在人工智能技术飞速发展的今天,Anthropic公司最新发布的Claude Sonnet 4.5模型正在重新定义AI编程能力的边界。这款被官方称为"全球最佳编程模型"的AI系统,不仅在代码生成方面表现出色,更在复杂代理构建、计算机使用能力以及数学推理等领域实现了质的飞跃。本文将深入剖析Claude Sonnet 4.5的技术特点、性能表现及其对AI编程生态系统的深远影响。
革命性的性能提升
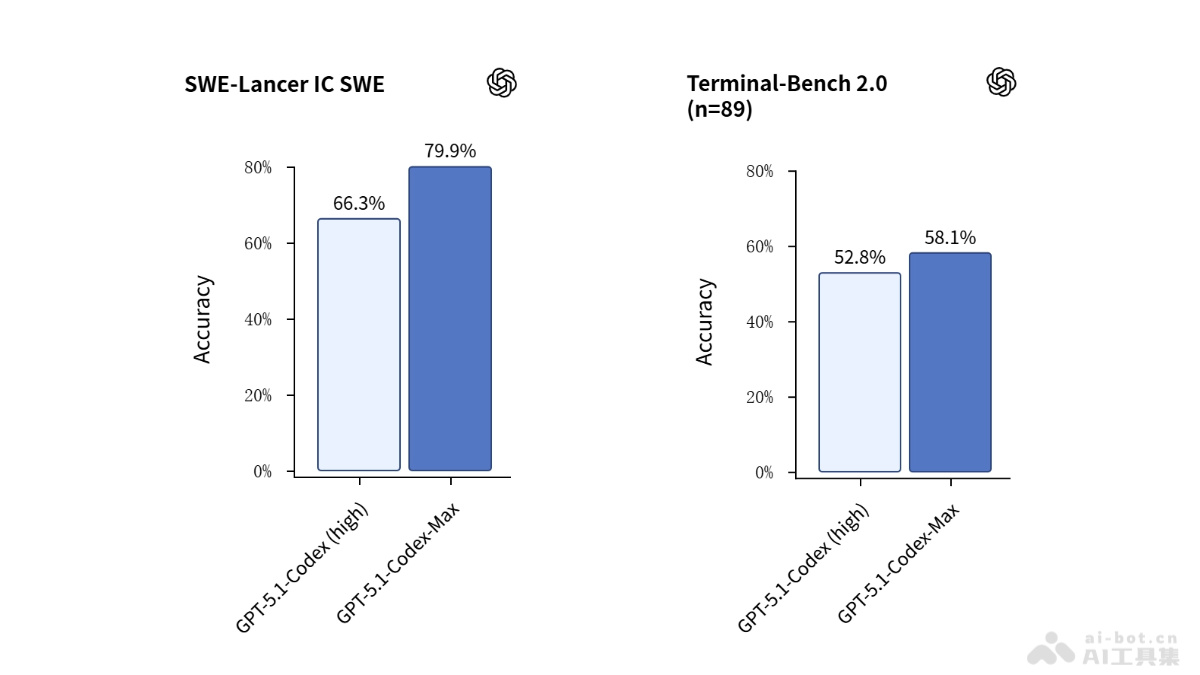
Claude Sonnet 4.5在多个关键评测中展现出前所未有的性能。在SWE-bench Verified这一衡量实际软件编程能力的权威评测中,Sonnet 4.5取得了77.2%的优异成绩,这一成绩是通过在包含500个问题的完整数据集上进行10次试验后得出的平均值。值得注意的是,在采用更复杂的评估方法时,Sonnet 4.5的得分更是达到了惊人的82.0%,这表明其在处理复杂编程任务时具有卓越的适应性和鲁棒性。

更令人印象深刻的是,Claude Sonnet 4.5能够在复杂的多步骤任务中保持超过30小时的专注力。这一特性对于需要长时间运行的复杂软件开发项目具有革命性意义,意味着AI系统可以像人类开发者一样持续工作数天而不中断思路,大大提高了开发效率和质量。
计算机使用能力的质的飞跃
Claude Sonnet 4.5在计算机使用能力方面实现了突破性进展。在OSWorld这一测试AI模型在真实计算机任务表现的基准测试中,Sonnet 4.5以61.4%的准确率领先,而仅仅四个月前,Sonnet 4的领先率仅为42.2%。这短短时间内近20个百分点的提升,反映了模型在理解和操作计算机界面方面的巨大进步。
这种能力的提升在实际应用中表现得尤为明显。通过Claude for Chrome扩展,Sonnet 4.5可以直接在浏览器环境中工作,导航网站、填写电子表格、完成任务,展现出接近人类用户的交互能力。这种能力使得AI系统不再局限于代码生成,而是能够直接操作现有的软件工具,大大扩展了AI的应用场景。
多领域专业知识的深度应用
Claude Sonnet 4.5不仅在编程领域表现出色,还在多个专业领域展现出卓越的知识储备和推理能力。通过对金融、法律、医学和STEM等领域专家的测试,发现Sonnet 4.5在特定领域知识应用方面相比旧模型(包括Opus 4.1)有显著提升。
在金融领域,Sonnet 4.5能够进行复杂的金融分析,包括风险评估、结构化产品设计和投资组合筛选,提供接近投资级别的见解,减少人工审查的需求。在法律领域,模型能够分析完整的简报周期,进行研究,为法官撰写优秀的初步意见草稿,或审阅整个诉讼记录创建详细的即决判决分析。在医学领域,模型展现出对复杂医疗数据的理解和分析能力,辅助医生进行诊断和治疗方案制定。在STEM领域,模型能够处理复杂的科学计算和工程问题,提供精确的解决方案。
实际应用案例与客户反馈
Claude Sonnet 4.5的实际表现已经得到了众多早期客户的高度认可。以下是来自不同行业和组织的真实反馈:
Cursor公司的CEO Michael Truell表示:"我们从Claude Sonnet 4.5看到了最先进的编程性能,在长期任务上有显著改进。这强化了为什么许多使用Cursor的开发者选择Claude来解决他们最复杂的问题。"
GitHub的首席产品官Mario Rodriguez指出:"Claude Sonnet 4.5增强了GitHub Copilot的核心优势。我们的初步评估显示,在多步骤推理和代码理解方面有显著改进,使Copilot的代理体验能够更好地处理复杂、跨代码库的任务。"
GenAI开发者生产力技术负责人Eric Wendelin评价道:"Claude Sonnet 4.5在软件开发任务上表现出色,学习我们的代码库模式以提供精确的实现。它从调试到架构都能处理,具有深厚的上下文理解能力,彻底改变了我们的开发速度。"
Hai安全代理的首席产品官Nidhi Aggarwal分享道:"Claude Sonnet 4.5将我们的Hai安全代理的平均漏洞接收时间减少了44%,同时将准确性提高了25%,帮助我们以信心降低企业风险。"
CoCounsel的副总裁Pablo Arredondo表示:"Claude Sonnet 4.5在最复杂的诉讼任务上处于最先进水平。例如,分析完整的简报周期并进行研究,为法官撰写优秀的初步意见草稿,或审阅整个诉讼记录创建详细的即决判决分析。"
某公司总裁Michele Catasta指出:"Claude Sonnet 4.5的编辑功能非常出色——我们在Sonnet 4上的内部代码编辑基准测试错误率从9%降至0%。在更低成本下实现更高的工具成功率是代理编程的重大飞跃。Claude Sonnet 4.5完美地平衡了创造力和控制力。"
这些来自不同行业和组织的反馈一致表明,Claude Sonnet 4.5在实际应用中确实能够显著提高工作效率、减少错误率,并处理更加复杂的任务。
安全与对齐技术的重大进步
除了性能上的突破,Claude Sonnet 4.5在安全性和对齐技术方面也取得了重大进展。作为Anthropic发布的"最对齐的前沿模型",Sonnet 4.5在多个对齐领域相比之前的Claude模型有显著改进。
模型的行为安全性得到了大幅提升,减少了奉承、欺骗、权力寻求和鼓励妄想思维等令人担忧的行为。对于模型的代理和计算机使用能力,Anthropic也在防御提示注入攻击方面取得了显著进展,这是这些功能用户面临的最严重风险之一。

Claude Sonnet 4.5是在Anthropic的AI安全级别3(ASL-3)保护下发布的,根据其将模型能力与适当保障措施相匹配的框架。这些保障措施包括名为分类器的过滤器,旨在检测潜在的危险输入和输出,特别是与化学、生物、放射性和核(CBRN)武器相关的内容。
值得注意的是,Anthropic已经大幅减少了这些分类器的误报率,自最初描述以来减少了十倍,自5月发布Claude Opus 4以来减少了一半。这种持续的改进确保了安全措施既能有效防止有害内容,又能避免对正常内容的过度干扰。
Claude Agent SDK:赋能开发者
为了使更多开发者能够利用Claude Sonnet 4.5的强大能力,Anthropic正式发布了Claude Agent SDK。这个软件开发工具包是Anthropic用于构建Claude Code的基础设施,现在向所有开发者开放。
Claude Agent SDK包含了Anthropic在过去六个月中为Claude Code开发的解决方案,包括代理如何在长时间运行的任务中管理内存、如何平衡自主性与用户控制的权限系统,以及如何协调为实现共同目标而工作的子代理等复杂问题的解决方案。
通过这个SDK,开发者可以构建自己的AI代理,解决各种不同类型的问题,而不仅仅是编程任务。Anthropic表示,他们构建Claude Code是因为他们想要的工具当时还不存在,而Agent SDK则为开发者提供了构建同样强大功能的工具,以解决他们面临的任何问题。
"Imagine with Claude":创新的研究预览
alongside Claude Sonnet 4.5,Anthropic还发布了一个名为"Imagine with Claude"的临时研究预览。在这个实验中,Claude能够实时生成软件,没有任何预定的功能,也没有预先编写的代码。用户看到的是Claude在实时创建,响应并适应交互过程中的请求。
这个演示展示了Claude Sonnet 4.5的强大能力——展示了将强大的模型与正确的基础设施相结合时可能实现的功能。"Imagine with Claude