
在自然语言处理(NLP)领域,将文本数据转化为模型可理解的数值形式至关重要。本文将深入探讨Token Embedding(词嵌入)和Positional Encoding(位置编码)这两种关键技术,并结合实际案例,阐述它们在序列数据处理中的作用、矩阵形状关系以及转换过程。
Token Embedding:从离散到连续的映射
Token Embedding是一种将离散的token(例如,单词、字符或子词)映射到连续向量空间的技术。这种映射将每个token表示为一个低维、稠密的向量,向量中的每个元素都代表token的某种语义特征。通过Token Embedding,语义相似的token在向量空间中的距离更近,从而使模型能够捕捉到token之间的语义关系。
以一个简单的例子来说明,假设我们要处理的文本是“猫喜欢吃鱼”。我们可以将每个字作为一个token,构建一个包含“猫”、“喜欢”、“吃”、“鱼”的词汇表。然后,我们可以使用Word2Vec、GloVe或FastText等算法,将每个token映射到一个128维的向量。例如,“猫”可能被映射到向量[0.1, 0.2, ..., 0.3],而“鱼”可能被映射到向量[0.2, 0.3, ..., 0.4]。这两个向量在向量空间中的距离较近,表明“猫”和“鱼”在某种程度上具有语义相关性。
Positional Encoding:为序列注入位置信息
在处理序列数据时,token的顺序至关重要。例如,“我爱你”和“你爱我”表达的含义截然不同。然而,传统的Token Embedding方法无法捕捉到token的位置信息。为了解决这个问题,研究人员提出了Positional Encoding技术。
Positional Encoding通过为每个token的位置生成一个唯一的向量,并将该向量加到token的Embedding向量上,从而将位置信息嵌入到token的表示中。常见的Positional Encoding方法包括基于正弦余弦函数的编码和可学习的编码。
基于正弦余弦函数的编码使用不同频率的正弦和余弦函数来生成位置向量。具体来说,对于位置pos和维度i,位置向量的第i个元素可以表示为:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model)) PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
其中,d_model是Embedding向量的维度。这种编码方式具有以下优点:
- 对于任意两个位置pos+k和pos,PE(pos+k)可以表示为PE(pos)的线性组合,这使得模型能够容易地学习到相对位置关系。
- 正弦和余弦函数的值域在[-1, 1]之间,这使得Positional Encoding的数值范围与Embedding向量的数值范围相近,避免了数值不稳定问题。
可学习的编码则将每个位置都视为一个独立的token,并使用Embedding层来学习每个位置的向量表示。这种编码方式更加灵活,但需要更多的训练数据。
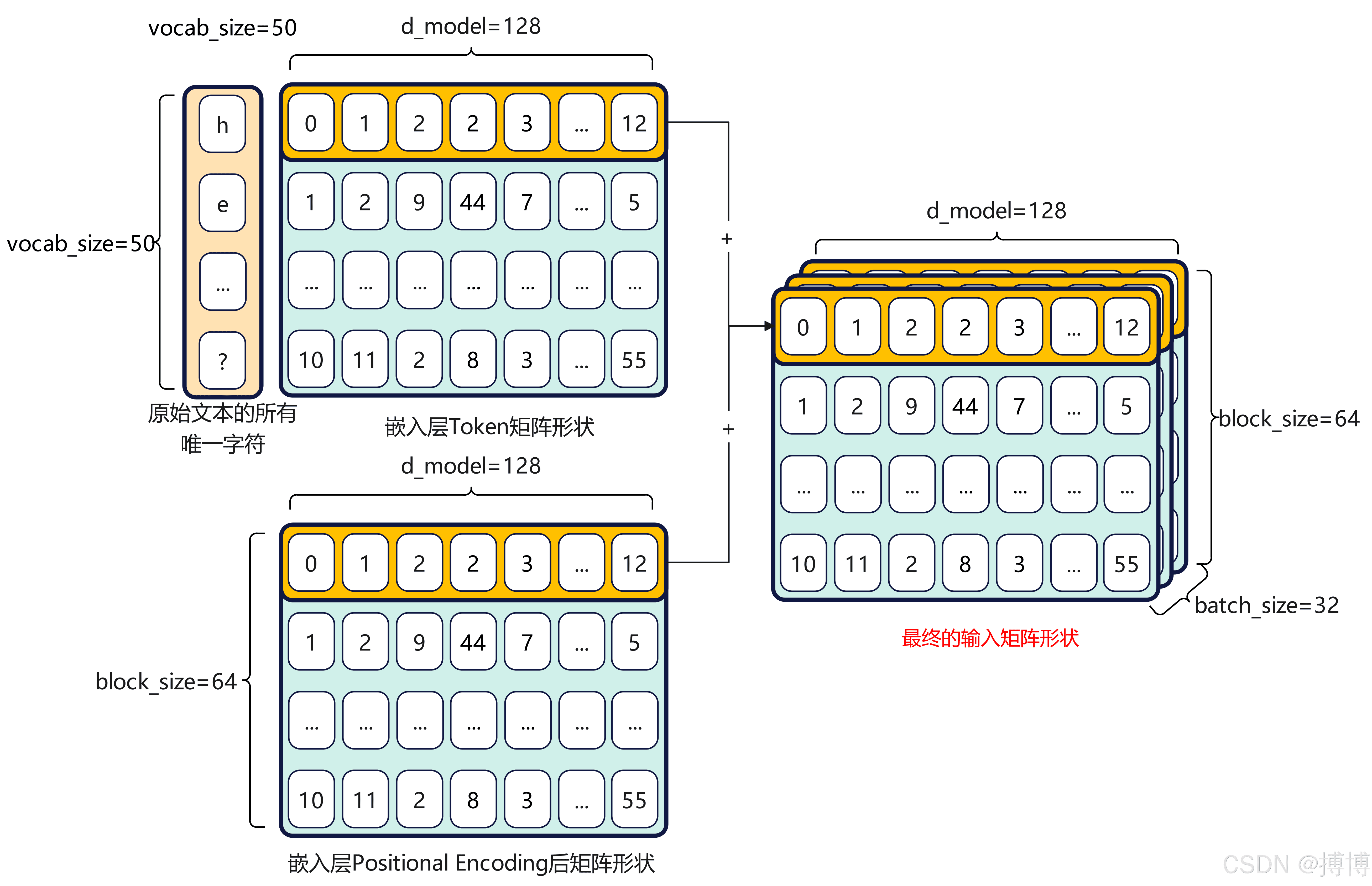
矩阵形状关系及转换过程
假设我们有一个包含N个句子的文本数据集,每个句子包含M个token。首先,我们需要构建一个词汇表,将每个token映射到一个唯一的索引。然后,我们可以将每个句子表示为一个索引序列。例如,句子“猫喜欢吃鱼”可以表示为[1, 2, 3, 4],其中1、2、3、4分别是“猫”、“喜欢”、“吃”、“鱼”在词汇表中的索引。
接下来,我们可以将索引序列转换为Embedding向量序列。假设Embedding向量的维度为d_model,那么每个索引都会被映射到一个d_model维的向量。因此,每个句子都会被表示为一个形状为(M, d_model)的矩阵。
为了将位置信息嵌入到Embedding向量中,我们需要为每个位置生成一个d_model维的位置向量。然后,我们将位置向量加到对应的Embedding向量上。因此,每个句子都会被表示为一个形状为(M, d_model)的矩阵,其中包含了token的语义信息和位置信息。
在实际应用中,我们通常会将多个句子组成一个batch进行处理。假设batch的大小为B,那么输入到模型的矩阵的形状为(B, M, d_model)。
案例分析:基于Transformer的文本分类
Transformer是一种基于自注意力机制的神经网络架构,在NLP领域取得了巨大的成功。Transformer的核心组件是自注意力层,它可以捕捉到序列中不同位置的token之间的依赖关系。为了使Transformer能够处理序列数据,我们需要使用Token Embedding和Positional Encoding将文本数据转换为模型可理解的数值形式。
具体来说,我们可以使用预训练的BERT模型来生成Token Embedding。BERT模型使用Transformer架构进行训练,可以生成高质量的token表示。然后,我们可以使用基于正弦余弦函数的编码来生成Positional Encoding。最后,我们将Token Embedding和Positional Encoding相加,得到输入到Transformer模型的最终表示。
通过使用Token Embedding和Positional Encoding,Transformer模型可以有效地捕捉到文本数据的语义信息和位置信息,从而在文本分类、机器翻译、文本生成等任务中取得优异的表现。
代码示例
以下是一个使用PyTorch实现Token Embedding和Positional Encoding的简单示例:
import torch
import torch.nn as nn
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size, d_model):
super(TokenEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.d_model = d_model
def forward(self, tokens):
return self.embedding(tokens) * torch.sqrt(torch.tensor(self.d_model))
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1), :]
return self.dropout(x)
vocab_size = 10000 # Size of the vocabulary
d_model = 512 # Embedding dimension
max_len = 100 # Maximum sequence length
batch_size = 32 # Batch size
tokens = torch.randint(0, vocab_size, (batch_size, max_len))
token_embedding = TokenEmbedding(vocab_size, d_model)
positional_encoding = PositionalEncoding(d_model, max_len=max_len)
embedded_tokens = token_embedding(tokens)
encoded_tokens = positional_encoding(embedded_tokens)
print(encoded_tokens.shape) # Expected output: torch.Size([32, 100, 512])总结与展望
Token Embedding和Positional Encoding是NLP中两种至关重要的技术。Token Embedding可以将离散的token映射到连续的向量空间,从而捕捉到token之间的语义关系。Positional Encoding可以将位置信息嵌入到token的表示中,从而使模型能够处理序列数据。通过结合使用这两种技术,我们可以将文本数据转换为模型可理解的数值形式,从而在各种NLP任务中取得优异的表现。
随着NLP技术的不断发展,Token Embedding和Positional Encoding也在不断演进。未来的研究方向包括:
- 上下文相关的Embedding:传统的Token Embedding方法为每个token生成一个固定的向量表示,而忽略了token在不同上下文中的语义变化。未来的研究可以探索如何生成上下文相关的Embedding,从而更好地捕捉到token的语义信息。
- 更有效的Positional Encoding:基于正弦余弦函数的编码和可学习的编码都有其局限性。未来的研究可以探索更有效的Positional Encoding方法,从而更好地将位置信息嵌入到token的表示中。
- 结合知识图谱的Embedding:知识图谱包含丰富的实体和关系信息。未来的研究可以探索如何将知识图谱的信息融入到Token Embedding中,从而提高token表示的质量。








