人工智能领域再传重磅消息!复旦大学MOSS团队正式推出MOSS-Speech,这一突破性成果标志着国内首个语音到语音(Speech-to-Speech)大模型的诞生,彻底颠覆了传统人机交互需要通过文本作为中介的模式。MOSS-Speech不仅上线了Hugging Face Demo,更同步开源了权重与代码,为整个AI语音技术领域带来了革命性的变化。
革命性架构:层拆分设计实现端到端语音对话
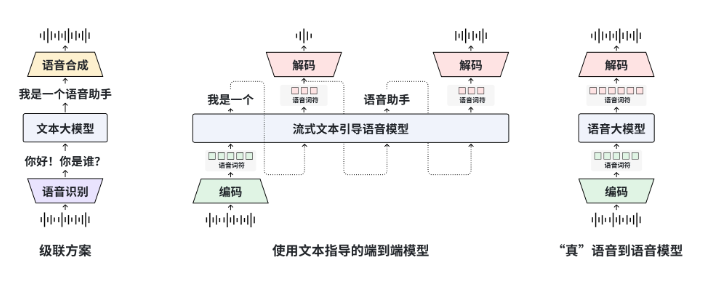
MOSS-Speech最引人注目的创新在于其独特的"层拆分"架构设计。研发团队在原有MOSS文本大模型的基础上进行了巧妙改造:首先冻结了原MOSS文本大模型的参数,确保了模型的知识储备和语言理解能力;然后新增了三层专门针对语音处理的模块——语音理解层、语义对齐层与神经声码器层。
这种架构设计的最大优势在于实现了真正的端到端语音对话能力,无需再依赖传统的ASR(语音识别)→LLM(大语言模型)→TTS(文本转语音)三段式流水线。用户可以直接通过语音提问,MOSS-S能够理解语音内容,生成语义响应,并直接以语音形式输出,整个过程无缝衔接,极大提升了交互的自然性和流畅度。

性能卓越:多项指标超越国际同类产品
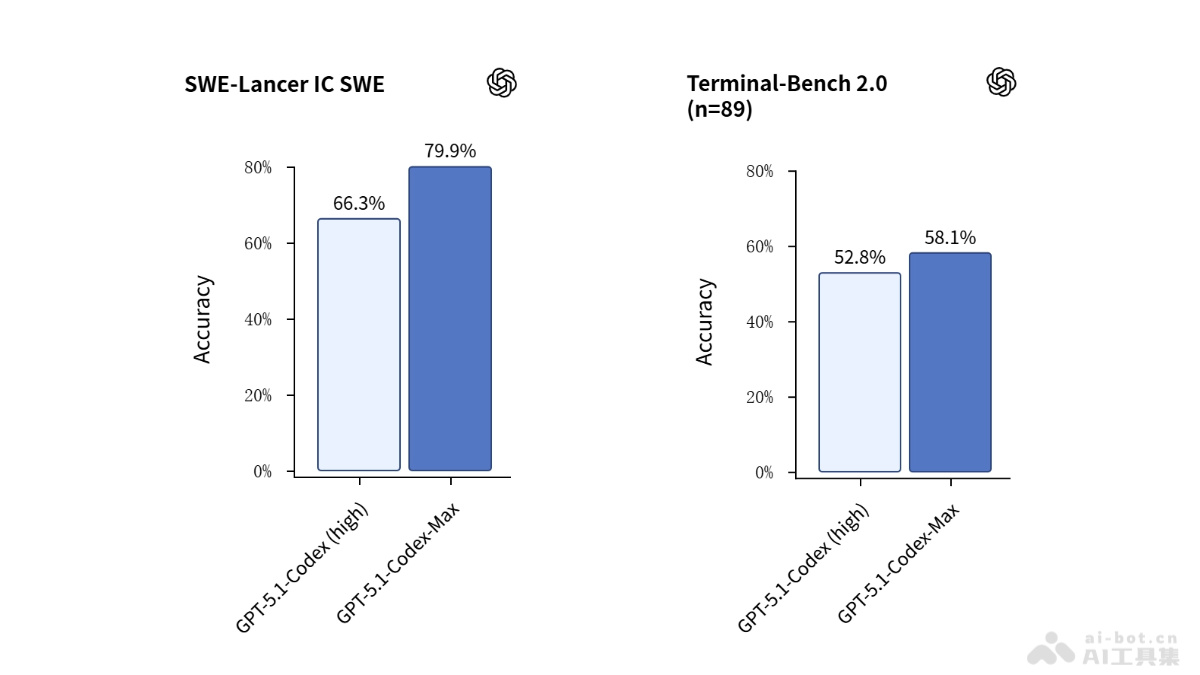
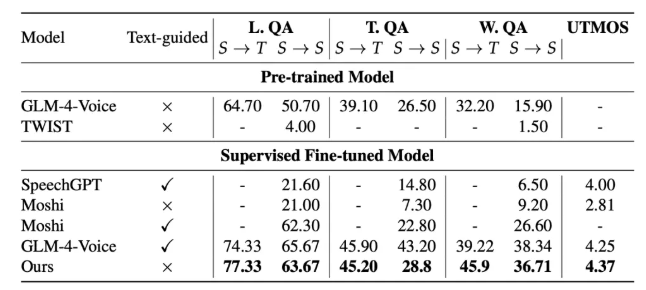
MOSS-Speech在多项关键评测指标上表现出色,甚至超越了国际科技巨头Meta和Google的同类型产品。在ZeroSpeech2025无文本语音任务中,MOSS-Speech的词错误率(WER)降至4.1%,显著低于同类产品;情感识别准确率达到91.2%,展现了出色的情绪理解能力。
特别值得一提的是,在中文口语测试中,MOSS-Speech的主观MOS(平均意见分)达到4.6分,已经非常接近真人录音的4.8分水平。这一数据表明,MOSS-Speech生成的语音不仅自然流畅,而且保留了丰富的情感色彩和语音细节,为用户提供了近乎真实的人机对话体验。
灵活部署:双版本满足不同应用场景需求
考虑到实际应用场景的多样性,MOSS-Speech提供了两个不同版本的模型:48kHz超采样版和16kHz轻量版。48kHz超采样版保留了极高的音频质量,适用于对音质要求极高的专业场景;而16kHz轻量版则针对性能和效率进行了优化,可以在单张RTX4090显卡上实现实时推理,延迟控制在300毫秒以内,非常适合移动端和边缘设备的部署。
这种灵活的版本策略使得MOSS-Speech能够广泛应用于从专业录音棚到智能手机等各种场景,为不同规模的企业和开发者提供了多样化的选择。
商用开放:赋能开发者构建创新语音应用
MOSS-Speech团队宣布,该模型已开放商用许可,这意味着企业和开发者可以在合法合规的前提下,将这一先进的语音技术应用于商业产品和服务中。更为重要的是,团队通过GitHub平台公开了完整的训练与微调脚本,使开发者能够在本地环境中完成私有声音克隆与角色语音化等高级应用。
这一开放策略不仅降低了技术门槛,也为语音AI领域的创新注入了新的活力。开发者可以基于MOSS-Speech构建各种创新应用,如智能客服、虚拟助手、有声内容创作工具等,进一步推动语音技术在各行业的落地应用。
未来展望:语音控制版MOSS-Speech-Ctrl即将发布
MOSS团队透露,下一步计划在2026年第一季度推出"语音控制版"MOSS-Speech-Ctrl。这一新版本将支持通过语音指令动态调整语速、音色与情感强度等参数,为用户提供更加个性化和自然的语音交互体验。
MOSS-Speech-Ctrl的推出将进一步拓展语音技术的应用边界,使语音交互不仅限于内容交流,还能成为控制设备和调整系统参数的有力工具。这种"语音即控制"的理念有望在智能家居、车载系统和专业音频制作等领域带来革命性的变化。
技术意义:推动国内AI语音技术自主创新
MOSS-Speech的发布具有重要的技术意义和行业价值。首先,它代表了国内在语音大模型领域的重要突破,缩小了与国际领先水平的差距,展示了中国AI研究团队的创新能力。其次,MOSS-Speech的开源特性将促进整个语音AI社区的发展,加速技术迭代和应用创新。
从更宏观的角度看,MOSS-Speech的成功研发体现了"基础研究+开源生态"的创新模式。通过将前沿研究成果开源共享,MOSS团队不仅推动了技术进步,也培养了更多的人才,形成了良性循环的发展生态。这种模式对于中国AI技术的自主创新和可持续发展具有重要启示意义。
应用前景:重塑各行各业的人机交互方式
MOSS-Speech的端到端语音能力将为各行各业带来深远影响。在智能客服领域,它可以提供更加自然、情感丰富的对话体验,显著提升用户满意度;在教育培训中,它可以创造沉浸式的语言学习环境,帮助学习者提高口语表达能力;在内容创作领域,它能够实现高效的声音克隆和角色语音化,大幅降低有声内容的制作成本。
特别值得关注的是,MOSS-Speech在医疗健康领域的应用潜力。对于视力障碍人士,它可以提供更加便捷的无障碍交互方式;在心理健康咨询中,它能够识别和响应情绪变化,提供更有温度的支持;在医疗记录方面,它可以实现语音实时转写和结构化存储,提高医护人员的工作效率。
挑战与机遇:语音AI发展的未来之路
尽管MOSS-Speech取得了显著成就,但语音AI领域仍面临诸多挑战。一方面,如何进一步提高语音识别的准确率,特别是在嘈杂环境或方言场景下的表现;另一方面,如何增强模型对复杂语义和语境的理解能力,使对话更加连贯和有逻辑;此外,语音生成在情感表达和个性化定制方面还有很大的提升空间。
然而,挑战与机遇并存。随着计算能力的提升、算法的进步和数据的积累,语音AI技术将不断突破现有局限。MOSS-Speech的出现为国内语音AI发展树立了新的标杆,也为后续研究提供了宝贵的参考和启示。可以预见,在不久的将来,我们将看到更加智能、自然、个性化的语音交互体验。
结语:语音交互新时代的开启
MOSS-Speech的发布不仅是一个技术产品的推出,更是语音交互新时代开启的重要标志。它彻底告别了传统文本中介的束缚,实现了真正意义上的语音到语音对话,为人机交互带来了革命性的变化。
随着技术的不断进步和应用的持续拓展,我们有理由相信,语音将成为未来人机交互的主要方式之一。MOSS-Speech的开源和商用开放策略,将进一步加速这一进程,让先进的语音技术惠及更多用户和行业。在这个语音交互的新时代,MOSS-Speech无疑已经走在了前列,为整个行业树立了新的标杆和方向。