
在互联网产品的坟场里,很少有APP能在被判"死刑"后还能重新杀回舞台中央。然而,多闪这款几乎被遗忘的社交应用,却在不经意间完成了这一壮举。
一、从"消失"到"回春":多闪的逆袭之路
11月18日,极客公园注意到,在App Store中国区免费榜的前六名应用中,有五款来自字节跳动,分别是豆包、红果短剧、抖音商城、多闪和汽水音乐。除豆包外,其余四个应用都属于抖音旗下。
这其中,多闪可能是一个令人意想不到的名字,很多人可能并不熟悉这款社交应用。对于大多数用户而言,"多闪"这个名字属于2019年的那个冬天。彼时,它作为字节跳动首款独立社交产品,带着"围剿微信"的使命高调诞生,却在短暂的高光后迅速陨落,甚至一度被传停止研发。
但现在,这样一款并没有活跃在大众视线里的社交产品,不仅没有消失,反而在一众新贵的夹击下悄然冲榜——在免费总榜单中位列第五名,同时还冲到了App Store社交榜第一名。
1. 排名飙升的时间线
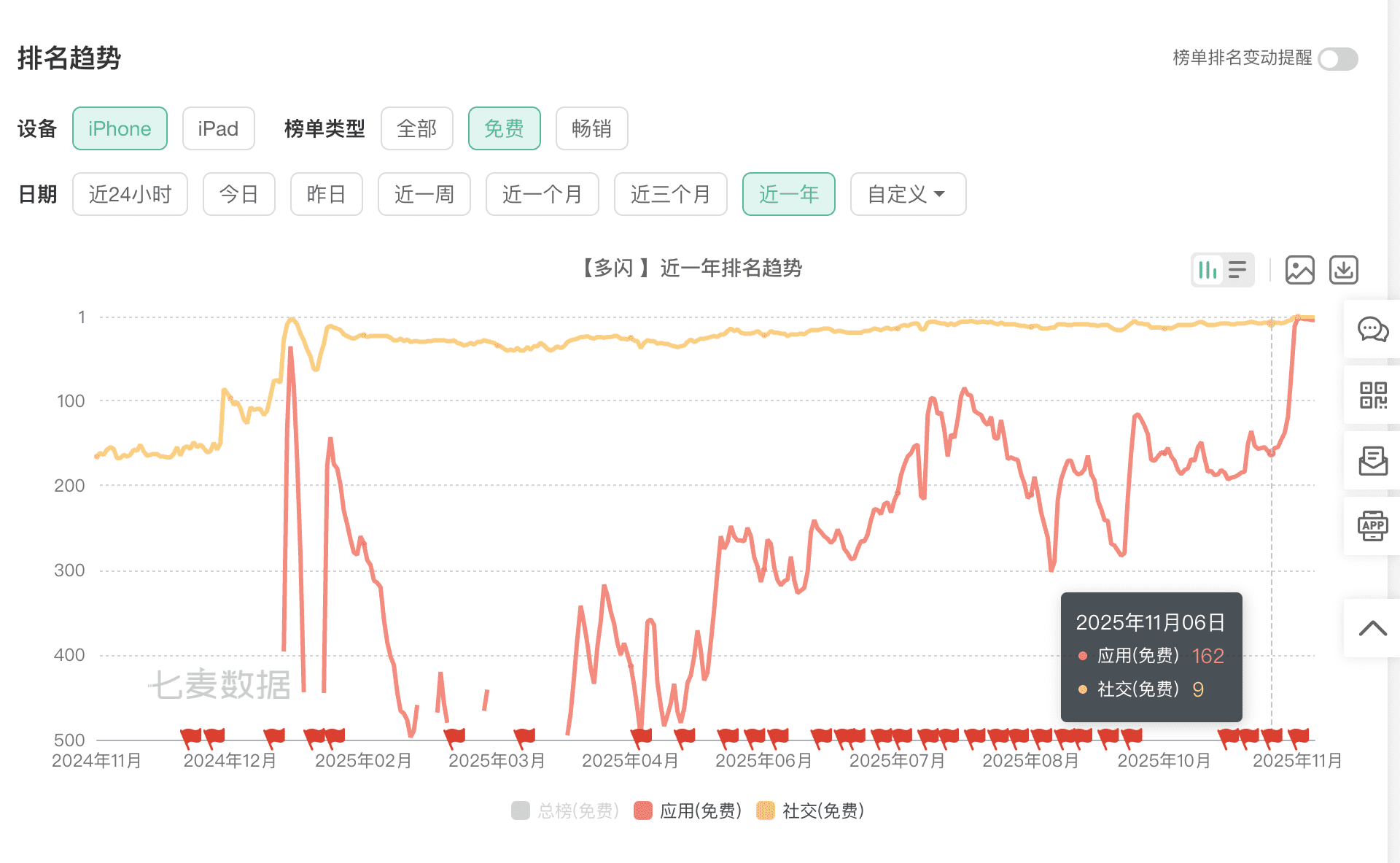
七麦数据显示,多闪在今年年初时,就曾在社交榜冲到第四名,此后一直在这个位置上下徘徊。但在免费总榜里,年初最好的排名也就是36名,而后处于大幅上下波动中。
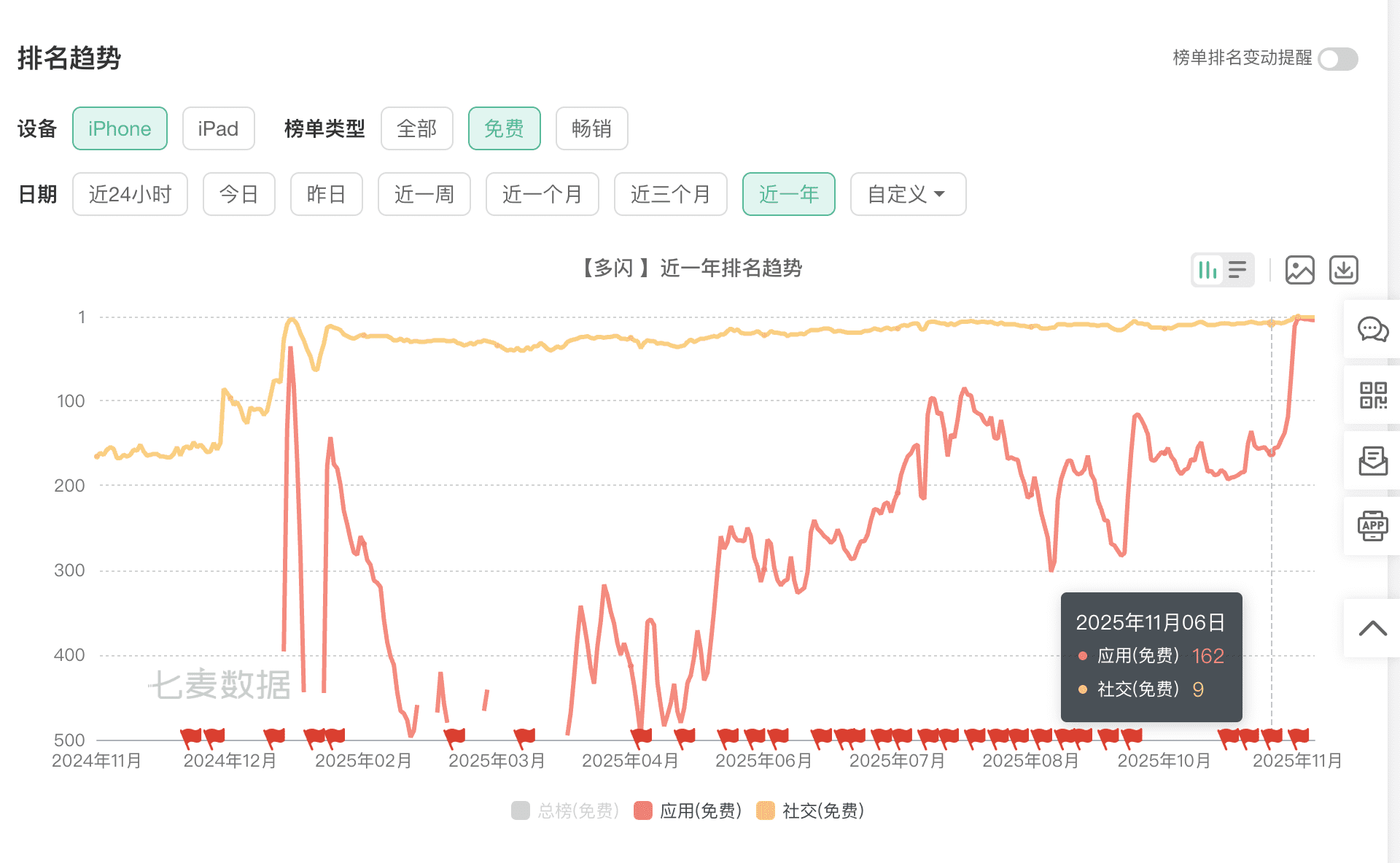
11月的这波「起飞」,看起来始于11月11日左右,从第162名一路直升到第五名左右。这种突然的排名飙升,暗示着背后可能有字节跳动的大力推动。
2. 产品功能的演变
回溯到2019年,多闪主打"视频社交",张一鸣曾在字节跳动七周年庆典上为其站台,称对多闪的预期是"不断想办法突破"。那时的多闪,试图用"随拍"、"72小时消失"等Snapchat式的玩法,去挑战微信沉重的社交压力。
但现实是残酷的,随着补贴退潮,多闪下载量曾经历断崖式下跌。而后多闪经历过三次大的改版:2022年探索相机社交,2023年重新定位为"抖音聊天官方应用"。去年12月坊间一度传出其已停止研发、仅保持维护的消息,且iOS端曾近一年未更新。
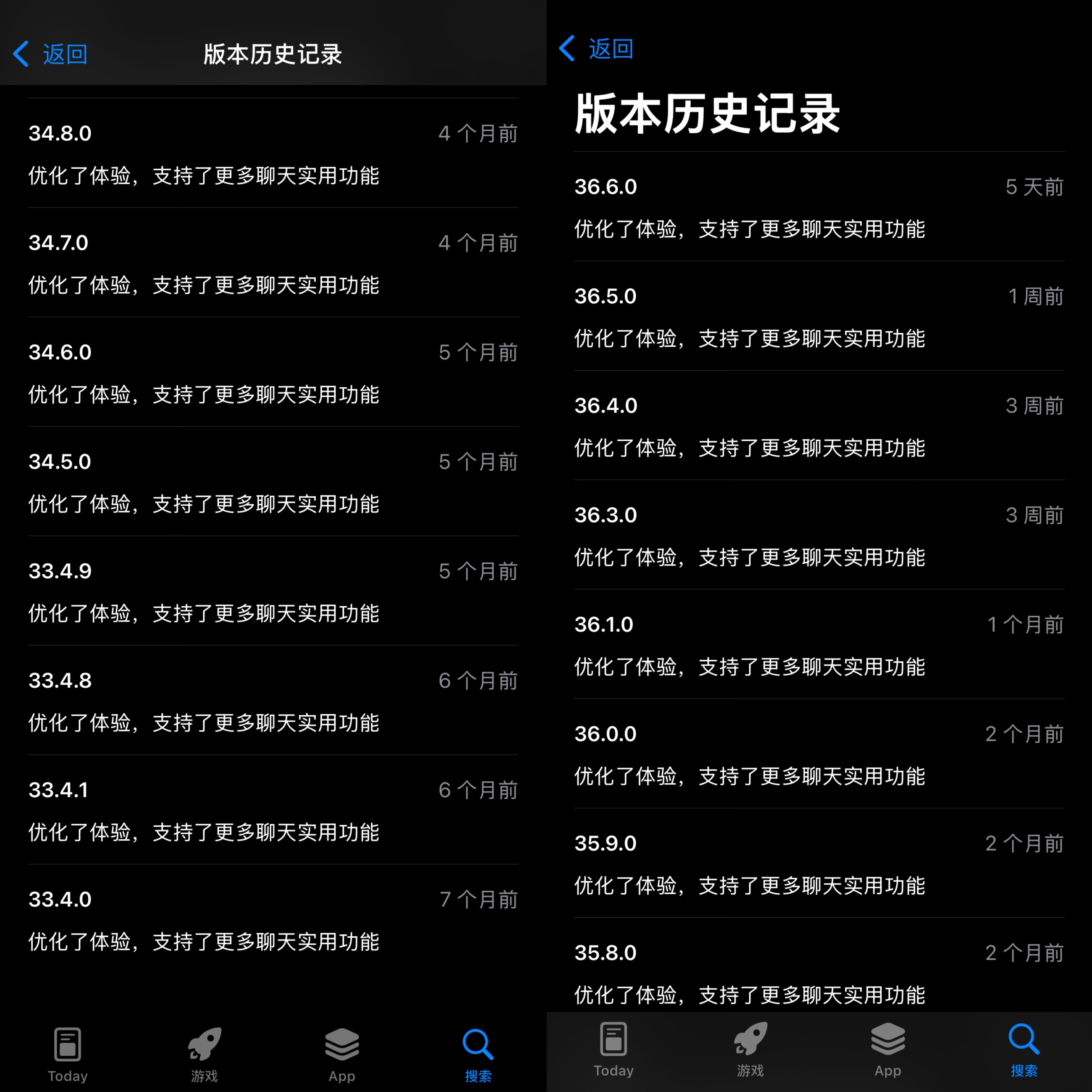
但从7个月前,多闪已悄然恢复了每月小幅优化的节奏,这一个月以来更是密集优化了5次。就在5天前,多闪又更新了36.6.0版本,重点补齐了更多聊天实用功能,越来越像一个"抖音版微信"。
从"几近消失"到重回榜首,应该是抖音在幕后重新发力,将多闪推向了前台。这种变化或许折射出了字节跳动社交思路的变化:不再试图凭空造一个新社交网络,而是承认抖音才是真正的流量黑洞,多闪必须依附于抖音存在。
目前的"多闪",更像是一个被剥离了短视频广场、专注于即时通讯的"配套工具"。它老老实实地做抖音生态的"Messenger",不再寻求成为年轻人的"Snapchat"。
但这种"降级"反而让它在抖音庞大的用户基数下找到了生存空间——只要抖音用户有聊天需求,多闪就有存在的价值。
二、多闪"复活"的战略意义
如果仅仅是为了聊天,抖音内置的私信功能似乎已经足够。为何字节跳动还要死磕"多闪"这个独立App?答案或许藏在抖音急剧扩张的商业版图中。
1. 弥补私域流量短板
近年来,抖音在本地生活和电商业务上攻城略地,但在私域流量的沉淀上始终是短板。互联网进入存量博弈阶段,单纯的社区内容消费与人际社交关系链有着本质区别。
微信之所以难以撼动,是因为它掌握了核心关系链。多闪的「复活」或许可以跟字节跳动最新的一则组织架构调整联动来看。11月17日,有报道称字节跳动将中国电商、生活服务、中国广告的技术团队深度整合,正式成立"中国交易与广告"部门,由原抖音生活服务技术负责人王奉坤挂帅。
这意味着,在字节的战略棋盘中,广告流量与交易场景(电商、本地生活)将被彻底打通。
2. 多闪在新架构下的可能角色
在这个新的"交易+广告"庞大架构下,多闪也许能发挥的作用是:
- 私域沉淀:商家需要一个更纯粹的场域来维护客户关系,而不是在充斥着短视频流的抖音主App里;
- 弥补算法缺陷:社交推荐能有效弥补算法推荐的弊端,增加用户粘性。
多闪的任务可能已经从"进攻"转为"防守"。它不需要打败微信,只需要作为抖音生态的一个"后花园",接住那些在抖音上产生的社交关系火花,防止它们流失到微信中去。
3. 字节跳动社交战略的演变
字节对社交的执念应该永远也不会消失。除了「复活」的多闪,猫箱则是字节flow部门推出的AI社交产品,主打人与虚拟角色的互动,提供一种"伴聊"的情绪价值,刚推出的时候活跃度很高,但随着国内产品在9月迎来了一波停服潮,曾经是头部产品的「猫箱」相较巅峰时期下载量已跌去9成以上。
从2019年的高调宣战,到如今的低调霸榜,多闪的浮沉录也是字节跳动产品哲学的进化史。它更加务实地服务于超级APP的生态需求,而不是像过去一样盲目追求颠覆。
三、多闪的未来:社交战争的新格局
多闪有没有"死"并不重要,重要的是打败微信的绝不会是另一个微信。这场关于社交的战争,或许并未结束,只是进入了新的阶段。
1. 社交产品的差异化竞争
在当前的互联网环境下,纯粹的社交产品已经很难突破微信的壁垒。多闪的转型表明,未来的社交产品可能需要更加垂直、更加场景化,或者依附于某个强大的生态体系。
抖音生态中的多闪,正是这种思路的体现。它不试图成为独立的社交平台,而是专注于解决抖音用户在特定场景下的沟通需求。
2. AI技术对社交的重构
随着AI技术的发展,社交产品也在迎来新的变革。字节跳动在AI领域的布局已经初见成效,豆包等AI产品的成功,为字节跳动在社交领域注入了新的可能性。
未来,多闪可能会融入更多的AI元素,例如智能聊天助手、个性化推荐等,从而提升用户体验,增强产品竞争力。
3. 商业价值的挖掘
对于字节跳动而言,多闪的价值不仅在于用户数量,更在于它能够为整个生态系统带来的商业价值。通过多闪,字节跳动可以更好地连接用户与商家,促进电商和本地生活业务的发展。
在"交易+广告"的新架构下,多闪有望成为连接内容、社交和商业的重要纽带,为字节跳动创造更多的变现机会。
结语
多闪的"回春",不仅仅是一款产品的重生,更是字节跳动在存量互联网时代的一次战略调整。它告诉我们,在竞争激烈的互联网市场中,有时候"退一步"反而能找到更广阔的发展空间。
从挑战微信到成为抖音的"影子",多闪的转变反映了中国互联网行业的发展趋势——从追求颠覆式创新,到更加务实的生态构建。未来,随着技术的进步和用户需求的变化,社交产品还将继续演变,但核心逻辑始终不变:为用户提供价值,为商业创造可能。
多闪的故事或许才刚刚开始,在字节跳动的战略棋盘上,它将扮演怎样的角色,值得我们继续关注。








