳机会。正如笔者在信中所言,正是在上一届旧金山AI Dev大会上,他与Kirsty Tan相识并最终合作创立了AI咨询公司AI Aspire。
这种面对面的交流在数字化时代显得尤为珍贵。尽管远程协作工具日益完善,但实体活动仍然能够提供独特的价值——建立真实的个人连接、激发即兴的创意碰撞、创造难忘的共同体验。这些元素往往成为创新项目和合作关系的催化剂。
行业展望:从当前挑战到未来机遇
基于大会上的讨论和交流,我们可以清晰地看到AI行业正处于一个关键的转折点。尽管面临诸多挑战,但AI开发者们对未来充满信心,这种信心主要基于以下几个观察:
技术成熟度提升:AI代理、上下文工程等关键技术正迅速成熟,为解决复杂问题提供了新的可能性。
成功案例积累:越来越多的企业报告了AI项目的显著成功,这些案例不仅证明了技术的可行性,也为其他企业提供了宝贵的参考。
开发者社区壮大:AI开发者社区持续壮大,知识共享和协作机制日益完善,加速了整体创新进程。
企业认知转变:越来越多的企业开始认识到AI的战略价值,愿意投入资源进行探索和实施。
未来之路:2026年旧金山AI开发者大会前瞻
鉴于AI Dev x NYC 2025的巨大成功,DeepLearning.AI已宣布将于2026年4月28-29日在旧金山举办下一届AI开发者大会,并承诺这将是一场规模更大的盛会。这一决定反映了AI社区持续增长的需求和影响力。
可以预见,下一届大会将继续聚焦技术前沿、行业应用和社区建设,同时可能会更加关注AI的伦理治理、可持续发展和社会责任等议题。随着AI技术的不断演进,开发者社区的角色和责任也将日益凸显,成为推动AI向善发展的重要力量。
结语:技术乐观主义的实践意义
AI Dev x NYC 2025大会传递的最重要信息或许是一种基于技术深度和实践经验的乐观主义。这种乐观主义不是对技术潜力的盲目崇拜,而是对解决实际问题的能力和持续创新可能性的坚定信念。
在AI发展面临诸多挑战和质疑的今天,这种由开发者社区传递出的乐观情绪尤为珍贵。它提醒我们,技术的价值最终体现在解决实际问题上,而开发者正是这一过程的核心推动者。通过持续的技术创新、开放的知识共享和紧密的社区协作,AI开发者们正在共同塑造一个更加智能、更加包容、更加美好的未来。
正如一位与会者在会后分享的感悟:"我们不是在开发AI,我们是在设计未来。"这种使命感或许正是驱动AI开发者们不断前进、持续创新的根本动力。